python数据结构与算法 (翻译)第一章
第一章 抽象数据类型
算法的学习是计算机科学的基础。算法是为了在有限的时间内解决问题,而做出的一系列清晰和精确的逐步说明。算法通过将逐步指令转换成可由计算机执行的计算机程序来实现。这个翻译过程被称为计算机编程或简单编程。计算机程序由适合于该问题的编程语言来构建。编程是计算机科学重要的组成部分。计算机科学不是学习编程,也不是学习一种特定的编程语言,相反,编程和程序语言都是计算机科学用来解决问题的工具。
1.1 介绍
数据项在计算机内被表示为二进制数字序列。由于计算机可以存储和处理不同类型的数据,因此这些序列看起来可能非常相似,但却又不同的含义。例如,二进制序列01001100110010110101110011011100可以是字符串,整数值或实数值。为了区分不同类型的数据,术语类型通常用来指代值的集合,术语数据类型是指给定的类型以及用于操作给定类型的值的操作集合。
编程语言通常提供数据类型作为语言本身的一部分。这些被称为基元的数据类型分为两类:简单的和复杂的。简单的数据类型由最基本的形式组成,不能分解成更小的部分。例如,整数和实数类型由单个数字值组成。另一方面,复杂的数据类型是由多个简单类型或其他复杂类型组成构成的。在Python中,可以包含多个值的对象,比如字符串,列表和字典等,都是复杂类型的示例。一种语言提供的原始类型可能不足以解决大的复杂问题。因此,大多数语言允许构建额外的数据类型,称为用户定义类型,因为它们是由程序员定义的,而不是由语言定义的。其中一些数据类型本身可能非常复杂。
1.1.1 抽象
计算机科学家通常使用抽象,来帮助管理复杂的问题和复杂的数据类型。抽象是一种分离对象属性并将焦点限制在当前上下文相关的机制。 抽象的用户不需要了解所有的细节以便利用该对象,而只需要了解与当前任务或问题相关的细节。
在计算机科学中遇到的两种常见类型的抽象是程序性或功能性的抽象以及数据抽象。程序抽象是使用函数或方法——你知道它做什么而忽略它是如何完成的。考虑一下你可能使用的数学平方根函数。你知道函数将计算给定数字的平方根,但是你知道平方根是如何计算的吗? 你知道如何计算,或者只是知道如何正确地使用这个函数重要吗? 数据抽象是将数据类型的属性(其值和操作)与该数据类型的实现分离。您在Python中多次使用过字符串。 但是你知道他们是如何实现的吗? 也就是说,您是否知道数据是如何在内部构建以及各种操作是如何实现的?
通常情况下,复杂问题的抽象在层中出现,每个更高层比之前更加抽象。考虑在计算机上表示整数值并对这些值执行算术运算的问题。图1.1说明了用于整数运算的常见抽象级别。最底层的硬件,很少或没有抽象,因为它包括用于执行算术的值和逻辑电路的二进制表示。硬件设计人员会在这个级别处理整数运算,并关心其正确的实现。整数值和算术的抽象层次通过汇编语言提供,涉及使用与底层硬件相对应的二进制值和单独指令。编译器编写器和汇编语言程序员可以在此级别使用整数算术,并且必须确保正确选择汇编语言指令来计算给定的数学表达式。例如,假设我们希望计算x = a + b-5。在汇编语言级别,这个表达式必须被拆分成多条指令,用于从内存中加载值,将它们存储到寄存器中,然后分别执行每个算术运算,如下面的伪代码所示:
loadFromMem( R1, ‘a’ )
loadFromMem( R2, ‘b’ )
add R0, R1, R2
sub R0, R0, 5
为了避免这种复杂性,高级编程语言在汇编语言级别之上增加了另一层抽象层。这个抽象是通过一个原始数据类型提供,用来存储整数值和一组对这些值执行的定义良好的操作。通过提供这种抽象级别,程序员可以使用存储的十进制值变量,并可以使用比汇编语言指令更熟悉的符号(x = a + b-5)来指定数学表达式。因此,程序员在计算机程序中使用整数算术时不需要知道评估数学表达式所需的汇编语言指令或理解其硬件实现。

大多数高级语言和计算机硬件提供的整数运算具有一个问题,即它的值是有限大小的。例如,在32位体系结构的计算机上,有符号整数值被限制在-2^31 …(2^31 -1)的范围内。 如果我们需要更大的价值呢? 在这种情况下,我们可以在软件中提供长或“大整数”来实现无限大小的值。这将涉及到存储单独的数字以及实现各种算术运算的功能或方法。操作的实现将使用由高级语言提供的原始数据类型和指令。提供大整数实现的软件库可用于大多数常用编程语言。然而,Python实际上提供了软件实现的大整数作为语言本身的一部分。
1.1.2 抽象数据类型
抽象数据类型(或ADT)是一种程序员定义的数据类型,它指定一组数据值和一组可以在这些值上执行的定义良好的操作。抽象数据类型的定义与其实现相互独立,这使我们能够专注于新的数据类型的使用,而不是如何实现。这种分离通常是通过接口或定义的一组操作与抽象数据类型进行交互来实现的。这被称为信息隐藏。通过隐藏实现细节并要求通过接口访问ADT,我们可以使用抽象,并专注于ADT提供的功能,而不是如何实现该功能。
如图1.2所示,抽象的数据类型可以像黑盒子一样被查看。 用户程序通过调用其接口定义的几个操作之一与ADT的实例进行交互。这组操作可以分为四类:
- 构造函数:创建并初始化ADT的新实例
- 访问者:返回实例中包含的数据而不修改它。
- 存取器:修改ADT实例的内容。
- 迭代器:按顺序处理各个数据组件。

各种操作的执行都隐藏在黑盒子里面,我们仅仅使用ADT,不必知道其中的内容 。处理抽象数据类型有几个好处并且它聚焦于“what”而不是“how。 - 我们可以专注于解决手头的问题,而不是陷入实施细节。 例如,假设我们需要从磁盘上的一个文件中提取一个值的集合,并将它们存储起来,以便以后在我们的程序中使用。 如果我们把注意力放在实现细节上,那么我们不得不担心使用什么类型的存储结构,应该如何使用,以及它是否是最有效的选择。
- 我们可以通过阻止直接访问一个实现来减少由于意外滥用存储结构和数据类型而可能发生的逻辑错误。如果我们在前面的例子中使用了一个列表来存储值的集合,那么就有可能在代码的一部分中意外地修改它的内容。这种类型的逻辑错误可能很难追查到。通过使用ADT并要求通过接口访问,我们有更少的接入点进行调试。
- 抽象数据类型的实现可以改变,而不必修改使用ADT的程序代码。有很多时候,我们发现ADT的初始实现并不是最有效的,或者我们需要以不同的方式组织数据。假设我们对存储一组值的前一个问题的初始方法是简单地将新值附加到列表的末尾。如果我们以后决定这些项目应该按照不同的顺序安排,而不是简单地将它们追加到最后。如果我们直接访问列表,那么我们将不得不在每个添加值的地方修改我们的代码,并确保它们不会在其他地方重新排列。通过要求必须通过接口访问,我们可以轻松地将“黑盒子”换成新的实现,而不会影响使用ADT的代码段。
- 管理更大的程序并将其分成更小的模块更容易,这将允许团队中的不同成员在单独的模块上工作。大型编程项目通常由程序员团队开发,其中工作量被划分给所有成员。通过与ADT合作并就其定义达成一致,团队可以更好地确保各个模块在所有部分合并时一起工作。使用我们之前的例子,如果团队的每个成员直接访问存储值集合的列表,他们可能会以不同的方式无意中组织数据,或者以某种意外的方式修改列表。当各种模块组合在一起时,结果可能是不可预测的。
1.1.3 数据结构
使用将定义与实现分开的抽象数据类型,有利于解决问题和编写程序。 然而,在某些时候,我们必须提供一个具体的实施方案来执行该计划。 在Python语言库中提供的ADT由库的维护者实现。 在定义和创建自己的抽象数据类型时,最终必须提供一个实现。 您在实施ADT时所做的选择会影响其功能和效率。
抽象数据类型可以简单或复杂。一个简单的ADT由单个或多个单独命名的数据字段组成,例如用于表示日期或有理数的字段。复杂的ADT由诸如Python列表或字典之类的数据值集合组成。复杂的抽象数据类型是使用特定的数据结构实现的,这是数据如何组织和操纵的物理表示。数据结构可以通过它们如何存储和组织单个数据元素和哪些操作可用于访问和操纵数据来区别开来。
有许多常见的数据结构,包括数组,链表,堆栈,队列和树,等等。所有的数据结构都存储一组值,但是组织各个数据项的方式,以及可以采用哪些操作来管理集合都不尽相同。特定数据结构的选择取决于ADT和手头的问题。 一些数据结构更适合于特定的问题。例如,队列结构非常适合实现打印机队列,而B-Tree是数据库索引的更好选择。无论我们使用哪种数据结构来实现ADT,通过将实现与定义分离,我们可以在程序中使用抽象数据类型,然后根据需要更改为不同的实现,而无需修改现有的代码。
1.1.4 一般定义
计算机科学中使用了许多不同的术语。其中的一些可以在各种教科书和编程语言中有不同的含义。为了帮助读者并避免混淆,我们定义了一些我们将在整个案文中使用的常用术语。
一个集合是一组没有任何隐含的组织或关系的值。有时我们可能会将元素限制为特定的数据类型,如整数集合或浮点值。
一个容器是存储和组织集合的任何数据结构或抽象数据类型。集合的各个值被称为容器的元素,而没有元素的容器被认为是空的。一个容器和另一个容器的元素的组织或排列可以不同,只要可以通过操作访问元素。Python提供了许多内置的容器,包括字符串,元组,列表,字典和集合。
一个序列是一个容器,其中元素从前到后以线性顺序排列,每个元素可以按位置访问。在整本书中,我们假定基于它们在线性顺序内的位置,使用下标运算符来访问各个元素。 Python提供了两个不可变的序列,字符串和元组,以及一个可变序列,即列表。在下一章中,我们将介绍数组结构,这也是一个常用的可变序列。
排序序列是元素的位置基于每个元素与其后继者之间的规定关系。例如,我们可以创建一个排序的整数序列,其中元素按照从小到大的顺序从小到大排列。
在计算机科学中,术语列表通常用于指代具有线性排序的任何集合。 排序是这样的:除了第一个元素之外,集合中的每个元素都有一个唯一的前驱,除最后一个元素外,每个元素都有唯一的后继。 通过这个定义,一个序列是一个列表,但是一个列表不一定是一个序列,因为不要求列表提供按位置访问元素。不幸的是,Python为其内置的可变序列类型使用了相同的名称,在其他语言中,它将被称为数组列表或向量抽象数据类型。为避免混淆,我们将使用术语“列表”来引用由Python提供的数据类型,并在引用前面定义的更一般的列表结构时使用术语“通用列表”或“列表结构”。
1.2 日期抽象数据类型
抽象数据类型是通过指定组成ADT的数据元素的域和可以在该域上执行的操作集来定义的。该定义应该提供ADT的明确描述,包括其范围和每个操作,因为只有那些指定的操作可以在ADT实例上执行。接下来,我们提供了一个简单的抽象数据类型的定义,用于在预测的公历日历中表示一个日期。
1.2.1 定义ADT
格里高利十三世在公元1582年引入了公历,以取代儒略历。新的历法对误计正月进行了修正,并引入了闰年。公历的第一天是公元1582年10月15日星期五。公历前的公历是公元前4713年11月24日的第一个日期的延续和融合。这个扩展简化了日期在日历中的处理,它的使用可以在许多软件应用程序中找到。
定义 日期DAT
公历的日期代表独立的一天,这里第一天从公元前4713年11月24日开始。
- Date(month, day, year): 创建一个新的Date实例,初始化为给定的公历日期,必须有效。 公元前1年及以前由负年份组成。
- day(): 返回此日期的公历日期。
- month(): 返回此日期的公历月份。
- year(): 返回此日期的公历年份。
- monthName(): 返回此日期的公历月份名称。
- dayOfWeek(): 返回星期为0和6之间的数,0代表星期一,6代表星期天。
- numDays(otherDate): 返回此日期与otherDate之间的正整数的天数。
- isLeapYear(): 确定此日期是否在闰年,并返回适当的布尔值。
- advanceBy(days): 将日期提前给定的天数。如果天数为正数,则日期递增,如果天数为负,则递减日期。如有必要,将期限制在公元前4714年11月24日。
- comparable(otherDate): 将这个日期与其他日期进行比较以确定它们的逻辑顺序。 这个比较可以使用任何逻辑运算符<,<=,>,> =,==,!=来完成。
- toString(): 以mm / dd / yyyy格式返回表示公历日期的字符串。通过str()构造函数自动调用的Python运算符实现。
文本中定义的抽象数据类型将作为Python类实现。在定义ADT时,我们将ADT操作指定为方法原型。用于创建ADT实例的类构造函数由实现中使用的类的名称指定。 Python允许类定义或重载可以在程序中更自然地使用的各种运算符,而不必按名称调用方法。我们将所有ADT操作定义为命名方法,但是在适当的时候将其中的一些操作符实现为运算符,而不是使用命名方法。将以Python操作符实现的ADT操作用斜体表示,并在ADT定义中给出相应操作符的简短评论。这种方法使我们能够专注于一般的ADT规范,如果需要的话可以很容易地转换成其他语言,但是也允许我们在各种示例程序中利用Python的简单语法。
1.2.2 使用ADT
为了说明日期ADT的使用,请思考清单1.1中的程序,该程序处理一系列出生日期。日期从标准输入中提取并检查。根据目标,日期显示个体年龄至少为21岁的日期将打印到标准输出。不断提示用户输入出生日期,直到在月份输入零。 这个简单的例子说明了通过关注ADT提供什么功能而不是如何实现这个功能来处理抽象的优点。 通过隐藏实现细节,我们可以使用独立于其实现的ADT。实际上,日期ADT的实现选择对我们的示例程序中的指令没有任何影响。
类的定义:类是面向对象编程语言的基础,它们为定义和实现抽象数据类型提供了一个方便的机制。 附录D提供了对Python类的回顾。
清单1.1请见GitHub
1.2.3 先决条件和后置条件
在确定操作时,我们必须包括所需要的输入和结果输出的说明(如果有的话)。另外,我们必须指定每个操作的先决条件和后置条件。前提条件表示在执行操作之前,ADT实例和输入的条件或状态。后置条件表示执行操作之后的ADT实例的结果或结束状态。前提条件是假定的,而后置条件是一个保证,只要前提条件得到满足。试图执行不满足前提条件的操作应该被错误地忽略。考虑使用pop(i)方法从列表中删除值。当这个方法被调用时,前提条件表明提供的索引必须在合法范围内。在成功完成操作后,后续条件保证项目已经从列表中删除。如果一个无效的索引(超出合法范围的索引)传递给pop()方法,则会引发异常。
所有的操作都至少有一个先决条件,即ADT实例必须先被初始化。在面向对象的语言中,这个前提条件是自动验证的,因为在使用任何操作之前,必须通过构造函数创建和初始化对象。除初始化要求外,操作可能没有任何其他先决条件。这一切都取决于ADT的类型和相应的操作。 同样,一些操作可能没有后置条件,就像简单的访问方法一样,它只是返回一个值而不修改ADT实例本身。在整个文章中,我们没有明确说明前提条件和后置条件,但它们很容易从ADT操作的描述中识别出来。
在实现抽象数据类型时,通过验证任何陈述的先决条件来确保各种操作的正确执行是非常重要的。 测试抽象数据类型的先决条件时,适当的机制是测试前提条件,并在前提条件失败时引发异常。 然后,您可以让ADT的用户决定他们希望如何处理错误,或者抓住它,或者让程序中止。
Python和许多其他面向对象的编程语言一样,在发生错误时引发异常。异常是一个事件,可以在程序执行过程中触发并可选择处理。当引发异常时,程序可以包含代码来捕捉并优雅地处理异常;否则,程序将中止。Python也提供了assert语句,可以用来引发一个AssertionError异常。assert声明用于说明我们在程序中给定的位置假设为真。如果断言失败,Python将自动引发一个AssertionError并中止程序,除非异常被捕捉。
在整篇文章中,我们使用assert语句来测试实现抽象数据类型时的先决条件。这使我们能够专注于ADT的实施,而不必花费时间为了使用我们的ADT而选择适当的异常来提高或产生新的异常。有关异常和断言的更多信息,请参阅附录C.
1.2.4 ADT的实现
在定义ADT之后,我们需要用适当的语言来提供一个实现。在我们的例子中,我们总是使用Python和类的定义,但是任何编程语言都可以使用。清单1.2中提供了Date类的分离实现,并将一些方法的实现留作练习。
日期表示
在对象中存储日期有两种常见的方法。 一种方法将三个组件 - 月,日和年 - 存储为三个独立的字段。使用这种格式,可以很容易地访问各个组件,但是很难比较两个日期或者计算两个日期之间的天数,因为一个月中的天数是变化的。第二种方法将日期存储为代表Julian日的整数值,Julian日是从公元前4713年11月24日(使用公历日期表示法)开始日期起经过的天数。给定一个Julian天数,我们可以计算三个格里高利分量中的任何一个,并简单地减去这两个整数值,以确定谁先发生或者两个日期之间差多少天。我们将使用后一种方法,因为它在计算机应用程序中被用来存储日期更普遍,并提供了一个简单的实现。
代码清单1.2 *date.py模块的部分实现*
1 # Implements a proleptic Gregorian calendar date as a Julian day number.
2
3 class Date :
4 # Creates an object instance for the specified Gregorian date.
5 def __init__( self, month, day, year ):
6 self._julianDay = 0
7 assert self._isValidGregorian( month, day, year ), \
8 "Invalid Gregorian date."
9
10 # The first line of the equation, T = (M - 14) / 12, has to be changed
11 # since Python's implementation of integer division is not the same
12 # as the mathematical definition.
13 tmp = 0
14 if month < 3 :
15 tmp = -1
16 self._julianDay = day - 32075 + \
17 (1461 * (year + 4800 + tmp) // 4) + \
18 (367 * (month - 2 - tmp * 12) // 12) - \
19 (3 * ((year + 4900 + tmp) // 100) // 4)
20
21 # Extracts the appropriate Gregorian date component. 22 def month( self ):
23 return (self._toGregorian())[0] # returning M from (M, d, y)
24
25 def day( self ):
26 return (self._toGregorian())[1] # returning D from (m, D, y)
27
28 def year( self ):
29 return (self._toGregorian())[2] # returning Y from (m, d, Y)
30
31 # Returns day of the week as an int between 0 (Mon) and 6 (Sun).
32 def dayOfWeek( self ):
33 month, day, year = self._toGregorian()
34 if month < 3 :
35 month = month + 12
36 year = year - 1
37 return ((13 * month + 3) // 5 + day + \
38 year + year // 4 - year // 100 + year // 400) % 7
39
40 # Returns the date as a string in Gregorian format.
41 def __str__( self ):
42 month, day, year = self._toGregorian()
43 return "%02d/%02d/%04d" % (month, day, year)
44
45 # Logically compares the two dates.
46 def __eq__( self, otherDate ):
47 return self._julianDay == otherDate._julianDay
48
49 def __lt__( self, otherDate ):
50 return self._julianDay < otherDate._julianDay
51 5
2 def __le__( self, otherDate ):
53 return self._julianDay <= otherDate._julianDay
54
55 # The remaining methods are to be included at this point.
56 # ......
57
58 # Returns the Gregorian date as a tuple: (month, day, year).
59 def _toGregorian( self ):
60 A = self._julianDay + 68569
61 B = 4 * A // 146097
62 A = A - (146097 * B + 3) // 4
63 year = 4000 * (A + 1) // 1461001
64 A = A - (1461 * year // 4) + 31
65 month = 80 * A // 2447
66 day = A - (2447 * month // 80)
67 A = month // 11
68 month = month + 2 - (12 * A)
69 year = 100 * (B - 49) + year + A
70 return month, day, year构建日期
我们用构造函数来开始讨论实现,如代码清单1.2的5-19行所示。日期ADT将只需要一个属性来存储代表给定格里高利日期的Julian日。为了将公历日期转换为Julian天数,我们使用下面的公式1,其中天0对应于公元前4713年11月24日,并且所有的操作涉及整数算术。
T = (M - 14) / 12
jday = D - 32075 + (1461 * (Y + 4800 + T) / 4)
+ (367 * (M - 2 - T * 12) / 12)
+ (3 * ((Y + 4900 + T) / 100) / 4)
在尝试将公历日期转换为儒略日之前,我们需要验证这是一个有效的日期。这是必要的,因为前提条件表明提供的公历日期必须是有效的。 辅助方法isValidGregorian()用于验证给定公历日期的有效性。这个辅助方法(实现留作练习)测试提供的公历日期组件,并返回适当的布尔值。如果将有效日期提供给构造函数,则使用前面提供的公式将其转换为相应的Julian日。注意第13-15行的陈述。将公历日期转换为Julian日数的公式使用整数运算,但是由于其执行整数除法,公式线T =(M-14)/ 12在Python中产生不正确的结果,这与数学定义不同。按照定义,整数除-11/12的结果是0,但Python将其计算为b-11 / 12.0c,结果为-1。因此,当月份分量大于2时,我们不得不修改方程的第一行来产生正确的Julian日。
注意 应该适当地为类定义和方法注释,以帮助用户了解什么是类和/或方法。 然而,为了节省空间,本书中介绍的类和方法并不经常包含这些评论,因为周围的文本提供了完整的解释。
受保护的属性和方法 Python不提供禁止在类定义之外使用的保护属性和帮助方法。在本文中,我们使用标识符名称,这些名称以单个下划线开头,标出应该被认为受保护的属性和方法,依赖类的用户不要尝试直接访问。
公历日期
要访问公历日期组件,Julian日必须被转换回格里高利。在几个ADT操作中需要这种转换。每次需要时,我们都不需要重复公式,而是创建一个辅助方法来处理转换,如清单1.2的第59-70行所示。
第32-38行显示的dayOfWeek()方法也使用辅助方法toGregorian()转换。我们使用一个简单的公式,根据公历元素确定星期几,其中0表示星期一,1表示星期二,依此类推。
由ADT定义的toString操作是通过重载Python的str方法在第41-43行中实现的。它以格里高利格式创建日期的字符串表示形式。这样可以使用一个字符串来形式化,以提供从转换辅助方法返回的值。通过使用Python的str方法,当您尝试打印或将对象转换为字符串时,Python会在对象上自动调用此方法,如下例所示:
firstDay = Date( 9, 1, 2006 )
print( firstDay )
比较日期对象
我们可以在逻辑上比较两个Date实例来确定他们的日历顺序。当使用Julian日来表示日期时,日期比较就像比较两个整数值一样简单,并根据比较结果返回适当的布尔值。清单1.2中的第46-53行显示了使用Python的逻辑比较运算符来实现“可比的”ADT操作。通过实施逻辑比较运算符的方法,类的实例变成可比较的对象。也就是说,这些对象可以相互比较产生一个逻辑顺序。
你会注意到我们只实现了三个逻辑比较运算符。原因是,从Python版本3开始,Python将自动交换操作数,并在必要时调用适当的反射方法。例如,如果我们在程序中使用带有Date对象的表达式a> b,则Python将自动交换操作数并调用b< a,因为lt方法是定义的,而不是gt。它会为> = b和a <= b做同样的事情。 当测试相等性时,当只有一个相等运算符(==或!=)被定义时,Python会自动反转结果。 因此,我们只需要从以下每对中定义一个运算符来实现全部的逻辑比较:<或>,<=或> =和==或!=。 有关重载操作符的更多信息,请参阅附录D.
重载操作符用户定义的类可以实现重新定义许多标准Python运算符(如+,,%和==)的方法,以及标准的命名运算符(如in和not)。这样可以更自然地使用对象,而不必调用特定的命名方法。对每个你创建的类定义操作符是很有诱惑力的,但是你应该限制操作符方法的定义,以便特定的操作符具有有意义的目的。*
1.3 包
日期ADT提供了一个简单的抽象数据类型的例子。为了说明复杂抽象数据类型的设计和实现,我们定义了包ADT。一个包是一个简单的容器,像一个购物袋,可以用来存储一系列物品。包容器通过仅限定用于添加和移除单个物品的操作,来限制对单个物品的访问,是用来确定物品是否在袋子中以及用于遍历物品的集合。
1.3.1 包抽象数据类型
袋ADT有几个变种,这里描述的是一个简单的包。一个抓包(?)类似于简单的包,但随机将物品从包中取出。 另一个常见的变化是计数袋,其中包括一个操作,返回袋子中给定元素的个数。 抓包和计数袋的实施留作练习。
定义 包ADT
一个包是一个容器,它存储一个允许重复值的集合。这些元素,每个都是单独存储的,没有特定的顺序,但它们必须具有可比性。
- Bag(): 创建初始为空的包。
- length(): 返回包中存储的项目数量。使用len()函数访问。
- contains(item):确定给定的目标项是否存储在包中,并返回相应的布尔值。使用in运算符访问。
- add(item): 将给定项添加到包里。
- remove(item):移除并返回包中该元素。如果元素不在包中,则会引发异常。
- iterator(): 创建并返回可用于迭代集合元素的迭代器。
您可能已经注意到我们对Bag ADT的定义不包括将容器转换为字符串的操作。我们可以包括这样一个操作,但是为大集合创建一个字符串是耗时的,并且需要大量的内存。在调试使用Bag ADT实例的程序时,这样的操作可能是有益的。因此,为了调试的目的,包含str操作符方法并不罕见,但通常不会在生产软件中使用。在我们的抽象数据类型的定义中,除非有意义,通常会省略一个str操作符方法,也许您可能需要暂时包含一个用来调试的方法。
用例
鉴于包 ADT的抽象定义,我们可以创建并使用一个包,而不知道它是如何实现的。考虑下面这个简单的例子,它会创建一个包,并要求用户猜测它包含的值之一。
myBag = Bag()
myBag.add( 19 )
myBag.add( 74 )
myBag.add( 23 )
myBag.add( 19 )
myBag.add( 12 )
value = int( input("Guess a value contained in the bag.") )
if value in myBag:
print( "The bag contains the value", value )
else :
print( "The bag does not contain the value", value )
接下来,考虑上一节中的checkdates.py示例程序,我们从用户提取出生日期,并确定哪些是至少21岁的个人。假设我们要保留出生日期的集合供以后使用。要求用户多次重新输入日期是没有意义的。相反,我们可以将出生日期存储在输入的包中,随后可以根据需要多次访问它们。当一个特定项目的位置或顺序无关紧要时,包ADT是一个用于存储对象的完美的容器。 以下是代码1.1中出生日期检查程序的主程序的新版本:
#pgm: checkdates2.py (modified main()
from checkdates.py)
from linearbag
import Bag from date
import Date
def main():
bornBefore = Date( 6, 1, 1988 )
bag = Bag()
# Extract dates from the user and place them in the
bag. date = promptAndExtractDate()
while date is not None :
bag.add( date )
# Iterate over the bag and check the age.
for date in bag :
if date <= bornBefore :
print( "Is at least 21 years of age: ", date )
为什么用包ADT
您可能想知道,为什么我们需要Bag ADT,为什么不可以简单地使用列表来存储项目?对于一个小程序和一个小的数据集合,使用列表将是适当的。但是,在处理大型程序和多个团队成员时,抽象数据类型提供了几个优点,如前面1.1.2节所述。通过使用一个包的抽象,我们可以:a)专注于解决手头的问题,而不是担心容器的实现; b)减少由于滥用清单而导致错误的可能性,因为它提供了额外的操作 不适合一个包,c)提供不同模块和设计人员之间的更好的协调,以及d)稍后可以更容易地将我们当前的包ADT的实现换成不同的,可能更有效的版本。
1.3.2 选择一个数据结构
实现复杂的抽象数据类型通常需要使用数据结构来组织和管理数据项的集合。 有许多不同的结构可供选择。 那么我们如何知道使用哪个? 我们必须评估数据结构是否适合实现给定的抽象数据类型,我们基于以下标准:
- 数据结构是否提供ADT域指定的存储需求? 抽象数据类型和被定义为与数据值的特定域一起工作。我们选择的数据结构必须能够在该域中存储所有可能的值,同时考虑到对各个元素的限制或限制。
- 数据结构是否提供了必要的数据访问和操作功能来完全实现ADT? 抽象数据类型的功能是通过定义的一组操作来提供的。 数据结构必须允许完整和正确地实现ADT,而不必通过向用户公开实现细节来违反抽象原则。
- 数据结构是否适合于操作的高效实施?实现抽象数据类型的一个重要目标是提供一个有效的解决方案。一些数据结构能够比其他数据结构更有效的实现,但并不是每个数据结构都适合于实现每个ADT。效率考虑可以帮助从多个候选人中选择最佳的结构。
可能有多个数据结构适合于实现给定的抽象数据类型,但是我们试图根据ADT将被使用的环境来选择最好的可能。为了适应不同的上下文,语言库通常会提供一些ADT的多个实现,允许程序员选择最合适的。遵循这种方法,我们在整个文本中引入了许多抽象数据类型,并在引入新的数据结构时呈现它的多个实现。
一个实现的效率是基于复杂性分析的,这直到后面的第三章才会介绍。因此,在那之前,我们推迟考虑选择一个数据结构时,它的实现效率。同时,我们只考虑基于抽象数据类型的存储和功能需求的数据结构的适用性。
现在我们把注意力转向选择实现包 ADT的数据结构。此时可能的候选人包括列表和字典结构。该列表可以存储任何类型的可比对象,包括重复对象。每个项目都是单独存储的,包括重复项,这意味着对每个单独对象的引用都被存储起来,并且在需要时可以访问。这满足了包 ADT的存储要求,使该清单成为其实施的候选结构。
字典存储键/值对,其中关键组件必须是可比的且唯一的。为了在实现包ADT时使用字典,我们必须有一种方法来根据抽象数据类型的定义来存储重复的项目。为了实现这一点,每个唯一的项目可以存储在键/值对的关键部分中,并且计数器可以存储在值部分中。计数器将用于指示袋中对应物品的出现次数。当添加重复的项目时,计数器递增; 当删除副本时,计数器递减。
列表和字典结构都可以用来实现包ADT。然而,对于简单版本的包来说,列表是一个更好的选择,因为在大多数项目是唯一的情况下,字典将需要两倍的空间来存储包的内容。字典是实现ADT计数袋变化的绝佳选择。
选择列表后,我们必须确保它提供了执行整套包装操作的方法。在实现ADT时,我们必须使用底层数据结构提供的功能。 有时,ADT操作与数据结构已经提供的操作相同。在这种情况下,实现可以非常简单,可以由对结构的相应操作的单个调用组成,而在其他情况下,我们必须使用由结构提供的多个操作。为了帮助验证使用列表正确执行包ADT,我们可以概述如何执行每个包的操作:
- 一个空的包可以用一个空的列表表示
- 包的大小可以根据列表的大小来确定。
- 确定包是否包含特定元素可以使用等价的列表操作完成。
- 当一个新物品被添加到包里时,它可以被追加到列表的最后,因为包里没有特定的顺序。
- 从袋中取出物品也可以通过等同的列表操作来处理。
- 列表中的元素可以使用for循环遍历,而Python提供了与包一起使用的用户定义的迭代器。
从这个列表中,我们看到每个包ADT操作都可以使用列表的可用功能来实现。 因此,该列表适合于执行该包。
1.3.3基于列表的实现
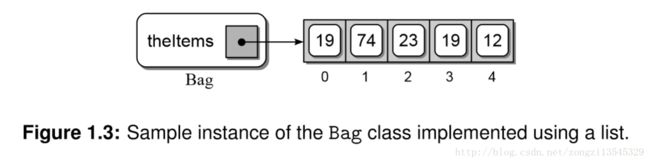
清单1.3显示了使用列表实现包ADT。构造函数定义了一个数据字段,该字段被初始化为一个空列表。这对应于Bag ADT的构造器的定义,其中容器最初是空的。从前面提供的示例checkdates2.py程序创建的Bag类示例如图1.3所示。
清单 1.3 The linearbag.py module
1 # Implements the Bag ADT container using a Python list.
2 class Bag :
3 # Constructs an empty bag.
4 def __init__( self ):
5 self._theItems = list()
6
7 # Returns the number of items in the bag.
8 def __len__( self ):
9 return len( self._theItems )
10
11 # Determines if an item is contained in the bag.
12 def __contains__( self, item ):
13 return item in self._theItems
14
15 # Adds a new item to the bag.
16 def add( self, item ):
17 self._theItems.append( item )
18
19 # Removes and returns an instance of the item from the bag.
20 def remove( self, item ):
21 assert item in self._theItems, "The item must be in the bag."
22 ndx = self._theItems.index( item )
23 return self._theItems.pop( ndx )
24
25 # Returns an iterator for traversing the list of items.
26 def __iter__( self, item ):
27 ......
大部分的实现细节都遵循前一节讨论的细节。还有一些额外的细节。 首先,remove()操作的ADT定义规定了物品必须存在于包中才能被移除的先决条件。因此,我们必须首先断言这个条件并验证这个项目的存在。其次,我们需要提供一个迭代机制,允许我们遍历包中的单个项目。我们推迟这个操作的实现,直到下一节讨论在Python中创建和使用迭代器。
列表存储对象的引用,技术上将如右图所示。 为了节省空间并减少可能因为某些图形导致的混乱,我们将文本中的对象说明为具有圆边的框,并将它们直接显示在列表结构中。变量将被显示为中间有子弹的方框,并在附近打印变量的名称。

1.4 迭代器
遍历是非常常见的操作,特别是在容器上。遍历可以遍历整个集合,提供对每个单独元素的访问。遍历可以用于许多操作,包括搜索特定项目或打印整个集合。
Python的容器类型(字符串,元组,列表和字典)可以使用for循环结构遍历。对于我们的用户定义的抽象数据类型,我们可以添加在必要时执行特定遍历操作的方法。例如,如果我们想将包含在包中的每个项目保存到一个文本文件中,我们可以添加一个saveElements()方法遍历向量并将每个值写入一个文件。但是,这会将结果文本文件的格式限制为新方法中指定的格式。除了保存这些项目之外,也许我们只想以特定的方式将项目打印到屏幕上。为了执行后者,我们将不得不为ADT添加另一个操作。
并不是所有的抽象数据类型都应该提供遍历操作,但是对于大多数容器类型来说都是需要的。因此,我们需要一种允许进行泛型遍历的方法。一种方法是向用户提供对用于实现ADT的底层数据结构的访问。但这会违反抽象原则,并且不能达到定义新的抽象数据类型的目的。
和许多当今的面向对象语言一样,Python提供了一个内置的迭代器结构,可以用来在用户定义的ADT上执行遍历。迭代器是一个对象,它提供了一种通过容器执行泛型遍历的机制,而不必公开底层的实现。迭代器与Python的for循环结构一起使用,为内置和用户定义的容器提供遍历机制。考虑1.3节中checkdates2.py程序的代码段,它使用for循环遍历日期集合。
# Iterate over the bag and check the ages. for date in bag :
if date <= bornBefore :
print( "Is at least 21 years of age: ", date )1.4.1 设计一个迭代器
为了在我们自己的抽象数据类型中使用Python的遍历机制,我们必须定义一个迭代器类,它是Python中的一个类,它包含两个特殊的方法,iter和next。迭代器类通常在与相应的容器类相同的模块中定义。 清单1.4显示了BagIterator类的实现。构造函数定义了两个数据字段。 一个是用于存储包中项目的列表的别名,另一个是循环索引变量,将用于迭代该列表。 循环变量初始化为零,以便从列表的开始处开始。iter方法只是简单的返回一个对象本身的引用,并且总是被这样实现。
*清单1.4 Listing 1.4 The BagIterator class, which is part of the linearbag.py module.
*
1 # An iterator for the Bag ADT implemented as a Python list.
2 class _BagIterator :
3 def __init__( self, theList ):
4 self._bagItems = theList
5 self._curItem = 0
6
7 def __iter__( self ):
8 return self 9 10 def __next__( self ):
11 if self._curItem < len( self._bagItems ) :
12 item = self._bagItems[ self._curItem ]
13 self._curItem += 1
14 return item
15 else :
16 raise StopIteration
下一个方法被调用来返回容器中的下一个项目。该方法首先保存对循环变量指示的当前项目的引用。循环变量然后递增1,为下一次调用下一个方法做好准备。如果没有附加项目,则该方法必须引发一个StopIteration异常,以使for循环终止。最后,我们必须在我们的Bag类中添加一个iter方法,如下所示:
def __iter__( self ):
return _BagIterator( self._theItems )
这个负责创建和返回BagIterator类实例的方法会在for循环的开始处自动调用,以创建一个用于循环结构的迭代器对象。
1.4.2 使用迭代器
随着BagIterator类的定义和对Bag类的修改,我们现在可以使用Python的for循环和Bag实例。
for item in bag :
print( item )
当执行for循环时,Python会自动调用bag对象上的iter方法来创建一个迭代器对象。图1.4说明了刚创建BagIterator对象后的状态。注意迭代器对象的bagItems字段引用了bag对象的Items字段。BagIterator对象创建时,此引用由构造函数分配。

for循环会自动调用迭代器对象上的下一个方法来访问容器中的下一个元素。迭代器对象的状态随着curItem字段增加1而改变。这个过程一直持续到下一个方法产生StopIteration异常时,如curItem所指示的那样元素已经耗尽。在所有的元素都被处理之后,迭代被终止并且执行继续循环之后的下一个语句。下面的代码段说明了当一个for循环与Bag类的实例一起使用时,Python如何实际执行迭代:
# Create a BagIterator object for myBag.
iterator = myBag.__iter__()
# Repeat the while loop until break is called.
while True :
try:
# Get the next item from the bag.If there are no
# more items, the StopIteration exception israised.
item = iterator.__next__()
# Perform the body of the for loop.
print( item )
# Catch the exception and break from the loop when we are done.
except StopIteration:
break1.5 应用:学生记录
大多数计算机应用程序都被编写来处理和处理存储在程序外部的数据。数据通常是从存储在磁盘上的文件,从数据库,甚至从远程站点通过Web服务提取的。例如,假设我们有一组存储在磁盘上的记录,这些记录包含了有关Smalltown College学生的信息。我们已经被分配了任务来提取这些信息并产生一个类似于下面的报告,其中记录按照识别号码排序。

分配任务的注册服务机构的联系人为我们提供了一些有关数据的信息。我们知道每个记录包含五个学生的信息:(1)学生的身份证号码表示为一个整数; (2)他们的姓和名,是字符串; (3)在[1 … 4]范围内的整数分类代码,表示该学生是否是一年级,二年级,三年级,四年级(4)他们的绩点表现为浮点值。但是,我们没有被告知,数据是如何存储在磁盘上的。它可以存储在纯文本文件,二进制文件,甚至数据库中。另外,如果数据存储在文本或二进制文件中,我们将需要知道文件中的数据是如何格式化的,如果数据在关系数据库中,则需要知道数据库的类型和结构。
1.5.1 设计一个解决方案
尽管我们还没有被告知文件的类型或用于存储数据的格式,但是我们可以通过抽象输入源来开始设计和实现解决方案。无论数据的来源或格式如何,从外部存储提取数据记录都需要类似的步骤:打开连接,提取单个记录,然后关闭连接。为了帮助我们的工作,我们定义一个学生文件读取器ADT来表示从外部文件或数据库提取数据。在计算机编程中,用于将数据输入到程序中的对象有时被称为阅读器,而用于输出数据的对象被称为书写器。
定义 学生文件阅读ADT
学生文件阅读器用于从外部存储中提取学生记录。个体记录的五个数据组件被提取并存储在一个专门用于这个学生记录集合的存储对象中。
- StudentFileReader(filename):创建一个学生阅读器实例,用于从给定的文件中提取学生记录。 文件的类型和格式取决于具体的实现。
- open():打开输入源的连接并准备提取学生记录。 如果无法打开连接,则会引发异常。
- close(): 关闭与输入源的连接。 如果连接当前未打开,则会引发异常。
- fetchRecord():从输入源提取下一个学生记录,并返回对包含数据的存储对象的引用。当没有附加记录被提取时没有返回。如果与输入源的连接先前已关闭,则会引发异常。
- fetchAll(): 与fetchRecord()相同,但从输入源中提取所有学生记录(或剩余的),并将其返回到Python列表中
创建报告
清单1.5中的程序使用Student File Reader ADT来生成前面所示的示例报告。程序从输入源提取学生记录,按照学生识别号对记录进行排序,并生成报告。这个程序展示了将抽象应用于解决问题的一些优势,主要关注“what”而不是“how”。
通过使用Student File Reader ADT,我们能够设计一个解决方案,并在不知道数据如何存储在外部源中的情况下为这个问题构建一个程序。我们从studentfile.py模块中导入StudentFileReader类,我们假定它将是处理实际数据提取的ADT的一个实现。进一步说,如果我们想用一个具有不同格式的数据文件来使用这个程序,那么唯一需要修改的变化将会引入进口语句中的不同模块,并且可能会改变常量变量FILE NAME所指定的文件名称。
studentreport.py程序包含两个功能:printReport()和main()。主例程使用ADT实例连接到外部源,以便将学生记录提取到列表中。然后记录列表按照学生识别号码升序排列。实际的报告是通过将已排序的列表传递给printReport()函数来生成的。
清单1.5 The studentreport.py program.
1 # Produces a student report from data extracted from an external source.
2 from studentfile import StudentFileReader
3
4 # Name of the file to open.
5 FILE_NAME = "students.txt"
6
7 def main():
8 # Extract the student records from the given text file.
9 reader = StudentFileReader( FILE_NAME )
10 reader.open()
11 studentList = reader.fetchAll()
12 reader.close()
13
14 # Sort the list by id number. Each object is passed to the lambda
15 # expression which returns the idNum field of the object.
16 studentList.sort( key = lambda rec: rec.idNum )
17
18 # Print the student report.
19 printReport( studentList )
20
21 # Prints the student report.
22 def printReport( theList ):
23 # The class names associated with the class codes.
24 classNames = ( None, "Freshman", "Sophomore", "Junior", "Senior" )
25
26 # Print the header.
27 print( "LIST OF STUDENTS".center(50) )
28 print( "" )
29 print( "%-5s %-25s %-10s %-4s" % ('ID', 'NAME', 'CLASS', 'GPA' ) )
30 print( "%5s %25s %10s %4s" % ('-' * 5, '-' * 25, '-' * 10, '-' * 4))
31 # Print the body.
32 for record in theList :
33 print( "%5d %-25s %-10s %4.2f" % \
34 (record.idNum, \
35 record.lastName + ', ' + record.firstName,
36 classNames[record.classCode], record.gpa) )
37 # Add a footer.
38 print( "-" * 50 )
39 print( "Number of students:", len(theList) )
40
41 # Executes the main routine.
42 main()
存储类
当从输入文件中提取单个学生的数据时,需要将其保存在可添加到列表中的存储对象中,以便首先进行排序然后打印记录。 我们可以使用元组来存储记录,但是我们避免在存储结构化数据时使用元组,因为最好使用带有名称字段的类。 因此,我们定义StudentRecord类来存储与个别学生相关的数据。
class StudentRecord :
def __init__( self ):
self.idNum = 0
self.firstName = None
self.lastName = None
self.classCode = 0
self.gpa = 0.0
您可能会注意到只有一个构造函数没有其他方法。 这是一个定义完整的类,代表一个存储类。 构造函数是定义存储两个分量值的两个数据字段所需要的。
存储类应该在与它们将要使用的类相同的模块中定义。对于这个应用程序,StudentRecord类定义在studentfile.py模块的末尾。有些存储类可能是为特定类的内部使用而设计的,并不需要从模块外部访问。在这些情况下,存储类的名称将以单个下划线开头,这会将其定义为对其定义的模块是私有的。但是,StudentRecord类并没有被定义为模块的专用模块,因为存储类的实例不是被定义在ADT中,而是通过Student File Reader类的方法返回到客户端代码中。存储类可以在需要时与StudentFileReader类一起导入。您将会注意到存储类中的数据字段是公开的(由我们的符号表示),因为它们的名字并不是以下划线开始,因为它们已经在前面提到的其他类中。我们不包括访问数据字段的限制性接口的原因是,存储对象是专门用于存储数据的,而不是作为某种抽象数据类型的实例。由于使用有限,我们直接根据需要访问数据字段。
1.5.2 实现
学生文件读取器ADT的实现不需要数据结构,因为它不存储数据,而是从外部源提取数据。必须实施ADT才能根据存储数据的格式提取数据。在这个例子中,我们将从一个文本文件中提取数据,在这个文件中记录被一个接一个地列出来。记录的五个字段都存储在一个单独的行中。第一行包含id号,第二行和第三行包含姓和名,第四行包含分类代码,平均分数在第五行。以下文本块说明了包含两条记录的文件格式:
10015
John Smith
2
3.01
10334
Jane Roberts
4
3.81
注意:Python元组:元组可以用来存储结构化数据,每个元素对应一个单独的数据字段。 然而,这不是一个好的做法,因为这些元素没有被命名,你将不得不记住每个元素中存储了哪些数据。 更好的做法是使用具有命名数据字段的对象。 在这本书中,我们限制使用元组从方法和函数中返回多个值。
清单1.6提供了ADT的实现,用于从文件格式中提取记录。构造器通过创建两个属性来初始化类的实例,一个用于存储文本名称,另一个用于在文件打开后存储对文件对象的引用。open()方法负责使用保存在构造函数中的名称来打开输入文件。生成的文件对象保存在inputFile属性中,因此可以在其他方法中使用。记录提取后,通过调用close()方法关闭文件。
Listing 1.6 The studentfile.py module.
1 # Implementation of the StudentFileReader ADT using a text file as the
2 # input source in which each field is stored on a separate line.
3
4 class StudentFileReader :
5 # Create a new student reader instance.
6 def __init__( self, inputSrc ):
7 self._inputSrc = inputSrc
8 self._inputFile = None
9
10 # Open a connection to the input file.
11 def open( self ):
12 self._inputFile = open( self._inputSrc, "r" )
13
14 # Close the connection to the input file.
15 def close( self ):
16 self._inputFile.close()
17 self._inputFile = None
18
19 # Extract all student records and store them in a list.
20 def fetchAll( self ):
21 theRecords = list()
22 student = self.fetchRecord()
23 while student != None :
24 theRecords.append( student )
25 student = self.fetchRecord()
26 return theRecords
27
28 # Extract the next student record from the file.
29 def fetchRecord( self ):
30 # Read the first line of the record.
31 line = self._inputFile.readline()
32 if line == "" :
33 return None
34
35 # If there is another record, create a storage object and fill it.
36 student = StudentRecord()
37 student.idNum = int( line )
38 student.firstName = self._inputFile.readline().rstrip()
39 student.lastName = self._inputFile.readline().rstrip()
40 student.classCode = int( self._inputFile.readline() )
41 student.gpa = float( self._inputFile.readline() )
42 return student
43
44 # Storage class used for an individual student record.
45 class StudentRecord :
46 def __init__( self ):
47 self.idNum = 0
48 self.firstName = None
49 self.lastName = None
50 self.classCode = 0
51 self.gpa = 0.0
第20-26行的fetchAll()方法是一个简单的事件控制循环,它构建并返回一个StudentRecord对象列表。这是通过重复调用fetchRecord()方法来完成的。因此,从文本文件中实际提取记录是由fetch Record()方法处理的,如第29-42行所示。为了从数据以不同格式存储的文件中提取学生记录,我们只需要修改这个方法来适应新的格式。
StudentFileReaderADT提供可用于从文本文件中提取任何类型的记录的框架。 只需要在fetchRecord()方法中创建适当的存储对象并从给定格式的文件中提取数据。