计算机视觉基本知识
计算机视觉主要分为四个步骤:图像获取、图像校正、立体匹配和三维重建。其中,立体匹配的目的是在两个或多个对应同一场景的图像中找到匹配点,生成视差图。视差图可以通过一些简单的几何关系转换成深度图,用于三维重建。立体匹配是计算机视觉领域一个瓶颈问题,其结果的好坏直接影响着三维重建的效果。
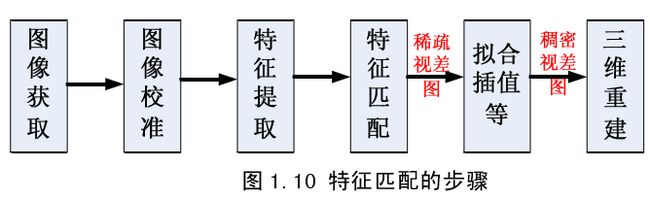
立体匹配算法,主要分为特征匹配算法和区域匹配算法。特征匹配算法主要是提取图像特征进行匹配,生成视图。由于只提取局部特征,因此特征匹配算法速度快,但是得到的都是稀疏的视差图,而稀疏的视差图在很多应用中都不适用。
基于特征的匹配主要提取图像特征点进行匹配,例如边缘、轮廓、直线、角点等,具体步骤如图所示。由于这些特征点不受光照、尺度、旋转等变化影响,因此基于特征的匹配对于图像畸变、遮挡等具有一定的鲁棒性。但是它得到的视差图为稀疏视差图,如果需要像素的视差信息没能在稀疏视差图中得以体现,则需要利用已得到的特征点的视差通过拟合、插值、局部生长法等方法将稀疏视差图转成稠密视差图,来得到需要像素的视差信息。这种通过周围特征点插值计算得到的稠密视差图往往不可靠,丧失了大部分表面细节,使得生成的视差图不可靠。
区域匹配算法依据是否使用全局搜索可以分为全局匹配算法和局部匹配算法。全局匹配算法是基于像素的,通常将匹配运算构建在一个能量最小化的框架下,然后使用优化算法来最小化或最大化能量函数,得到视差图。比较经典的全局匹配算法有:置信度传播算法(belief propagation)、图割算法(graph cut)等。全局匹配算法得到的视差图较为准确,但运行时间长。局部匹配算法将像素代价聚集在一个支持窗中,然后选择与其相匹配的支持窗。然而,在这个过程中,选择合适的支持窗是一个困难的问题。
全局匹配将立体匹配关系用一个能量函数表示,如下式所示。能量函数由匹配代价和平滑代价组成,然后使用不同的优化算法来迭代地得到视差图。经典的全局算法有置信度传播算法(belief propagation)、图割算法(graph cuts)、动态规划算法(dynamic programming)等。这些算法虽然能得到比较正确的视差图,但都需要通过多次迭代来获得最终结果,其计算耗时大,效率低。
2006 年 Yoon 提出了自适应权值算法,固定支持窗的大小,赋予支持窗中每个像素不同的权值。Yoon 算法的性能超过了一般的局部算法,甚至可以和全局算法相媲美,因此得到了很多的关注。
计算机视觉的目标是从摄像机得到的二维图像中提取三维信息,从而重建三维世界模型。在这个过程中,获得场景中某一物体的深度,即场景中物体各点相对于摄像机的距离,无疑成为了计算机视觉的研究重点。获得深度图的方法可分为被动测距和主动测距。被动测距是指视觉系统接受来自场景发射或反射的光能量,形成有关场景的二维图像,然后在这些二维图像的基础上恢复场景的深度信息。具体实现方法可以使用两个或多个相隔一定距离的照相机同时获取场景图像,也可使用一台照相机在不同空间位置上分别获取两幅或两幅以上的图像。主动测距与被动测距的主要区别在于视觉系统是否是通过增收自身发射的能量来测距,雷达测距系统、激光测距系统则属于主动测距。主动测距的系统投资巨大,成本太高,而被动测距方法简单,并且容易实施,从而得到了广泛的应用。利用被动测距的计算机视觉主要分为四个步骤,如图所示。
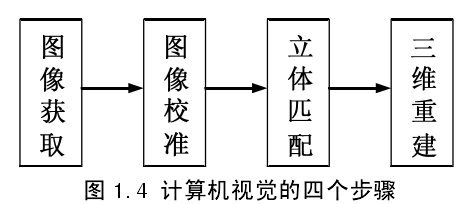
(1)图像获取。一般情况下,人类通过双眼来获得图像,双眼可近似为平行排列,在观察同一场景时,左眼获得左边的场景信息多一些,在左视网膜中的图像偏右;而右眼获得右边场景信息多一些,在右视网膜中的图像偏左。同一场景点在左视网膜上和右视网膜上的图像点位置差异即为视差,也是感知物体深度的重要信息。
计算机视觉的获取图像的原理与人眼相似,是通过不同位置上的相机来获得不同的图像,左摄像机拍摄的图像称为左图像,右摄像机拍摄的图像称为右图像。左图像得到左边的场景信息多一些,右图像得到右边场景的信息多一些,
(2) 图像校准。在图像获取过程中,有许多因素会导致图像失真,如成像系统的象差、畸变、带宽有限等造成的图像失真;由于成像器件拍摄姿态和扫描非线性引起的图像几何失真;由于运动模糊、辐射失真、引入噪声等造成的图像失真。
(3) 立体匹配。在两幅或多幅不同位置下拍摄的且对应同一场景的图像中,建立匹配基元之间关系的过程称为立体匹配。例如,在双目立体匹配中,匹配基元选择像素,然后获得对应于同一个场景的两个图像中两个匹配像素的位置差别,即视差。并将视差按比例转换到0-255 之间,以灰度图的形式显示出来,即为视差图。
(4)三维重建。根据立体匹配得到的像素的视差,如果已知照相机的内外参数,则根据摄像机几何关系得到得到场景中物体的深度信息,进而得到场景中物体的三维坐标。
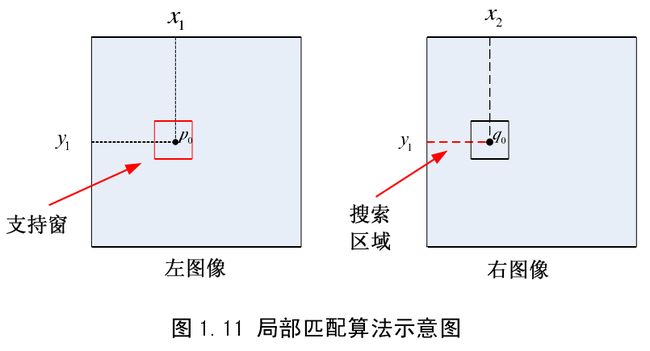
局部匹配算法主要有自适应支持窗算法(windowwith adaptive size)、自适应权值算法(adaptivesuppot-weight)和多窗口算法(multiple window)。自适应支持窗算法假设支持窗中的像素的视差值是一样的,然后在目标图像的搜索区域中寻找与参考图像支持窗差异最小的支持窗,两个支持窗中的中心像素即为匹配像素,图1.11 中左图像为参考图像,右图像为目标图像,和分别为左图像和右图像支持窗中的中心像素,由于采用水平极线校正的约束,因此,搜索区域为一维,即可能匹配像素的纵坐标y 相同。自适应权值的算法与自适应支持窗的算法不同,它用权值来代表支持窗中的像素对中心像素匹配影响的大小,权值越大,影响越大。多窗口匹配算法,主要是根据一定准则,在事先指定的多个窗口中选择最佳的窗口进行匹配计算。
在国际方面,将现存的立体匹配算法进行了分类和总结,将算法分成四个步骤:匹配代价计算、代价聚集、视差计算、视差精化,但并不是所有匹配算法中都包括这四个步骤,需要哪一步,要根据具体情况而定。还提出了一个专供稠密视差图定量测试的平台(www.middlebury.edu/stereo),得到了广泛的应用。下面将通过这四个步骤分别对国外近些年的立体匹配算法进行总结。
(1)匹配代价计算。若令参考图像中任一像素点为 p ,目标图像中可能匹配像素点为q ,d 为视差范围。最普通的匹配算法有灰度平方差异(squared intensity differences)和灰度绝对值差异(absoluteintensity differences)。
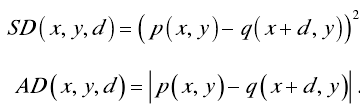
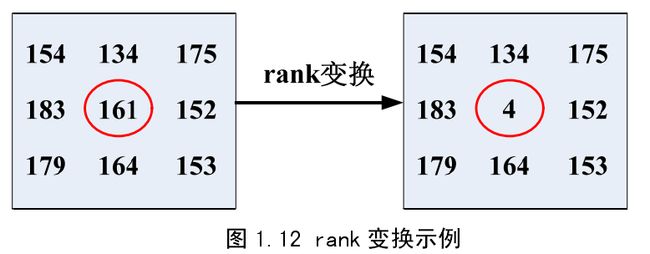
还有一些匹配代价对相机偏移、噪声和光照鲁棒,如基于梯度的一些测量rank 变换和census变换等。rank 变换大致过程为以待匹配像素为中心作一个矩形窗口(rank 窗口),然后统计 rank 窗口中灰度值比中心像素灰度值小的像素的数目,并用这个数代替原来中心像素的灰度值,依次计算,直到被转换成一个整数矩阵,这个整数矩阵称为rank 图像。图 1.12 为 rank 变换的一个示例,红色圈内为待匹配元素,rank 窗口大小为3*3 ,rank 窗口内比中心像素灰度值小的元素有 4 个,因此,用 4 来代替中心像素的灰度值。
而 census 变换则将窗口中心像素以外的像素变成一个比特串,如果窗口中一个像素的灰度值比中心像素大,则相应位置为1,反之为 0。文献匹配代价应用到相邻的半像素值,如下式所示,使得匹配代价对图像抽样具有一定的鲁棒性。

(2)代价聚集。局部算法是基于窗口的聚集方法,将支持窗内像素的代价相加或平均作为中心像素的匹配代价。支持窗可以是二维的,也可以三维的。二维的支持窗先将视差固定,然后计算聚集代价。除上述介绍的多窗口法和自适应窗口法,常用的支持窗有移动窗口(shiftable window)、常数视差的连通窗口(window based on connectd components of constant disparity)。三维支持窗包括有界的视差差分窗口(limited disparity difference)、有界的视差梯度窗口(limiteddisparity gradient)、Prazdny 的相关准则(coherence principle)等。
(3)视差计算。局部算法主要强调匹配代价、代价聚集和视差计算三个步骤,在视差计算中,最小代价对应的视差即为所要求的视差,这也被称为WTA 算法。这个算法的缺点在于它的唯一性约束只在参考图像中有所体现,而目标图像中的像素点可能对应许多个参考图像的像素点。而全局算法则强调视差计算步骤,通常跳过代价聚集步骤。
(4)视差精化。大多数立体匹配算法都是在一个离散的空间中进行运算的,得到的视差值也是整数的。对于许多应用,如机器人导航(robot navigation)和人类跟踪(people tracking),这已经足够了,但是对于图像绘制(image-based rendering)来说,这些量化的过程会导致视点综合的结果出现错误。为了应对这种情况,许多算法在初始视差计算后,应用子像素精化步骤。子像素精化方法有迭代梯度下降法(iterative gradient descent)和拟合曲线法(fitting a curve)。对偶运算(cross-checking)也可以对视差进行后处理运算,对偶运算可以检测出遮挡区域,然后应用平面拟合算法(surface fitting)或邻域视差估计算法(neighboringdisparity estimates)对遮挡区域的视差进行填补。
立体匹配面临的挑战
目前,国际上存在很多算法,但这些匹配方法仍不能很好地解决立体匹配中存在的一些问题:噪声、遮挡匹配问题、弱纹理或重复匹配问题、深度不连续问题、光照变化引起的匹配问题、倾斜区域的匹配问题。除此之外,立体匹配算法都在实验室进行实验阶段,通常在实验过程中采用了许多假设,例如匹配图像对应具有相同的图像特征,包括像素RGB 值,灰度值等,即匹配图像对不受光照等元素的影响。这些挑战限制了立体匹配算法在实际中的应用。
(1)噪声。图像获取过程中,受到光线变化,图像模糊,传感器噪声等因素的影响。这要求实际应用的立体匹配算法一定具有鲁棒性。
(2)遮挡问题。遮挡是由于摄像机的空间位置不同,造成一些场景在一幅图中可以看到,但在另一幅图中不可见的现象。本论文将在第六章详细介绍遮挡问题以及解决方法。
(3)弱纹理区域或纹理单调重复区域。图像对中存在大量重复区域,在寻找匹配点的过程中,容易存在二义性或多义性,使匹配不准确。如图所示,两个视点的图像由于重复性过多,对左图像中任一像素,在右图像中有许多像素和它相似,因此,在匹配中容易出现误匹配情况,影响了匹配质量。这个问题也叫“孔径问题”,即灰度一致性约束在无纹理区是无用的,所以,立体匹配时,消息需要从高纹理区传到低纹理区。

(4)深度不连续问题。图像中物体上视差都是平滑过度的,但到了物体边缘处,则视差出现突变,对于局部匹配来说,如果在物体边缘处还认为其匹配窗内的像素视差相同的话,则会出现一些错误,对结果造成影响。如图所示,图中物体比较多,物体边缘也多,因此采用局部匹配很容易出现错误。在全局算法中,当使用空间平滑约束时,消息传递应该停止在物体边缘。

(5)光照强度变化。照相机处于不同的空间位置,如果场景中存在一些镜面反射的现象,有可能使对应点在两幅图像中表现出不同的特征,导致匹配错误。如图所示,两个曝光不同的针对同一场景的图像有不同的RGB 值,而通常的匹配算法则是通过像素 RGB 值来判断两个可能匹配像素是否匹配,这样,光照条件差异无疑给立体匹配造成了许多困难。

(6)倾斜区域。由于视差图中视差变化是以整数为单位的,即离散的;而场景中物体的深度变化是连续的,用离散的视差表示连续的地方,必定会出现一些不足。
摄像机成像几何模型
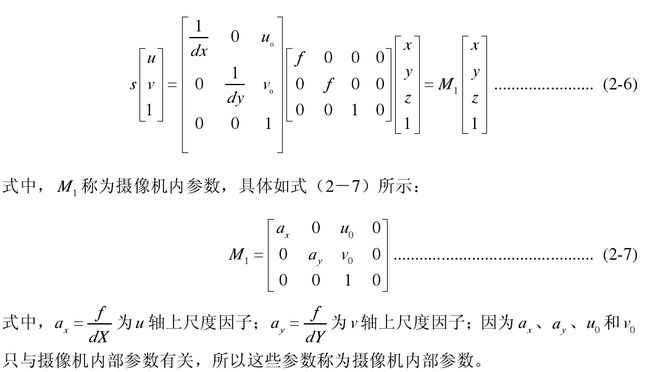
在立体视觉系统中,第一步应该建立摄像机成像系统,进行摄像机标定,然后获取图像对,最后进行立体匹配与三维重建等后续工作。如图所示,用摄像机拍摄建筑上的某一点,然后在照片中出现这个三维点的二维投影点,而摄像机标定主要是根据摄像机成像系统,来建立三维场景中的点和二维图像像素位置的对应关系。摄像机需要标定的模型参数分为内部参数和外部参数。摄像机模型也有许多,主要分为线性模型和非线性模型。线性模型又称针孔成像模型,是实验室中常用的一种模型,将着重介绍。

针孔成像模型
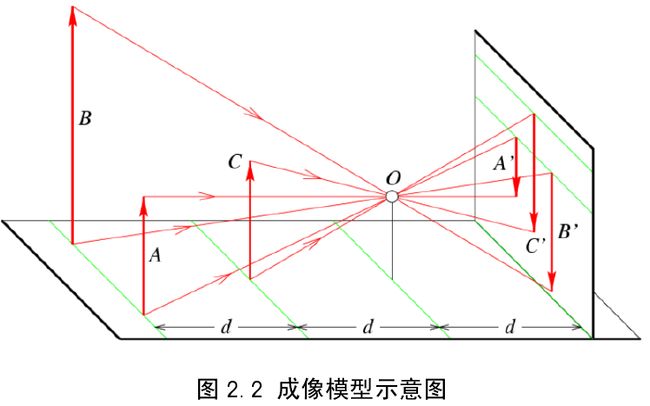
首先,介绍最简单的点光源成像模型,如图2.2 所示,A ,B ,C 代表实际空间中的线,O 点为光心, A’, B’和C’分别为 A , B 和C 在图像平面中的成像,从图中可知,实际空间中的三维点和图像中的二维投影点确实存在一定的对应关系,且根据几何关系可求得。
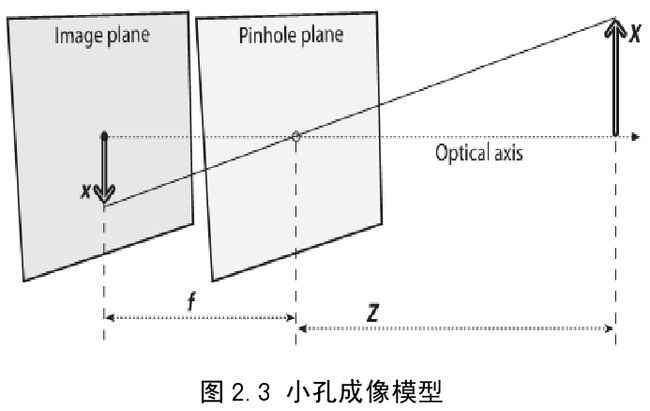
然后,引入小孔成像模型,如图 2.3 所示。所有光线都经过小孔,使得物体通过孔平面在图像平面上形成了一个倒立的实像。图像平面与孔平面的距离为f ,孔平面与物体的距离为 Z 。
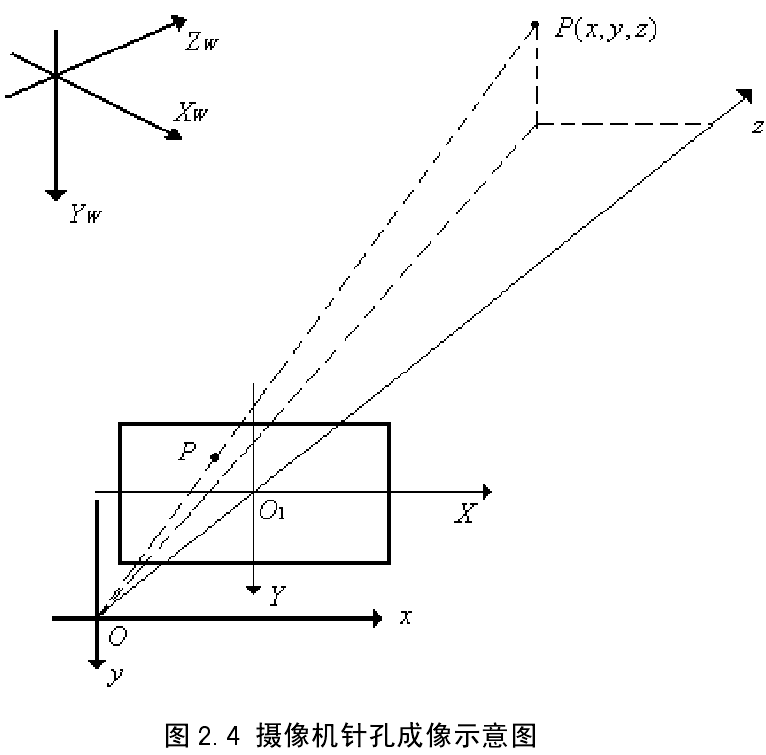
为了向摄像机模型靠近,将成像平面和景物放在一侧,如图2.4 所示。P(x,y, z)为实际空间中一点,p(x, y)为其对应的像平面上的点,为图像平面与摄像机光心O 的距离 ,一般称为摄像机的焦距,用 f 表示。根据几何关系,我们能得到如下式子:

用齐次坐标和矩阵表示式(2-1)的关系如下:
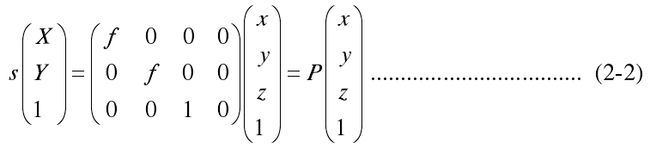
式中, s 为一比例因子, P 为透视投影矩阵。
图像坐标系与摄像机坐标系
摄像机拍摄的图像经高速图像采集系统变换为数字图像,并输入计算机,计算机内每幅数字图像显示为 M*N 数组,即有M 行 N 列个元素,其中每一个元素称为像素。
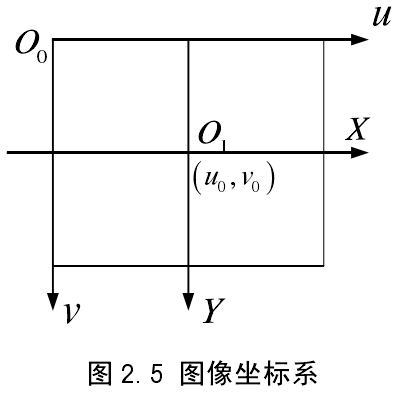
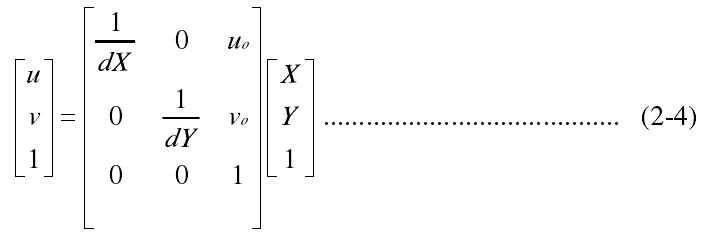
如图 2.5 所示,每一个像素的坐标(u,v)是以像素为单位的图像坐标系坐标,代表该像素在计算机中的行数和列数。由于以像素为单位的图像坐标系没能显示像素在图像中的位置,因此又定义了一个以物理单位表示的图像坐标系。以图像中某一点为原点,作 X 、 Y 轴与u 、 v 轴平行,(X,Y)即为像素的图像坐标系。每一个像素在X 轴与Y 轴的物理尺寸为 dX 和 d Y ,图像中任一像素在两个图像坐标系的关系可表示为如下:

用齐次坐标与矩阵的形式可表示为
逆关系可写成
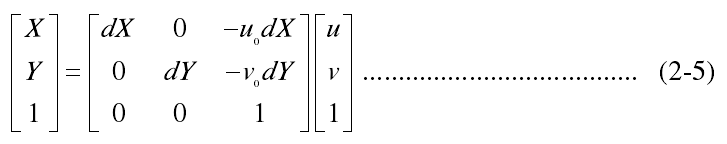
摄像机坐标系与世界坐标系
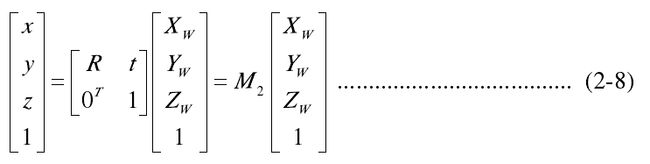
世界坐标系描述摄像机在环境中的任意位置,也用它来描述环境中任何物体的位置,由WX 、WY 和WZ 轴组成。摄像机坐标系和世界坐标系之间的关系可用旋转矩阵R 和平移向量t 来描述,用齐次坐标与矩阵的形式可表示为:

图像坐标系与世界坐标系
将式(2-8)代入式(2-6)中,得到图像坐标系与世界坐标系的关系,如下式所示:
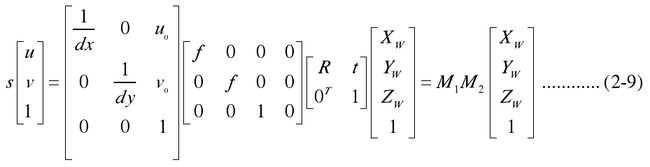
从式(2-9)可知,已知摄像机内外参数M1 和M2 ,对任意空间点 P ,如果知道它的世界坐标系坐标,就可以知道它的图像坐标系坐标;而已知它的图像坐标系坐标,并不能知道它的世界坐标系坐标,而只能确定它的空间点均在射线OP 上,如图 2.4 所示。因此,为了得到一空间点准确的世界坐标系坐标,就必须有两个或更多摄像机构成的立体视觉系统模型才能实现。
双目立体视觉
双目立体视觉原理
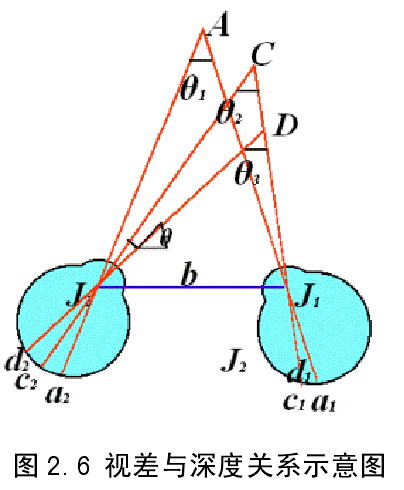
人用双眼去观察实际空间中物体,空间中的物体点在左右两眼视网膜上成像,左视网膜成像偏右,右视网膜成像偏左,这种差异称为双目视差(binocular disparity),人有深度感知就是因为双目视差,如图2.6 所示。两眼同时看实际空间中的 A 点、C点和 D 点,三点在左视网膜上成像为a2、c2和d2;三点在右视网膜中成像为a1、c1和d1,从图中可明显看出c1,c2的距离比d1,d2
的距离短,即C 点的视差比D点小,而空间点C 点比 D 点离人眼的距离远。
基于此理论,用两个摄像机代替人眼,对同一空间物体拍摄,获得两幅图片,称为立体图像对。然后,运用立体匹配算法找到对应同一物体点的图像点,计算出视差,根据简单的三角几何关系即可得到此物体点的深度信息。
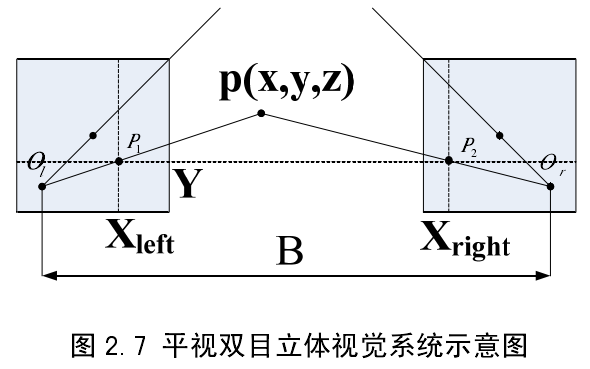
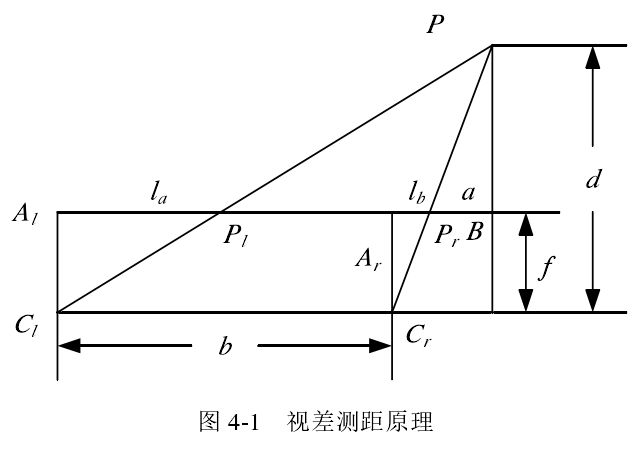
图2.7为简单的平视双目立体视觉系统示意图,和分别为左摄像机和右摄像机的光心,两个光心连线即为基线,基线距离为 B 。p 为实际空间中一点,它在左图像上成像点为,在右图像上成像点为。假设两个摄像机是平行的,在同一平面上,因此左右图像成像点的纵坐标相同,即。由三角几何关系得到
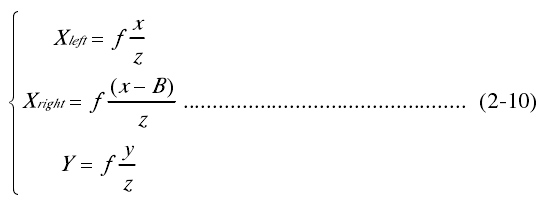
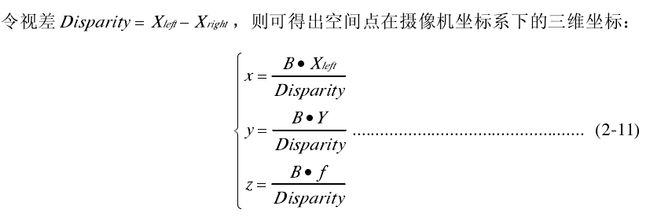
从式(2-11)可以看出,对于简单平视的双目立体视觉系统,只要找到对应同一空间点的图像匹配点,知道焦距f 和基线 B 距离,就可以得到空间点在摄像机坐标系下的三维坐标。z 即为空间点 p 的深度,可以看出空间点视差和深度是成反比的。
极线几何
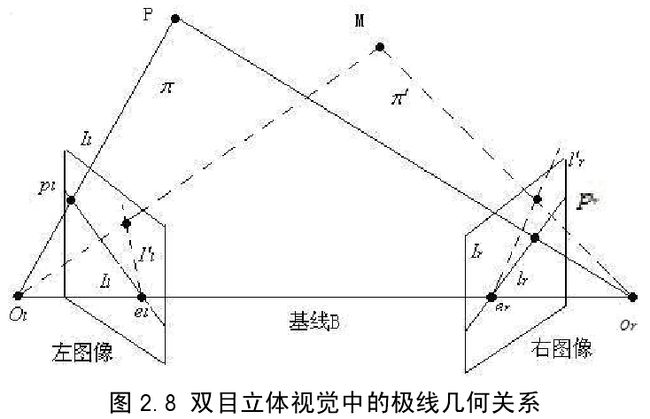
极线几何讨论的是两个摄像机图像平面的关系,下面介绍几个概念,如图 2.8。(1)基线:指左右两摄像机光心和的连线,用 B 表示。
(2)极平面:指任一空间点和两摄像机光心三点确定的平面,如平面和平面都是极平面,所有的极平面相交于基线。
(3)极点:指基线与左右两图像平面的交点,用和表示。
(4)极线:指极平面与左右两图像平面的交线,左图像或右图像中所有极线相交于极点或。
立体匹配中,为了降低可能匹配点对的数量,提出了极线约束,即左图像上的任一点,在右图像上的可能匹配点只可能位于极线上。假设和是空间中同一点 p在两个图像匹配点。左图像平面任一点,它在右图像上的可能匹配点不可能在整个平面上,而一定位于极线上,这样找到最终匹配点为;相似的,右图像平面点,在左图像上的可能匹配点一定位于极线上,和称为共轭极线。极线约束使得立体匹配搜索范围从二维平面降到一维直线,大大减少了搜索时间,在立体匹配中占据着重要的地位。
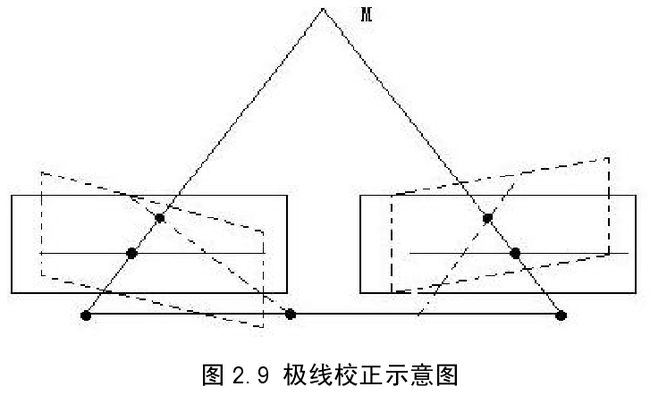
如上一节分析,在平视双目立体视觉系统中,左右图像匹配点之间的纵坐标相同,只存在水平差异,即极线是水平的,这一特征对立体匹配算法的简化起了很大的作用。然而,在实际应用中,由于组装、成像等多方面原因,平视双目立体视觉系统很难构建,左右图像中可能匹配点之间不只存在水平差异,同时也存在垂直差异,这就需要通过极线校正来使左右两幅图像的极线相平行,消除或减少两个可能匹配点间的垂直差异,从而较小匹配搜索难度。极线校正示意图如图 2.9 所示,将汇聚立体匹配模型的两个图像平面进行了旋转,产生虚拟的平行立体系统,其中虚线为原图像平面,实线为经过校正后的图像平面。
基本约束关系
为了提高系统的去歧义匹配能力和计算效率,除了上一节所说的极线约束,立体匹配中还存在许多匹配约束,如唯一性约束(uniqueness Constraint)、连续性约束(ContinueConstraint)、相似性约束(Feature Compatibility Constrain)、顺序一致性约束(ordering Constraint)、互对应约束(Mutual correspondence constraint)、视差范围约束(DisparitvLimit constraint)。 下面将分别介绍这几种约束。
(1)唯一性约束。对双目匹配来说,参考图像上的任一点在目标图像上只能有唯一的点与其相匹配。此约束可避免重复匹配问题。
(2)连续性约束。空间中物体表面一般都是光滑的,因此摄像机将其拍摄在图像上的点是连续的。在计算视差时,参考图像上同一物体上相邻点的视差应该是连续的。对物体边界处的点,连续性约束并不成立。
(3)相似性约束。在两幅或多幅图像对应同一实际空间上的点,在某些物体度量上(如灰度,梯度变化等几何形状上)具有一定的相似性。例如空间中某一点在物体的边缘,梯度变化较大,则它在另一幅图像上也位于物体的边缘,且梯度变化较大。
(4)顺序一致性约束。对于参考图像上的两个像素和,在的左边,这两个像素在目标图像上的对应像素分别为和 ,则也在的左边。但此约束在视点方位变化很大时不满足。
(5)互对应约束。左图像上的像素和右图像上的像素为一对匹配像素。如果根据立体匹配运算,以左图像为参考图像,找到像素 在右图像中的匹配像素,那么,以右图像为参考图像,同样也能找到像素 在左图像中的匹配像素为 。这个过程也被称为对偶运算,可以有效减少立体匹配过程中由于遮挡、高光或噪声原因而导致的误匹配问题。
(6)视差范围约束。视差范围约束是指人类视觉系统只能融合视差比某个限度小的立体图像。此约束限制了寻找对应点时的搜索范围。例如从Middlebury 网站上得到的测试图像 cones 和 teddy 的视差范围为 0-59。
同一物点Q在左右眼两幅视差图上的对应像素点分别称为左像素点L和右像素点R,两像素点间的水平距离称为该物点的水平视差。
三维模型特征提取算法
三维模型由于其结构属于三维子空间,因此能够表现的信息较二维图像更多、更复杂。基于内容的三维模型检索需要根据模型的形状信息提取特定的特征描述符,以特征描述符来代替三维模型的形状特征,然后根据特征描述符的形式来确定三维模型间的相似度,从而实现对三维模型的相似性检索。因此特征描述符也称为三维形状描述子。大多数三维模型的特征描述符都是基于三维模型的几何属性,包括顶点坐标、法向矢量、高斯曲率、三角形面积、法向矢量等等。根据描述机理和侧重特征的不同可将三维形状描述子分为:
A. 基于全局特征(Global Feature-based)的方法
B. 基于统计(Histogram-based)的方法
C. 基于投影视图(Graph-based)的方法
D. 基于拓扑结构(Topology-based)的方法
E. 基于局部特征点的方法
F. 综合利用上述方法的混合描述算子(HybridDescriptor)
基于统计的特征提取算法
由于三维模型的表面有任意的拓扑结构,因此一些在二维图像分析和检索中常用的一些算法无法直接在三维模型检索领域进行拓展和应用;同时对三维模型进行参数化表示也是很复杂的问题,导致获取有清晰几个或形状意义的三维模型特征十分困难。
由于存在上述诸多的困难和不便,很多研究人员倾向于从统计学的观点出发,应用一些统计特征作为三维模型的特征。这方面的研究主要使用了模型顶点间的距离、角度、法向、曲率、面积等的几何数据分布以及各阶统计矩和变换特征系数等。
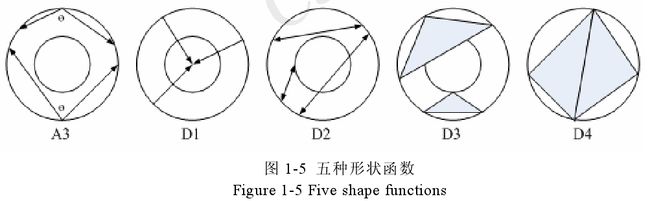
在大多数基于统计的特征提取算法中,经常被引用的一个算法是Osada等根据顶点在模型表面上的相互关系统计出的分布特征,如此即将一个任意的三维模型中的复杂特征提取问题转化为一个简单形状分布的概率问题。算法使用了5 种在三维模型上采样得到的几何函数,统计这些几何函数的取值,然后对取值进行排序,构造成值序列,以该序列作为三维模型的特征描述符来描述三维模型的形状特征,最后,计算不同序列之间的欧式距离来确认2 组序列之间的相似度,以此来代替三维模型的相似度。该算法基于统计特征,在三维模型检索领域已经成为比较经典的算法之一。
A1:基于角度的函数,在模型表面上采样任意三个顶点构成的两条线段之间的角度;
D1:基于距离的函数,采样模型中心到任意顶点的距离;
D2:基于距离的函数,采样任意两个顶点之间的距离;
D3:基于面积的函数,采样任意三个顶点组成的三角形面积的平方根;
D4:基于体积的函数,采样任意四个顶点组成的四面体体积的立方根;
由于采样的数据都是基于顶点的,因此该方法具有平移、旋转、缩放不变性,同时抗噪音干扰效果也比较好。实验分析的结果表明,基于D2 距离的几何函数,在这 5 种几何函数中的检索效果最好,也就是图1-5 中的 D2 距离。然而,当三维模型形状比较复杂,包含较多细节信息时,D2 距离分布就会因为信息表征过于粗糙而造成差别较大的三维模型具有相似的形状分布。为了提高 D2距离形状描述符的检索能力, 为了提高 提出根据两点间连线是否经过模型内部、外部或都经过将 D2 分布分为内部、外部、混合三种类型,实现对 CAD 模型的相似性检索。
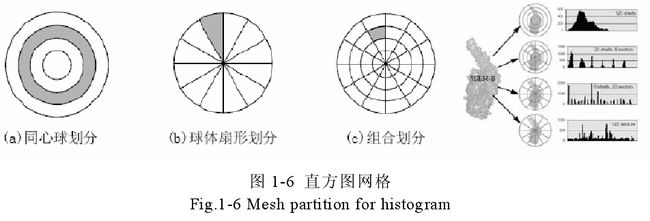
除了前面的采样统计的方法以外,还有一些基于切分统计的方法,用球体或者用正立方体进行切分,其中 Ankerst提出了一种用球体对模型进行切分,然后进行统计的方法。该方法首先计算可以包围模型的最小球体,然后将球体按照 3 种规则分割成一系列的格子,分别是基于同心球、基于扇形和组合的切分规则,如图 1-6 所示。通过统计每个格子中的顶点数量,来构造三维模型的特征序列,作为三维模型的特征描述符使用。对于大多数以三角网格表示的三维模型来说,同样的形状可能存在不同的三角网格表示形式,因此模型上网格的细分和简化是影响此类算法准确性的一个问题。若要提高该方法对模型表示形式的兼容性,则需要在使用该方法之前,对三维模型的三角网格化表示形式进行统一的简化处理,增强该算法的稳定性。
在图 1-6 中,(a)是基于同心球切分规则的示意图,(b)是基于扇形切分规则的示意图,(c)是基于组合切分规则的示意图。在这三种切分规则中,基于同心球的切分规则,其特征描述符具有旋转不变性;基于扇形的切分规则,模型的等比例变化对其特征描述符没有影响;基于组合的切分规则,特征描述符的维数比前两个更大,更能体现三维模型的形状细节,但是失去了旋转和比例不变性。图1-6 最右侧的图是将一个三维蛋白质分子模型应用上述三种方法获得的特征描述符的图形化表示。
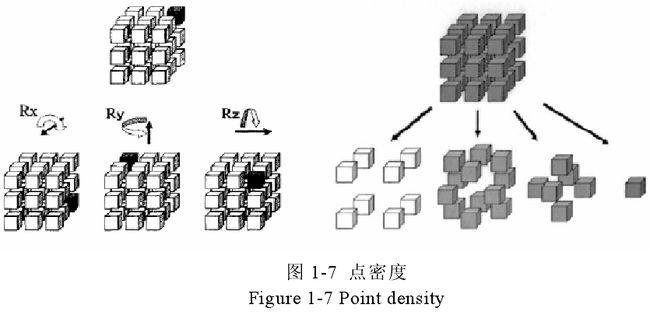
另一种用正立方体切分的方法由 Suzuki提出,顾名思义,该方法与用球体切分的方法类似,采用可以容纳模型的最小正立方体将模型进行包围,然后对正立方体进行切分,将切分后的立方体切块进行分类,然后统计切分后的每个立方体切块中的三维模型的顶点数量,据此构造三维模型的特征描述符,以此来描述三维模型的形状特征。由于切分后的切块都是小立方体形式,因此该方法也被称为“点密度方法”。图1-7 展示了点密度方法的大致思路。
模型预处理
随着计算机三维造型软件技术的发展以及互联网的普及,三维模型的制作软件和网上可共享的资源也越来越多,但是能够在互联网上获取到的三维模型在尺寸、位置和方向上都存在着或多或少的差异。因此使用的三维模型的来源的多样性导致三维模型可能具有不同的尺度、方位、旋转角度等。这种基本信息的不统一性在三维模型特征提取过程中会对特征结果产生严重影响,所以要在特征提取时,要使得提取出来的特征向量具有平移不变性、旋转不变性、缩放不变性。
一种解决的办法是把要进行匹配的模型,相互对齐坐标方向,但是这种方案对每个库中的三维模型都要进行一次坐标对准,需要耗费大量的时间,因此很少被采用。另一种解决的办法是在提取三维模型特征之前对三维模型进行一系列的处理,该处理将模型进行变换,变换后的三维模型将会统一在标准的坐标尺度下,具有相同的方向、位置和角度。这一系列操作被称为模型标准化(Normaliztion),也叫预处理。一般预处理过程中,以三维模型的质心作为坐标原点,对三维模型进行平移变换,保证模型具有平移不变性;采用主成分析法(Principal Componment Analize)将三维模型旋转对齐,使之保证旋转不变性;对三维模型的顶点到质心距离进行计算,采用最大距离作为标准值对三维模型进行尺度归一化。、
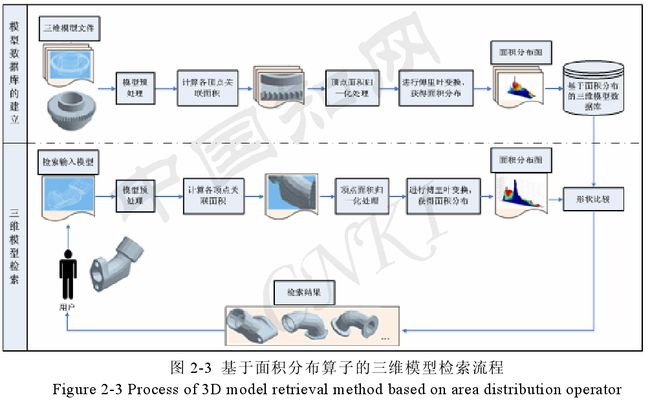
基于面积分布算子的检索算法的基本思想是三维模型 STL 文件作为入,首先对模型进行预处理,使得表达模型的点和面的集合达到最小化,接着通过计算各个顶点关联的三角形面积,并对点相关的面积进行归一化处理,然后对点关联的面积序列进行通傅里叶变换,得到特征向量,做出面积分布图,通过计算模型间特征向量的差异,得到模型间的差异,进而检索出相似的三维模型。
模型的简化处理
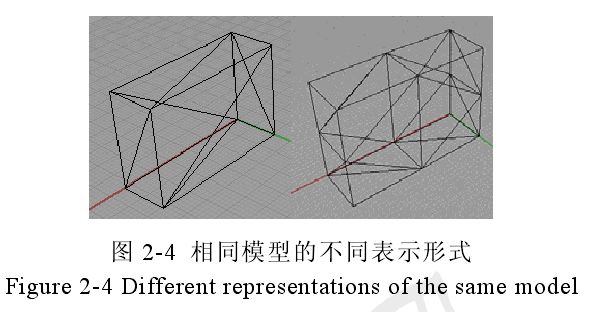
STL 文件是以三角网格模型表示模型的,因此对于相同的模型可能存在着不同的表示形式,如图 2-4所示,就是同一个模型的两种网格表示形式。
对于图 2-4 中的 2 个模型的表示形式,可以看出,第 1 个模型的表示方式其点和面积的集合最小,而第 2 个模型中存在着部分点并不能表示模型的凸凹信息,将这些点过滤后会得到与第 1 个模型相似的点和面的集合。
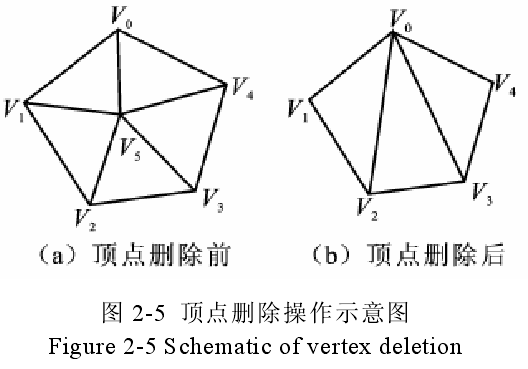
为了避免相似模型的不同的点和面的表示形式对算法的影响,考虑对所有的模型先进行预处理过程,也就是对模型进行简化,使模型的表达简洁,同时更好的突出对象的关键特征,现有的网格简化策略中,几何元素删除法应用最为广泛,它包括顶点删除法、三角形折叠法、边折叠法等,采用基于顶点删除的三角形网格模型简化方法,对模型进行预处理,基本思想是判断每一顶点的类型,根据不同的类型选择不同的判据进行计算,若满足判据成立条件,则将顶点删除,对形成的空洞三角化,其操作示意如图 2-5所示:
判断顶点是否可删除有 2 个准则,第一,如果一个顶点所有邻接三角形的法向量均相同,则删除该顶点,第二邻接三角形某2 个边在一条直线上,第一个是将平面中间的点去掉,第二个是将边缘上不必要的点去掉。根据该算法,对图 2-4 中第 2 个模型进行了简化处理,最终得到了一个与图 2-4 中第 1 个模型类似的模型化表示。
匹配约束条件
一般情况下,一幅图像中的某一特征基元在另一幅图像中可能会有很多候选匹配对象,可真正同名的结构基元只有一个,因此可能会出现歧义匹配。在这种情况下,就需要根据物体的先验知识和某些约束条件来消除误匹配,降低匹配工作量,提高匹配精度、准确度和速度。常用的约束原则如下:
1)极线约束:一幅图像上的任一点,在另一幅图像的对应点只可能位于一条特定的被称为极线的直线上。这个约束极大的降低了待验证的可能匹配点对的数量,把一个点在另一幅图像上的可能匹配点的分布从二维降到了一维。若是已知目标与摄像机之间的距离在某一区间内,则搜索范围可以限制在极线上的一个很小区间内,这样可以大大的缩小对应点的搜索空间,既可以提高特征点搜索速度,也可以减少误匹配的数量。
2)唯一性约束:一般情况下,一幅图像上的一个特征点只与另一幅图像的唯一特征点对应。

一般情况下,当人观察一现实世界中某一物体的时候,每只眼睛的视网膜上各自形成一个独立的影像,左眼看到物体的左边多一些,右眼看到物体的右边多些,同一物体在两个视网膜上得到不同的影像,同一物体上某点落在左右两眼视网膜上的位置是不同的,这种位置差就称为双眼视差。人之所以能有深度感知,就是因为有了这个视差,本文的工作主要就是根据人类双眼对同一景物成像的视差原理来研究双目视觉图像的视差生成算法。
按照marr的理论,视觉过程可以看成是成像过程的逆过程,在成像过程中,有如下三个重要的变化。
(1)三维的场景被投影为两维的图像,深度和不可见部分的信息被丢失了,因为也产生了同一物体在不同视角下的图像会有极大的不同,以及后面的物体被前面的物体遮挡而丢失信息等问题。
(2)场景中的诸多因素,包括照明和光源的情况、场景中的物体的几何形状和物理性质特别是物体表面的发射特性、摄像机的特性、以及光源于物体设摄像机之间的空间关系等,都被综合成单一的图像中的像素的灰度值了。
(3)成像过程或多或少的带入了一些畸变和噪声。
总之,由于成像过程中存在的投影、混合、畸变与噪声等原因,使得作为成像过程逆过程的视觉过程是个病态的问题。
Marr的视觉理论框架
70年代中期到80年代中期,Marr提出了第一个计算机视觉领域的理论框架,即视觉计算理论,极大地推动了计算机视觉的发展,并最终形成了这一领域的主导思想,Marr的视觉计算理论立足于计算机科学,系统地概括了心理学、物理学、神经生理学、临床神经病理学等方面已经取得的重要成果,是迄今为止比较系统的视觉理论,计算机视觉这一学科与此理论框架有着密切的关系,目前的基于视觉的方法都还没有脱离这个指导性的理论框架,如图1-1所示。
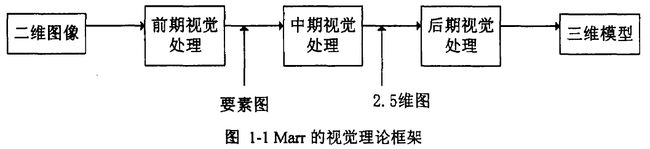
Marr的视觉计算理论从信息处理的角度出发,认为视觉处理中存在三个不同的层次,即计算理论的层次、表示数据结构与算法的层次、硬件实现的层次。其中最重要的是计算理论层次,并根据Warrington临床神经学的研究结果,阐明视觉的目的是从图像中建立物体形状和位置的描述。在这一层次把视觉过程主要规定为从二维图像信息中定量地恢复出图像所反映的场景中的三维物体的形状和空间位置,即三维重建。在计算理论这一层次上,与三个层次对应,Marr将三维重建这一过程分为三个阶段。第一阶段是从图像中获得要素图,称为早期视觉。所谓要素图是只从图像中灰度变化剧烈处的位置及其几何分布和组织结构,如零交叉、边缘、边界等,早期视觉是提取原始二维图像中的有用信息而抛弃无关紧要的部分,第二阶段是由要素图获得2.5维图,称为中期视觉,2.5维图是指在以观察者为中心的坐标系中,景物表面的法向,深度及轮廓等,这些信息包含了深度信息,但不是真正的物体三维表示。第三阶段是由第一阶段和第二阶段的结果获得物体的三维表示,称为后期视觉,所谓物体的三维表示是指在物体坐标中心描述各物体之间的空间关系。
所有的知识点均为从论文中截取的有效知识点。