线性判别分析LDA原理
线性判别分析LDA原理
线性判别分析LDA(Linear Discriminant Analysis)又称为Fisher线性判别,是一种监督学习的降维技术,也就是说它的数据集的每个样本都是有类别输出的,这点与PCA(无监督学习)不同。LDA在模式识别领域(比如人脸识别,舰艇识别等图形图像识别领域)中有非常广泛的应用,因此我们有必要了解下它的算法原理。
1. LDA的思想
LDA的思想是: 最大化类间均值,最小化类内方差。意思就是将数据投影在低维度上,并且投影后同种类别数据的投影点尽可能的接近,不同类别数据的投影点的中心点尽可能的远。
我们先看看最简单的情况。假设我们有两类数据 分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
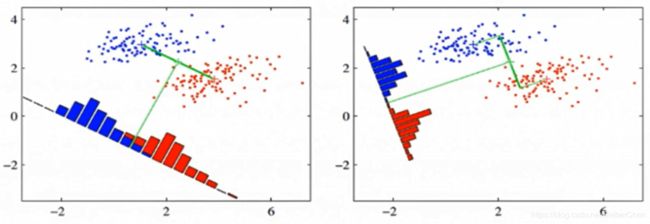
上图提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,当然在实际应用中,我们的数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
2. 瑞利商(Rayleigh quotient)与广义瑞利商(genralized Rayleigh quotient)
首先来看瑞利商的定义。瑞利商是指这样的函数 R ( A , x ) R(A,x) R(A,x):
R ( A , x ) = x H A x x H x R(A, x)=\frac{x^{H} A x}{x^{H} x} R(A,x)=xHxxHAx
其中, x x x是非零向量,而 A A A为 n × n n\times n n×n的Hermitan矩阵。所谓的Hermitan矩阵就是满足共轭转置矩阵和自己相等的矩阵,即 A H = A A^H=A AH=A,例如, A = ( 1 2 + i 2 − i 1 ) A=\left(\begin{array}{cc}{1} & {2+i} \\ {2-i} & {1}\end{array}\right) A=(12−i2+i1)的共轭转置等于其本身。当 A A A为实矩阵时,如果满足 A T = A A^T=A AT=A,则 A A A为Hermitan矩阵。
瑞利商 R ( A , x ) R(A,x) R(A,x)有一个非常重要的性质,即它的最大值等于矩阵 A A A最大的特征值,而最小值等于矩阵 A A A的最小的特征值,也就是满足
λ min ≤ x H A x x H x ≤ λ max \lambda_{\min } \leq \frac{x^{H} A x}{x^{H} x} \leq \lambda_{\max } λmin≤xHxxHAx≤λmax
当向量 x x x是标准正交基,即满足 x H x = 1 x^{H} x=1 xHx=1时,瑞利商退化为 R ( A , x ) = x H A x R(A, x)=x^{H} A x R(A,x)=xHAx。
下面看一下广义瑞利商。广义瑞利商是指这样的函数 R ( A , B , x ) R(A,B,x) R(A,B,x):
R ( A , B , x ) = x H A x x H B x R(A,B, x)=\frac{x^{H} A x}{x^{H} B x} R(A,B,x)=xHBxxHAx
其中x为非零向量,而 A , B A,B A,B为 n × n n\times n n×n的Hermitan矩阵。 B B B为正定矩阵。它的最大值和最小值是什么呢?其实我们只要通过将其通过标准化就可以转化为瑞利商的格式。令 x = B − 1 / 2 x ′ x=B^{-1 / 2} x^{\prime} x=B−1/2x′,则分母转化为:
x H B x = x ′ H ( B − 1 / 2 ) H B B − 1 / 2 x ′ = x ′ H B − 1 / 2 B B − 1 / 2 x ′ = x ′ H x ′ x^{H} B x=x^{\prime H}\left(B^{-1 / 2}\right)^{H} B B^{-1 / 2} x^{\prime}=x^{\prime H} B^{-1 / 2} B B^{-1 / 2} x^{\prime}=x^{\prime H} x^{\prime} xHBx=x′H(B−1/2)HBB−1/2x′=x′HB−1/2BB−1/2x′=x′Hx′
而分子转化为:
x H A x = x ′ H B − 1 / 2 A B − 1 / 2 x ′ x^{H} A x=x^{\prime H} B^{-1 / 2} A B^{-1 / 2} x^{\prime} xHAx=x′HB−1/2AB−1/2x′
此时我们的 R ( A , B , x ) R(A,B,x) R(A,B,x)转化为 R ( A , B , x ′ ) R(A,B,x') R(A,B,x′):
R ( A , B , x ′ ) = x ′ H B − 1 / 2 A B − 1 / 2 x ′ x ′ H x ′ R\left(A, B, x^{\prime}\right)=\frac{x^{\prime H} B^{-1 / 2} A B^{-1 / 2} x^{\prime}}{x^{\prime H} x^{\prime}} R(A,B,x′)=x′Hx′x′HB−1/2AB−1/2x′
利用前面的瑞利商的性质,我们可以很快的知道, R ( A , B , x ′ ) R(A,B,x') R(A,B,x′)的最大值为矩阵 B − 1 / 2 A B − 1 / 2 B^{-1 / 2} A B^{-1 / 2} B−1/2AB−1/2的最大特征值,或者说矩阵 B − 1 A B^{−1}A B−1A的最大特征值,而最小值为矩阵 B − 1 A B^{−1}A B−1A的最小特征值。
2. LDA的原理及推导过程
假设样本共有K类,每一个类的样本的个数分别为 N 1 , N 2 , . . . , N k N_1,N_2,...,N_k N1,N2,...,Nk
x 1 1 , x 1 2 , . . . , x 1 N 1 x_1^1,x_1^2,...,x_1^{N_1} x11,x12,...,x1N1对应第1类
x 2 1 , x 2 2 , . . . , x 2 N 2 x_2^1,x_2^2,...,x_2^{N_2} x21,x22,...,x2N2对应第2类
x k 1 , x k 2 , . . . , x k N k x_k^1,x_k^2,...,x_k^{N_k} xk1,xk2,...,xkNk对应第K类,其中每个样本 x i j x_i^j xij均为 n n n维向量
设 x ~ i j \tilde{x}_{i}^{j} x~ij为 x i j x_i^j xij变化后的样本,则 x ~ i j = < x , u > u = ∣ x ∣ ∣ u ∣ c o s θ ⋅ u = ( x T u ) u \tilde{x}_{i}^{j}=<x, u>u=|x||u|cos\theta \cdot u =\left(x^{T} u\right) u x~ij=<x,u>u=∣x∣∣u∣cosθ⋅u=(xTu)u
此处设 u u u为单位向量,即 u T u = 1 u^Tu=1 uTu=1.
假设第K类样本的数据集为 D k D_k Dk,变化后的样本的均值向量为: m ~ = ∑ x ~ ∈ D k x ~ N k \tilde{\mathrm{m}}=\frac{\sum_{\tilde{x}\in D_k}\tilde{x}}{N_k} m~=Nk∑x~∈Dkx~,那么,第K类样本的方差为 S k N k \frac{S_k}{N_k} NkSk,其中:
S k = ∑ x ~ ∈ D k ( x ~ − m ~ ) T ( x ~ − m ~ ) = ∑ x ∈ D k [ ( x T u ) u − ( m T u ) u ] T [ ( x T u ) u − ( m T u ) u ] = ∑ x ∈ D k [ ( x T u ) u T − ( m T u ) u T ] [ ( x T u ) u − ( m T u ) u ] ( x T u , m T u 为 实 数 , 转 置 仍 是 本 身 ) = ∑ x ∈ D k [ ( x T u ) 2 u T u − 2 ( x T u ) ( m T u ) u T u + ( m T u ) 2 u T u ] = ∑ x ∈ D k [ ( x T u ) 2 − 2 ( x T u ) ( m T u ) + ( m T u ) 2 ] \begin{aligned} \mathrm{S}_{\mathrm{k}} &=\sum_{\tilde{x} \in D_{k}}(\tilde{x}-\tilde{\mathrm{m}})^{T}(\tilde{x}-\tilde{\mathrm{m}})\\ &=\sum_{x \in D_{k}}\left[\left(x^{T} u\right) u-\left(m^{T} u\right) u\right]^T\left[\left(x^{T} u\right) u -\left(m^{T} u\right) u\right] \\ &=\sum_{x \in D_{k}}\left[\left(x^{T} u\right) u^{T}-\left(m^{T} u\right) u^{T}\right]\left[\left(x^{T} u\right) u -\left(m^{T} u\right) u\right] \quad (x^Tu,m^Tu为实数,转置仍是本身)\\ &=\sum_{x \in D_{k}}\left[\left(x^{T} u\right)^{2} u^{T} u-2\left(x^{T} u\right)\left(m^{T} u\right) u^{T} u+\left(m^{T} u\right)^{2} u^{T} u\right] \\ &=\sum_{x \in D_{k}}\left[\left(x^{T} u\right)^{2}-2\left(x^{T} u\right)\left(m^{T} u\right)+\left(m^{T} u\right)^{2}\right] \end{aligned} Sk=x~∈Dk∑(x~−m~)T(x~−m~)=x∈Dk∑[(xTu)u−(mTu)u]T[(xTu)u−(mTu)u]=x∈Dk∑[(xTu)uT−(mTu)uT][(xTu)u−(mTu)u](xTu,mTu为实数,转置仍是本身)=x∈Dk∑[(xTu)2uTu−2(xTu)(mTu)uTu+(mTu)2uTu]=x∈Dk∑[(xTu)2−2(xTu)(mTu)+(mTu)2]
第K类样本的方差:
S k N k = ∑ x ∈ D k ( x T u ) 2 N k − 2 ∑ x ∈ D k x T ( u m T u ) N k + ∑ x ∈ D k ( m T u ) 2 N k = ∑ x ∈ D k u T x x T u N k − 2 ∑ x ∈ D k x T N k u m T u + ( m T u ) 2 ( 注 : ∑ x ∈ D k ( m T u ) 2 N k = ( m T u ) 2 。 因 为 m T u 与 x 无 关 ) = u T ∑ x ∈ D k x x T N k u − ( m T u ) 2 ( 注 : ∑ x ∈ D k x T N k = m T ) = u T ∑ x ∈ D k x x T N k u − u T m m T u = u T ( ∑ x ∈ D k x x T N k − m m T ) u \begin{aligned} \frac{S_{k}}{N_{k}} &=\frac{\sum_{x \in D_{k}}\left(x^{T} u\right)^{2}}{N_{k}}-2 \frac{\sum_{x \in D_{k}} x^{T}\left(u m^{T} u\right)}{N_{k}}+\frac{\sum_{x\in D_{k}}\left(m^{T} u\right)^{2}}{N_{k}} \\ &=\frac{\sum_{x\in D_k} u^{T} x x^{T} u}{N_{k}}-2 \frac{\sum_{x\in D_k} x^{T}}{N_{k}} u m^{T} u+\left(m^{T} u\right)^{2}\quad (注:\frac{\sum_{x\in D_{k}}\left(m^{T} u\right)^{2}}{N_{k}}=(m^Tu)^2。因为m^Tu与x无关)\\ &=u^{T} \frac{\sum_{x\in D_k} x x^{T}}{N_{k}} u-\left(m^{T} u\right)^{2} \quad (注:\frac{\sum_{x \in D_k}x^T}{N_k}=m^T)\\ &=u^{T} \frac{\sum_{x\in D_k} x x^{T}}{N_{k}} u-u^{T} m m^{T} u \\ &=u^{T}\left(\frac{\sum_{x\in D_k} x x^{T}}{N_{k}}-m m^{T}\right) u \end{aligned} NkSk=Nk∑x∈Dk(xTu)2−2Nk∑x∈DkxT(umTu)+Nk∑x∈Dk(mTu)2=Nk∑x∈DkuTxxTu−2Nk∑x∈DkxTumTu+(mTu)2(注:Nk∑x∈Dk(mTu)2=(mTu)2。因为mTu与x无关)=uTNk∑x∈DkxxTu−(mTu)2(注:Nk∑x∈DkxT=mT)=uTNk∑x∈DkxxTu−uTmmTu=uT(Nk∑x∈DkxxT−mmT)u
各个类别的样本方差之和:
∑ k S k N k = ∑ k = 1 K u T ( ∑ x ∈ D k x x T N k − m k m k T ) u = u T ∑ k = 1 K ( ∑ x ∈ D k x x T N k − m k m k T ) u = u T S w u \begin{aligned} \sum_{k}\frac{S_k}{N_k} &=\sum_{k=1}^{K}u^{T}\left(\frac{\sum_{x \in D_k} x x^{T}}{N_{k}}-m_k m_k^{T}\right) u \\ &=u^T\sum_{k=1}^{K}(\frac{\sum_{x \in D_k}xx^T}{N_k}-m_km_k^T)u\\&=u^TS_wu \end{aligned} k∑NkSk=k=1∑KuT(Nk∑x∈DkxxT−mkmkT)u=uTk=1∑K(Nk∑x∈DkxxT−mkmkT)u=uTSwu
其中, S w = ∑ k = 1 K ( ∑ x ∈ D k x x T N k − m k m k T ) S_w=\sum_{k=1}^{K}(\frac{\sum_{x \in D_k}xx^T}{N_k}-m_km_k^T) Sw=∑k=1K(Nk∑x∈DkxxT−mkmkT), S w S_w Sw一般被称为类内散度矩阵
不同类别 i , j i,j i,j之间的中心距离:
S i j = ( m ~ i − m ~ j ) T ( m ~ i − m ~ j ) = [ ( u T m i ) u − ( u T m j ) u ] T [ ( m i T u ) u − ( m j T u ) u ] = [ ( u T m i ) u T − ( u T m j ) u T ] [ u ( m i T u ) − u ( m j T u ) ] = u T ( m i − m j ) u T u ( m i T − m j T ) u = u T ( m i − m j ) ( m i − m j ) T u \begin{aligned} S_{i j} &=\left(\tilde{m}_{i}-\tilde{m}_{j}\right)^{T}\left(\tilde{m}_{i}-\tilde{m}_{j}\right) \\ &=[(u^Tm_i)u-(u^Tm_j)u]^T[(m_i^Tu)u-(m_j^Tu)u] \\ &=[(u^Tm_i)u^T-(u^Tm_j)u^T][u(m_i^Tu)-u(m_j^Tu)] \\ &=u^T(m_i-m_j)u^Tu(m_i^T-m_j^T)u \\ &=u^{T}\left(m_{i}-m_{j}\right)\left(m_{i}-m_{j}\right)^{T} u \end{aligned} Sij=(m~i−m~j)T(m~i−m~j)=[(uTmi)u−(uTmj)u]T[(miTu)u−(mjTu)u]=[(uTmi)uT−(uTmj)uT][u(miTu)−u(mjTu)]=uT(mi−mj)uTu(miT−mjT)u=uT(mi−mj)(mi−mj)Tu
所有类别之间的距离之和为:
∑ i , j i ≠ j s i j = u T ∑ i , j i ≠ j [ ( m i − m j ) ( m i − m j ) T ] u = u T S b u \begin{aligned} \sum_{i, j \atop i \neq j} s_{i j} &= u^T\sum_{i, j \atop i \neq j}[(m_i-m_j)(m_i-m_j)^T]u \\ &=u^TS_bu \end{aligned} i̸=ji,j∑sij=uTi̸=ji,j∑[(mi−mj)(mi−mj)T]u=uTSbu
其中, S b = ∑ i , j i ≠ j [ ( m i − m j ) ( m i − m j ) T ] S_b=\sum_{i, j \atop i \neq j}[(m_i-m_j)(m_i-m_j)^T] Sb=∑i̸=ji,j[(mi−mj)(mi−mj)T], S b S_b Sb一般被称为类间散度矩阵。
在已知条件下, S w , S b S_w,S_b Sw,Sb均可求出,LDA算法的目标是“类间距离尽可能大,类内方差尽可能小”,即最大化 u T S b u u^TS_bu uTSbu,最小化 u T S w u u^TS_wu uTSwu.
令 J ( u ) = u T S b u u T S w u J(u)=\frac{u^{T} S_{b} u}{u^{T} S_{w} u} J(u)=uTSwuuTSbu,则目标函数为:
max J ( u ) \max J(u) maxJ(u)
为了使所求最大,可假设 u T S w u = 1 u^TS_wu=1 uTSwu=1,则问题转化为:
max u T S b u s . t . u T S w u = 1 \begin{array}{l}{\max u^{T} S_{b} u} \\ s.t. \quad u^TS_wu=1 \end{array} maxuTSbus.t.uTSwu=1
L ( u , λ ) = u T S b u + λ ( 1 − u T S w u ) ∂ L ∂ u = S b u + S b T u − λ S w u − λ S w T u = 2 ( S b u − λ S w u ) ( 因 为 S b , S w 为 对 称 矩 阵 ) = 0 ⇒ S b u = λ S w u \begin{aligned} L(u, \lambda)&=u^{T} S_{b} u+\lambda\left(1-u^{T} S_{w} u\right) \\ \frac{\partial L}{\partial u} &= S_bu+S_b^Tu-\lambda S_wu-\lambda S_w^Tu \\ &=2(S_bu-\lambda S_wu)\quad (因为S_b,S_w为对称矩阵)\\ &=0 \Rightarrow S_{b} u=\lambda S_{w} u \end{aligned} L(u,λ)∂u∂L=uTSbu+λ(1−uTSwu)=Sbu+SbTu−λSwu−λSwTu=2(Sbu−λSwu)(因为Sb,Sw为对称矩阵)=0⇒Sbu=λSwu
证明 S b S_b Sb为对称矩阵:
S b T = ( ∑ i , j i ≠ j [ ( m i − m j ) ( m i − m j ) T ] ) T = ∑ i , j i ≠ j [ ( m i − m j ) ( m i − m j ) T ] T = ∑ i , j i ≠ j [ ( m i − m j ) ( m i − m j ) T ] = S b \begin{aligned} S_b^T &= (\sum_{i, j \atop i \neq j}[(m_i-m_j)(m_i-m_j)^T])^T\\ &=\sum_{i, j \atop i \neq j}[(m_i-m_j)(m_i-m_j)^T]^T \\ &=\sum_{i, j \atop i \neq j}[(m_i-m_j)(m_i-m_j)^T] \\ &=S_b \end{aligned} SbT=(i̸=ji,j∑[(mi−mj)(mi−mj)T])T=i̸=ji,j∑[(mi−mj)(mi−mj)T]T=i̸=ji,j∑[(mi−mj)(mi−mj)T]=Sb
所以, S b S_b Sb为对称矩阵,同理可证明 S w S_w Sw为对称矩阵。
S w − 1 S b u = λ u \begin{array}{l} S_{w}^{-1}{S_{b} u=\lambda u} \end{array} Sw−1Sbu=λu
计算矩阵 S w − 1 S b S_w^{-1}S_b Sw−1Sb的最大的 d d d个特征值和对应的 d d d个特征向量 ( w 1 , w 2 , . . . , w d ) (w_1,w_2,...,w_d) (w1,w2,...,wd),得到投影矩阵 W = ( w 1 , w 2 , . . . , w d ) W=(w_1,w_2,...,w_d) W=(w1,w2,...,wd)。
注意: (1)选取特征值时,如果一些特征值明显大于其他的特征值,则取这些取值较大的特征值,因为它们包含更多的数据分布的信息。相反,如果一些特征值接近于0,我们将这些特征值舍去。
(2)由于 W W W是一个利用了样本类别得到的投影矩阵,因此它能够降维到的维度d的最大值为 K − 1 K-1 K−1。为什么不是 K K K呢?因为 S b S_b Sb中每个 m i − m j m_i-m_j mi−mj的秩均为1(因为 m i m_i mi为1维向量).由 R ( A B ) ≤ min ( R ( A ) , R ( B ) ) R(AB)\leq \min(R(A), R(B)) R(AB)≤min(R(A),R(B))知,
R ( ( m i − m j ) ( m i − m j ) T ) = 1 R((m_i-m_j)(m_i-m_j)^T)=1 R((mi−mj)(mi−mj)T)=1
又 ∵ \because ∵
S b = ∑ i , j i ≠ j [ ( m i − m j ) ( m i − m j ) T ] , R ( A + B ) ≤ R ( A ) + R ( B ) S_b=\sum_{i, j \atop i \neq j}[(m_i-m_j)(m_i-m_j)^T], \\R(A+B)\leq R(A)+R(B) Sb=i̸=ji,j∑[(mi−mj)(mi−mj)T],R(A+B)≤R(A)+R(B)
∴ R ( S b ) ≤ K − 1 ⇒ R ( S w − 1 S b ) ≤ K − 1 \therefore R(S_b)\leq K-1 \Rightarrow R(S_w^{-1}S_b)\leq K-1 ∴R(Sb)≤K−1⇒R(Sw−1Sb)≤K−1
∴ λ = 0 \therefore \lambda =0 ∴λ=0对应的特征向量至少有 ( K − ( K − 1 ) ) = 1 (K-(K-1))=1 (K−(K−1))=1个,也就是说 d d d最大为 K − 1 K-1 K−1.
3. LDA算法流程
输入:数据集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) D={(x_1,y_1),(x_2,y_2),...,(x_m,y_m)} D=(x1,y1),(x2,y2),...,(xm,ym),其中,任意样本 x i x_i xi为 n n n维向量, y i ∈ { C 1 , C 2 , . . . , C k } y_i\in \{C_1,C_2,...,C_k\} yi∈{C1,C2,...,Ck},降维到的维度为 d d d.
输出:降维后的数据集 D ′ D' D′.
- 计算类内散度矩阵 S w S_w Sw
- 计算类间散度矩阵 S b S_b Sb
- 计算矩阵 S w − 1 S b S_w^{-1}S_b Sw−1Sb
- 计算矩阵 S w − 1 S b S_w^{-1}S_b Sw−1Sb的特征值与特征向量,按从小到大的顺序选取前 d d d个特征值和对应的 d d d个特征向量 ( w 1 , w 2 , . . . , w d ) (w_1,w_2,...,w_d) (w1,w2,...,wd),得到投影矩阵 W W W.
- 对样本集中的每一个样本特征 x i x_i xi,转化为新的样本 z i = W T x i z_i=W^Tx_i zi=WTxi
- 得到输出样本集 D ′ = { ( z 1 , y 1 ) , ( z 2 , y 2 ) , . . . , ( z m , y m ) } D'=\{(z_1,y_1),(z_2,y_2),...,(z_m,y_m)\} D′={(z1,y1),(z2,y2),...,(zm,ym)}
4. LDA与PCA对比
LDA与PCA都可用于降维,因此有很多相同的地方,也有很多不同的地方
-
相同点:
- 两者均可用于数据降维
- 两者在降维时均使用了矩阵特征分解的思想
- 两者都假设数据符合高斯分布
-
不同点:
- LDA是有监督的降维方法,而PCA是无监督降维方法
- 当总共有K个类别时,LDA最多降到K-1维,而PCA没有这个限制
- LDA除了用于降维,还可以用于分类
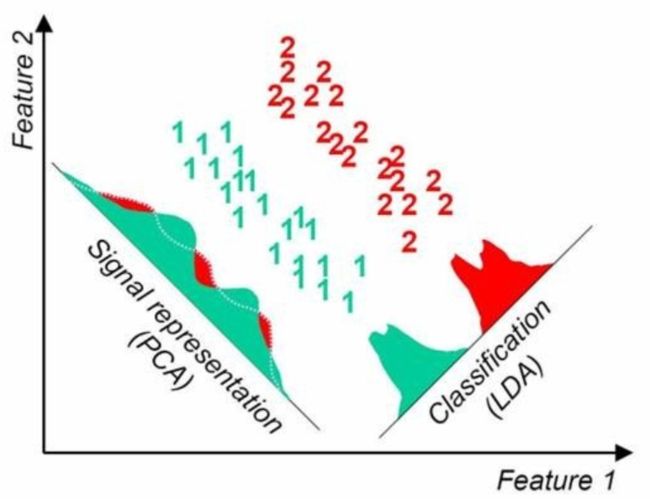
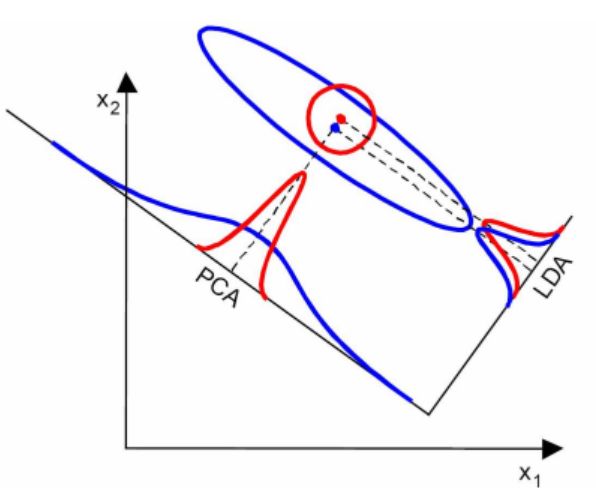
- LCA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。这点可以从下图形象的看出,在某些数据分布下LDA比PCA降维较优(如下图的左图)。当然,某些数据分布下PCA比LDA降维较优(如下图的右图)。
|
|
5. LDA算法小结
LDA算法既可以用来降维,也可以用来分来,但是目前来说,LDA主要用于降维,在进行与图像识别相关的数据分析时,LDA是一个有力的工具。下面总结一下LDA算法的优缺点。
- LDA算法的优点
- 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习无法使用先验知识;
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA算法较优。
- LDA算法的缺点
- LDA与PCA均不适合对非高斯分布样本进行降维
- LDA降维算法最多降到类别数K-1的维度,当降维的维度大于K-1时,则不能使用LDA。当然目前有一些改进的LDA算法可以绕过这个问题
- LDA在样本分类信息依赖方差而非均值的时候,降维效果不好
- LDA可能过度拟合数据
参考:https://www.cnblogs.com/pinard/p/6244265.html