【梳理】简明操作系统原理 第五章 内存管理(二):分页(内含文档高清截图)
参考教材:
Operating Systems: Three Easy Pieces
Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau
在线阅读:
http://pages.cs.wisc.edu/~remzi/OSTEP/
University of Wisconsin Madison 教授 Remzi Arpaci-Dusseau 认为课本应该是免费的。
————————————————————————————————————————
这是专业必修课《操作系统原理》的复习指引。
在本文的最后附有复习指导的高清截图。需要掌握的概念在文档截图中以蓝色标识,并用可读性更好的字体显示 Linux 命令和代码。代码部分语法高亮。
————————————————————————————————————————
笑,老子一个字一个字自己整理的读书笔记,你们居然告诉我版权不明?
————————————————————————————————————————
勘误
1、(第7点)LRU(least-recently used)淘汰的是最长时间没有被使用的页面。
在我做完整本书的复习指导后,会发布订正错误后的文档,包含所有章节。
五 内存管理(二):分页
1、有时我们说,操作系统在内存空间管理上有两种方法:第一种是把空间切成变长的小片,例如分为不同大小的段。但这种方法容易因为段长不同而引起碎片。第二种方法则是分为固定大小的小片,称为分页(paging)。一页对应物理内存中的同样大小的一块空间,称为页帧(page frame),有时简称帧(frame)。分页机制是虚拟地址机制的实现基础,使得为进程划分地址空间(AS)变得更高效,也使得管理空闲内存的流程更简化。
正确实现分页机制需要硬件和软件的配合。OS维护一个空闲列表,表中记录了所有的空闲内存页。此外,物理内存中还有页表(page table),存放逻辑页与物理页帧的对应关系。每个进程都有自己的页表,进程控制块中存有指向页表的指针。
2、在Linux的终端下输入命令:
getconf PAGE_SIZE
显示值:4096。Linux的页大小一般是4 KB。在内存管理相关的信息中,不可能将每一个字节都精确记录下来,否则这些信息占用的空间会远远超过内存的总空间,所以必须分成“一块一块”的结构进行整体管理。只记录页及相关的关系,记录量就缩小到了原来的大约1 / 4000。
3、进行地址翻译时,虚拟地址被拆成两段:虚拟页号(virtual page number,VPN)和偏移(offset)。页大小是4 KB时,偏移就有12位(212 = 4096)。虚拟页号会被转换成物理页号(physical page number,PPN),又称物理帧号(physical frame number,PFN)或物理块号,偏移则不翻译。
4、页表可以非常大。如果计算机中正在运行一个大型应用,其进程的地址空间一共4 GB,那么就有220页。页表项(page table entry)要记录哪些信息呢?
首先是物理帧号。以Intel Core-i5 8400(笔者的机器的CPU)为例,其物理地址开启了39位,就有27位来标识页帧。
此外,需要1位有效位来刻画这个页是否有效(是否在内存中)。如果地址空间中的这个页未被使用,它会被记无效。当尝试访问被标记为无效的页面时,就会触发陷阱指令,OS可能结束这个进程。用有效位来标记内存页还有另一个好处,就是无需将无效页与页帧建立关联,节省了内存并改善了性能。
还有3位表示权限(读、写、执行)。
1位引用位(reference bit),又称访问位(accessed bit),用于描述一个页是否经常被访问。
有1位present bit,用于刻画这个页是在内存上还是在磁盘上(如果被交换到磁盘,交换用于使用比物理内存大的地址空间,在后续会提到)。
可能还有1位dirty bit,表示这一页是否已修改且未存入磁盘。
1位用户/管理员(U/S)位,描述在用户模式下该页是否可以访问。
PWT,PCD,PAT,G共4位,与该页的硬件缓存有关。
仅仅是这些就占用了39位(实际需要5字节)了,220个条目总共需要5 MB的空间。如果还记录其它信息,页表只会更大。假设你的计算机中一共有300个进程在运行,那么页表的总大小还是很可观的。
如果直接将页表存储在MMU中,成本是完全不可以接受的,所以页表都保存在内存里。
关于x86架构的分页机制,详情参阅Intel Architecture Manuals。
Intel CPU的分页机制中,只有present bit而没有valid bit。当访问一个不在内存中的页时,触发陷阱指令,OS运行相应过程去判断该页是否有效。
5、每次进行内存访问时,都要先查找页表,然后再访问对应的物理页。也就是说实际执行了两次内存访问。由于绝大多数操作都要进行内存访问,因此开销是比较大的。
考虑下面的程序:
int a[1000];
for (int i = 0; i < 1000; ++i)
a[i] = 0;
将其编译:
1024 movl $0x0,(%edi,%eax,4)
1028 incl %eax
1032 cmpl $0x03e8,%eax
1036 jne 0x1024
第1行,寄存器%edi和%eax分别代表数组的首地址和下标,转换为内存地址的时候,%eax中的内容要乘以4,因为数组的每个元素是int类型的,一个占4字节。
第2行,下标增加1。
第3、4行,03e8h转为十进制是1000。判断下标是否达到1000,如果未达到,则通过下一条指令跳回到循环开头。(原教材上把每个命令占的大小统一写成了4字节,不过实际上x86指令是变长的)
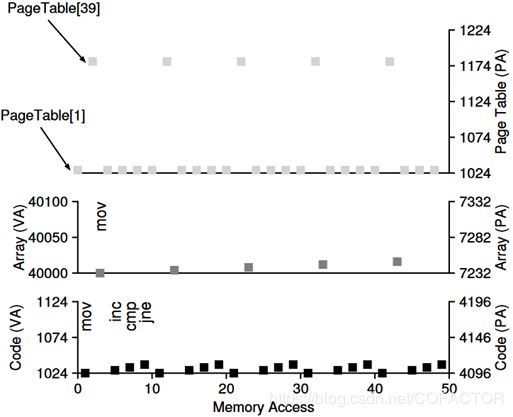
假设页表是线性表(数组),且页大小是1 KB。那么地址1024位于页表的第二项,即VPN = 1(第一项的VPN为0)。而数组的内容一共4000字节,假设位于虚拟地址的40000到43999字节,VPN分别为39到42,映射到PPN为7到10的物理页。
在本例中,每一次取指令时,都要做2次内存访问:1次是查找页表获得物理页,1次是到实际地址取指令。一个mov指令还需要额外的2次内存访问:通过查找页表先把数组的虚拟地址转换为物理地址,然后数组访问自己。于是,单次循环一共要进行10次内存访问,4次取指令、1次更新内存内容分别贡献8次和2次。内存的访问情况可以用如下的图表表示:横轴为已进行的内存访问次数,纵轴的左右两侧分别为虚拟地址和物理地址。一个正方形点代表一次内存访问。
6、既然每次内存访问都会因为地址翻译导致很大的开销,那么如何加速呢?自然要与硬件协同。翻译后备缓冲(translation-lookaside buffer,TLB)是MMU的一部分。这是一种硬件缓存(cache),用于加速虚拟地址到物理地址的转换。也许更合适的名字应该叫地址翻译缓存(address-translation cache)。每次内存访问时,硬件先检查TLB中是否已经保存了翻译结果;若是,就不用再查询页表,称为TLB命中(TLB hit)。否则称TLB未命中(TLB miss)。
对数组的顺序访问是TLB命中率较高的情况。页大小为4 KB时,一页可以装下1024个int型的数组元素,当这一页的翻译结果保存在TLB中时,如果先前未访问过数组的这一部分,且TLB总是保存最近的访问结果,那么访问这1024个元素只需要查1次页表,对访问速率的提升非常明显。数组的顺序1访问在程序中总是可以涉及到的,这是空间局部性(spatial locality)的一个典例。如果需要循环访问这个数组许多次,且这个数组所在的页都在TLB中存在对应的物理页,那么访问速率又获得了进一步提升。循环在程序中也是总是可以涉及到的,是时间局部性(temporal locality)的一个典例。
7、缓存是计算机系统中极为重要的一种用于性能提升的架构。缓存是根据局部性原理设计出来的,用于保存常常访问到的内容(数据和指令)。但是如果缓存的容量过大,不但成本巨大,对性能提升也变得非常弱(边际递减)。所以缓存总是设计得比较小,以期获得成本和性能的平衡。
8、早期的CISC(complex-instruction set computers,复杂指令集计算机)中,硬件设计者不信任操作系统的设计者,因此硬件会处理TLB未命中的情形。MMU中含有页表基址寄存器(page-table base register),保存了页表在内存中的位置。当TLB未命中时,MMU就查询页表。现代更多采用RISC(reduced-instruction set computers,精简指令集计算机),TLB是由软件管理的。当TLB未命中时,硬件产生异常,暂停指令流并切换到内核模式,开始运行陷阱处理程序。这一部分就交由操作系统负责:查询页表,并将查询结果保存到TLB中,然后从陷阱返回。不过返回后的操作有些不同:从系统调用返回时,执行下一条指令,就像从一般的过程调用返回后那般;从TLB未命中处理的陷阱返回后,重试引发陷阱的指令,获得一次TLB命中。
由于从陷阱返回后需要重试引发陷阱的指令,因此要避免因为未命中造成无限循环。方法有很多:例如内存中的TLB未命中处理程序所在的页不进行映射,或将其对应的实际地址总是保留在TLB中。
9、软件控制的TLB未命中处理程序的第一个优点就是灵活性(flexibility):可以自由使用合适的数据结构实验页表并随时调整而不用改变硬件结构。另一个优点就是能简化硬件的设计。
10、1980年代,有一场计算机架构之争。一方是CISC阵营,另一方是RISC阵营。RISC阵营的带头人是UC Berkeley的David Patterson和Stanford University的John Hennessy。后来John Cocke因为对RISC的最早贡献而获得Turing Award。
CISC的特点是指令数量多,且每个指令的功能非常强。CISC背后的思想是:指令应该是高级原语,使得汇编语言更易用,且代码更短。
RISC的特点则是相反的。RISC主张指令集是编译器负责的,所有编译器都只需要少量的原语用来最终生成高性能的代码。所以RISC的支持者认为要从硬件中剔除尽可能多的内容(尤其是微码),只留下尽可能简单的、快的、统一的东西。
当时,RISC对整个计算机领域造成了非常大的冲击,且非常多的论文显示RISC快得多。但是随着时间推移,以Intel为代表的CISC厂商引入了很多RISC特性。例如引入流水线来将复杂指令集转换成微指令,并用类似RISC的方式处理。这是CISC依然能保持竞争力的重要原因。最终的结果是,直到现在,CISC和RISC都能达到很快的速度,它们在微观层面也越来越接近。
原语(primitive)是一种由若干条指令组成的程序,用于实现某个特定的底层操作。原语的执行是不可以暂停的,且一般必须在内核模式下执行。
微码(microcode)又称微指令,是在CISC结构下,运行一些功能复杂的指令时,所分解出的一系列相对简单的指令。微指令的作用是将机器指令与相关的电路实现分离,这样一来机器指令可以更自由地进行设计与修改,而不用考虑实际的电路架构。与其他方式比起来,使用微指令架构可以在降低电路复杂度的同时,建构出复杂的多步骤机器指令。撰写微指令一般称为微程序设计(microprogramming),而特定架构下的处理器实做中微指令有时会称为微程序(microprogram)。
现代的微指令通常由CPU工程师在设计阶段编写,并且存储在只读内存(ROM,read-only-memory)或可编程逻辑数组(PLA,programmable logic array)中。有些机器会将微指令存储在SRAM或是闪存(flash memory)中。它通常对普通程序员甚至是汇编语言程序员来说是不可见的,也是无法修改的。与机器指令不同的是,机器指令必须在同一系列(E.g. Intel Core系列)的不同处理器之间维持兼容性,而微指令只设计成在特定的CPU架构下运行,成为特定CPU设计的一部分。
微码所指代的代码一般比固件(firmware)更底层。
11、TLB是全相联映射高速缓存(fully-associative cache),也就是说内存中的一个地址可以保存在TLB中的任意一个位置而不是只能保存在特定位置。TLB主要含有:虚拟页号(VPN)、物理页号(PPN)、有效位、保护位(刻画对应的内存页是否可以读写或执行),以及其它信息(地址空间标识符、dirty bit等)。例如:一种MIPS处理器的TLB中有一个全局位(global bit),当其设为1时,ASID会被忽略,因为这代表对应的页为全部进程所共享。
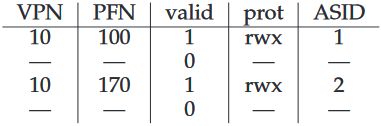
12、页表和TLB中的有效位代表的意义是不同的。访问内存中的无效页是非法操作。在系统启动时,TLB中全部的有效位都为无效,因为还没有任何页的翻译结果保存在TLB中。当虚拟地址机制启动后,有效的项才写入TLB。TLB有效位在上下文切换时很有用,将在接下来讨论。当所有TLB中的项都为无效时,系统就能确保接下来要运行的进程不会使用上一个进程的翻译结果。
如图,假设第一个进程的第10页对应第100个物理帧。第二个进程的第10页对应第170个物理帧,这一项在上下文切换时被载入TLB。当进行地址翻译时,如果以页号10为条件进行查找,就有超过1个匹配项。怎样处理呢?一种方法是在上下文切换时清除TLB中的内容。另一种方法是只将属于全部项的有效位标记为无效。在翻译时,MMU要知晓当前正在运行的是哪个进程。还有一种方法是在TLB中记录地址空间标识符(address space identifier,ASID)。ASID与PID类似,但一般比PID短。翻译时可以通过ASID区分进程。
当两个进程共享一个页时,两个不同的VPN就可能对应同一个PFN。这种情况可以节省内存并提升性能。
13、当TLB已满时,如果需要记录新的项,就需要将原有的项替换。最近最少使用(least-recently-used,LRU)算法将访问次数最少的页对应的项移除。还有一种方法是随机移除一项,这种方法一定程度上可以避免其它方法在最坏情况下性能显著降低的问题。例如:如果一个程序循环n + 1页的范围,但TLB只能记录n个条目,那么如果采用LRU算法,就会移除最开始进入的那一页(访问次数相同时,移除最久远记录的一项),于是在TLB记满以后,接下来的每一次内存访问都不会发生TLB命中。如果随机去掉一项记录,性能显然要好得多。
14、一个页表的大小可能达到几个MB。如果系统中有数百个进程,页表还是占了不少的内存。怎样缩小页表呢?
一种简单粗暴的方法是增加页大小。假如我们把页大小从4 KB增加到16 KB,那么在占用同样空间的情况下,一个进程的总页数就是由原来的1 / 4。但是过大的页大小会严重浪费空间(产生了内部碎片):如果一个程序申请新空间比较多,但每次只申请很少,然而内核接收到请求时总是至少分配一页,这样就造成了许多页都有大量空间实际上未被利用。
另一种方法就是把页表和堆混用。我们知道,许多情况下栈和堆之间有比较多的空间是未利用的。当页表为线性表时,中间也有比较多的位置没有记录内容。于是可以把代码段、栈段和堆段各记录一个页表,于是就把一个比较大但利用率低的页表转换为了三个比较小但利用率较高的页表。不过,这个方法并不是没有问题的。如果堆中的空间也有许多是没有被利用的,那么新的页表中还会有很多空余。此外,分段会造成外部碎片。而且段的大小不一也使分配空间的方案要更复杂。
15、现代计算机中,一般采用多级页表(multi-level page table)来减少页表的大小。首先把页表按页大小也分成若干页,然后用页目录(page directory)来记录页表的每一页的信息。页目录项(page directory entry,PDE)有一个有效位和一个页帧号记录每一页页表在内存中的位置。当有效位为无效时,代表对于的页表的这一部分没有存储任何条目,这部分页表实际上不会被分配内存空间,且该页目录项中不会定义页帧号。
多级页表的优点有:一是节省了内存。二是将页表也按页划分,方便内存管理:不需要用一大片连续的内存存放页表,而且扩张页表的时候OS只需要分配新的一页给页表就可以了。三是对稀疏地址空间支持得很好。
不过多级页表并不是没有额外代价的:当TLB未命中发生时,进行地址翻译需要两次内存访问。此外还有一种非常极端的最坏情形:页表的每一页都只有一个条目。这时对节省空间亦是毫无效果。
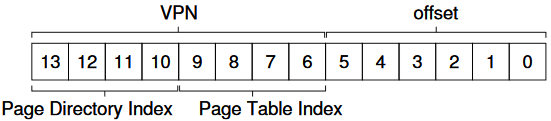
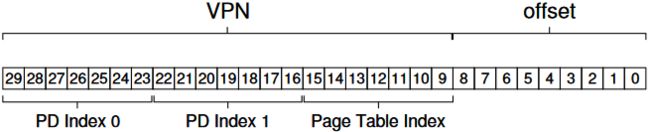
具体实现的时候,可以按照页大小将高几位视为页目录索引,找到页表的相应部分后,剩下的位数的高几位视为页表索引。页目录索引和页表索引就可以直接构成页号。剩下的位数就用作精确到字节的定位(页内偏移)。
从下面的例子中,可以看出进程空间为16 KB,页大小为64 B,一共分成256页,页表被分成16页,每页16项。
如果页目录也很大,那么可以按照类似的方案把页目录再进行划分。
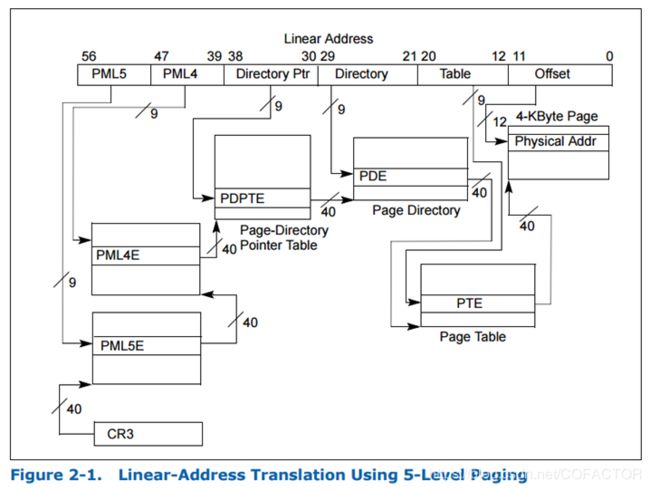
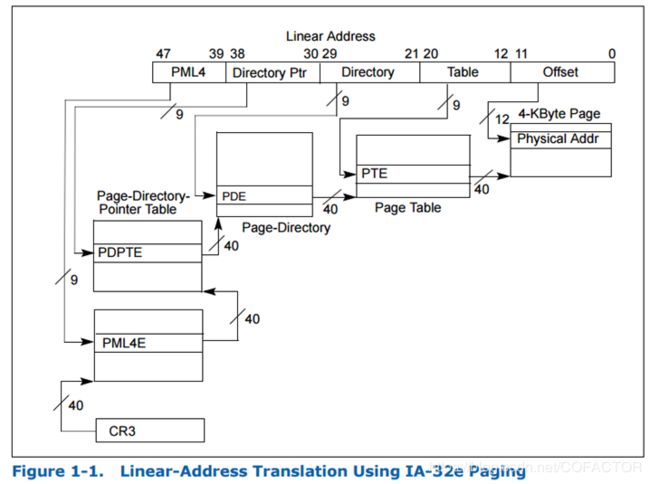
现有的Intel处理器支持4级分页,线性地址位数最多48位:
日后的Intel处理器将会启用对5级分页的支持,Linux内核也将默认启用5级分页。
16、在编写代码的时候要注意:不能因为降低复杂度而大幅降低开发速率、代码的可读性和可维护性。例如:当磁盘空间非常充足的时候,没有必要花费大量心思将文件系统的控制精确到字节;CPU非常快时,一般也不需要将大量的过程都用汇编语言手写并深度优化。这个思想一定要贯彻到计算机编程的方方面面。典型的例子就是C++和Python:Python代码的运行速率远远慢于C++,但用Python开发同一个程序比用C++快得多,且学习Python的门槛更低。当开发一个小规模爬虫的时候,使用C++写爬虫并不会获得太大的性能提升;但是大规模的高性能爬虫一般使用C++编写。一个优秀的程序员应该具备在代码性能和可读性、可维护性之间取得良好平衡的能力:牺牲痕迹量的性能和使代码因为优化变得面目全非这两者之间,一般都要选择后者。但为了充分压榨出性能而不惜大幅降低可读性的例子也有很多,这些代码一般都被高度封装成库函数。例如C++ STL中的快速排序就是高度优化的代码。在C++11以前,其期望时间复杂度为O(n log n),最坏时间复杂度为O(n2);而C++11开始,快速排序算法被大幅改进,其最坏复杂度也不会超过O(n log n)。在机器学习、计算机图形学、基础科研等领域,需要大量用到矩阵运算。于是矩阵运算被大幅度加速,OpenBLAS和cuBLAS是深度优化线性代数运算的例子。cuBLAS在底层采用汇编级优化,与GPU配合,最终实现了矩阵运算的速率以数量级进行提升。
17、反向页表(inverted page table)也是一种节省空间的方式。反向页表只有一张页表,每个物理页占一个条目,相当于页帧为key,页为value。但每次需要获得物理地址时,进程给出的都是虚拟地址。由于反向页表是通过物理页索引的,因此根据虚拟地址遍历整张表查出对应的物理地址非常耗时。所以,通常采用哈希表来加速查找。采用反向页表的CPU主要有UltraSPARC和PowerPC。










![]()
![]()
![]()