【梳理】计算机组成与设计 第1章 计算机中的常见概念(内附文档高清截图)
配套教材:
Computer Organization and Design: The Hardware / Software Interface (5th Edition)
第一章 计算机中的常见概念
这一章的内容是概述性的。有些概念解释起来比较复杂,将在后面的章节进一步学习,如果一时理解不了也没关系,可以结合搜索引擎和日后的深入学习慢慢消化。
1、下面介绍贯穿计算机科学的八个重要思想:
·摩尔定律(Moore’s Law)。这是Intel的创始人之一Gordon Moore提出的,其内容是:集成电路(Integrated circuit,IC,也叫芯片(chip))中的晶体管数量每隔18到24个月翻一倍。
·抽象(abstract)方法。为了缩短延长趋势越来越明显的开发周期,在不同的层面上采用不同的抽象模型来简化设计过00程:高级层面的模型会隐去低级层面的细节。例如把频繁使用的算法写成函数、用常见的逻辑门设计数字电路时大都不考虑晶体管层面怎样实现逻辑门。
·针对最常见的情况进行优化。为了使计算机在多数时间内表现出更好的性能,应该优先选择常见的情况进行针对性优化。对常见场景的优化的困难程度往往低于对个别极端情况的优化。
·并行(Parallelism)。同时执行尽量多的指令。
·流水线化(Pipelining)。流水线已经成为芯片的必备设计,用于并行执行。将在后续的章节进一步学习流水线技术。
·预测执行。有一句话是这样说的:“请求饶恕比请求批准更好。”(It can be better to ask for forgiveness than to ask for permission.)猜测接下来需要执行的可能性更大的指令并提前执行,而不是让芯片空转。虽然误预测的代价较大(清空流水线并重新执行一系列指令),但预测执行的平均表现更好。
·层次化存储。程序员们总是渴望又快又大又便宜的存储。但高速存储(如:缓存)的成本巨大,大容量的存储(如:硬盘(Hard Disk Drive,HDD))虽然花费低,但性能远远不足。容量和性能往往又不能兼顾。一个缓和这些矛盾的方法是:设计不同层次的存储。不同层次的存储可以用金字塔表示。顶端是速度快、容量小、价格贵的存储(寄存器、多级缓存);次一级是内存,成本降低、速度减慢、容量提升;再低一级是外存(HDD / SSD(Solid State Drive,固态盘)),成本更低、速度更慢、容量更大。
·冗余(Redundancy)。设备具有一定几率损坏(也可能是毫无前兆的暴毙)。在计算机系统中添加多个相同功能的设备(例如:多备份、多电源),确保在部分设备损坏时,一般不至于影响系统运行,并为修复争取时间。
2、系统软件众多,也有不同的分类方法。但所有的计算机一定有两种软件:操作系统(Operating System,OS)和编译器(Compiler)。
操作系统是用户程序和硬件之间的接口,并提供一系列权限级功能,包括但不限于:
·处理基本的输入输出(IO)操作。
·分配内存和外存。
·在多个应用共享计算机时提供必要的保护。
Windows是大家常见的操作系统。除了Windows以外,还有一系列类UNIX系统(Linux、FreeBSD、Solaris、Minix等)。Android是基于Linux的操作系统,多用于手机等移动设备。iOS和Mac OS X基于类UNIX系统Darwin。
编译器负责将高级语言(如:C,C++)编写的程序转变为低级语言,再进一步转换为机器指令,使得程序可以被计算机执行。
3、目前的计算机都是采用二进制(binary)的。计算机只认识0和1两种代码,每个0或1称为二进制位(binary digit),简称位(bit)。我们令计算机执行的要求,称为指令(instruction)。一切指令和数据都用二进制表示。
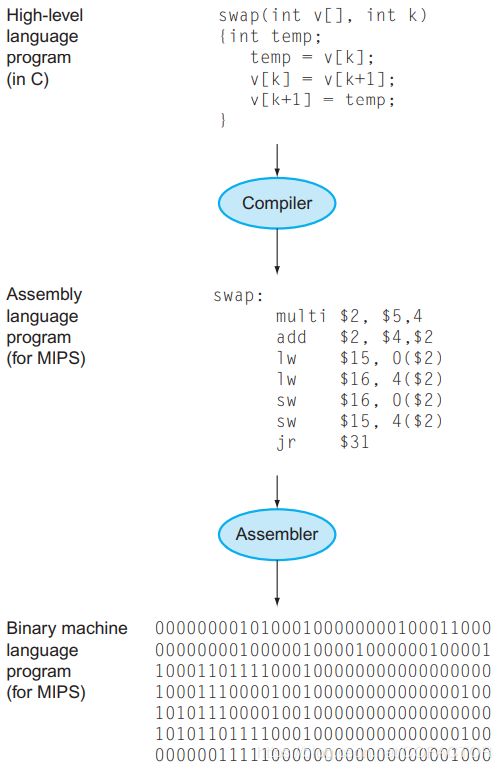
计算机刚诞生时,程序员直接用二进制编写机器指令让计算机执行。这个过程复杂且易错。后来人们发明了汇编器(assembler)和汇编语言(assembly language)。汇编语言是机器语言的助记符,汇编器负责把汇编语言转换为机器语言(machine language)。只有机器语言才可以直接被计算机执行。
当然,汇编语言使用起来还是不够方便。汇编语言强迫程序员按照计算机的思维而非人类的常用思维去编写程序。后来,高级语言(high-level programming language)出现了。高级语言也属于一种抽象。
编译器会将高级语言转换为汇编语言,然后用汇编器转换为目标代码,再经过链接器(linker)生成机器代码。
高级语言使用英语单词和代数符号,比汇编语言更加接近自然语言。不同风格的高级语言具有不同的用途。Fortran用于科学计算,Cobol则多用于商业,Lisp用于符号操作。也有许多只有特定领域才使用的语言。使用高级语言大大缩短了开发周期,降低了学习门槛,为计算机及其编程的大规模应用奠定了基础。而且高级语言一般是平台无关的,使用高级语言中跨平台性强的部分可以仅通过一次编程就同时完成对多个平台的程序的编写。编译器和汇编器则负责在各个平台上将高级语言转换为二进制指令。
4、输入设备(input device)是指向计算机提供信息的设备,例如鼠标、键盘、麦克风。输出设备(output device)是指从计算机输出信息的设备,例如显示器、蜂鸣器、音响。输入设备和输出设备,合称输入/输出设备(I/O device)。
5、像素(pixels,px)是显示的基本单位。现代计算机中,每个像素一般至少占24个bit。每8个bit代表一种颜色(红(R)、绿(G)、蓝(B))的亮度,我们把每一像素的每种颜色所用的位数称为色深(color depth)。如果用8个bit来刻画一种颜色,色深为8-bit。有时候,表示一个像素会引入第四个通道,即透明度(alpha)。8-bit的色深一共可以表示224 = 16777216种颜色。有的专业显示器能够输出10-bit色深的图像,能够显示的颜色总数达到1073741824种。
我们用分辨率(resolution)来表示一张图片、一段视频的画面或者一台显示器包含的像素有多少。例如:蓝光光盘(Blu-ray Disc,BD)的视频部分的分辨率可以达到3840×2160,即横向3840个像素,纵向2160个像素。
6、为了暂存需要显示的内容,计算机中必须包含光栅刷新缓存(raster refresh buffer),也称帧缓存(frame buffer),又称显存(VRAM)。
7、中央处理单元(Central Processing Unit),也称处理器(processor),是计算机的核心部件之一。CPU用于执行输入的指令。具体一点来说,主要是负责处理数据和进行控制。
8、动态随机访问存储器(dynamic random access memory,DRAM)当前被用作计算机的内存。内存用于暂时存储将要保存的数据,或者准备执行的代码。相对随机访问而言,磁带(magnetic tape)就是一种顺序访问的存储器。要访问磁带上距离当前读取的位置较远的地方的数据,需要经过长时间的倒带。但访问DRAM中的任何一个区域的耗时理论上是相同的。
9、高速缓存(cache),简称缓存,是一种容量小、速度极快的存储器。CPU中的缓存一般是静态随机访问存储器(static random access memory,SRAM)。SRAM的速度远远快于DRAM,但是成本很高。
10、指令集架构(instruction set architecture,ISA),简称架构(architecture),是连接硬件和最低层次的软件的抽象模型,包含了编写能够正确执行的机器语言的全部信息,包括指令集、寄存器、内存访问特性、IO模型等。不同ISA的CPU有性能和存储容量的差别,但二进制机器语言一般互相兼容。常见的ISA有x86、ARM、MIPS、SPARC等。
ISA可以扩展,扩展后的ISA可以执行原有ISA的全部指令,但原有的ISA不支持扩展后的ISA特有的指令。例如x86指令集架构的64位扩展为x86-64,简称x64。
例如:Intel的Core i3、i5、i7、i9都是x86-64指令集架构。一段能在Core i3-8100 CPU上运行的机器代码,也能在Core i9-10980XE CPU的机器上跑。但也有例外,例如有的游戏或科学计算软件要求CPU至少具备AVX2指令集,那么这些软件就只能在第四代及以上的Core CPU(如:Core-i3 4130)上运行。
11、应用程序二进制接口(application binary interface,ABI)一般是一个库(library)或者是操作系统的一部分,包含了应用程序在该系统下运行时必须遵守的编程约定,比如各种数据类型的大小、对齐方式,以及指令集,还有调用约定(如:函数参数和返回值如何传递,是全部压入栈中还是有一部分保存在寄存器内;哪个函数参数用哪个寄存器;第一个参数是最先还是最后压入栈中,等),应用程序如何进行系统调用(system call),系统调用码,等等。
12、有的存储器是易失性的(volatile),比如DRAM。在计算机断电后,其中的数据很快丢失。磁盘、光盘和闪存(flash memory)都是非易失性(nonvolatile)存储。DRAM损坏的几率非常低,但flash的寿命则具有限制。
13、局域网(Local area network,LAN)用于小范围(如:家庭、学校、公司、工厂等)的网络连接。广域网(Wide area network,WAN)则超越了局域网的通信范围,成为当今互联网的主干。以太网(Ethernet)是常用的局域网技术,由IEEE 802.3规定。后来无线网络(由IEEE 802.11协议规定)发展起来,万物互联的物联网(Internet of Things,IOT)也在酝酿之中。
14、晶体管(transistor)是集成电路的基本组件。一个IC包含大量的晶体管,例如GA100 GPU芯片一共有542亿晶体管。规模较大的IC有一个专门的名词来描述:超大规模集成电路(Very large-scale integrated circuit,VLSI)。
15、下面简单介绍芯片的生产过程:
首先要从沙子中提取硅(silicon)。硅的导电性能不如金属导体,称为半导体(semiconductor)。然后,用特殊的化学过程进行处理,添加新的材料,使得许多微小的区域或导电,或绝缘,或可以通过开关控制导电性。
纯度极高的单晶硅会被制成硅锭,然后制成晶圆(wafer),作为制造IC的衬底(基片)。一片晶圆的直径多为8英寸或12英寸(以后可能有18英寸的晶圆),厚度不超过3 mm。晶圆经过几十道工序以后,上面就会按照设计好的图案形成晶体管、导体、绝缘体,这个过程称作光刻(lithography)。IC一般只有一层晶体管,但是有多层金属导体,用绝缘体分隔。刻好电路的晶圆会进行测试,将不合格的裸芯片(die)降级或报废。测试通过的芯片会进行封装(package),然后再进行测试,选出最终的合格品销售给客户。
(上图是已经蚀刻好电路的Core i7芯片的晶圆,完整芯片的大小是20.7 mm×10.5 mm,共280片)
晶圆被做成圆形,是制作工艺决定的。提出高纯度的单晶硅以后,可能会把单晶硅切下一个平角(flat),或者只切一个小口(称作notch),可以帮助后续工序确定晶圆的摆放位置。
一片晶圆最终通过全部测试的合格芯片数量与原有的完整芯片的数量之比,称为良率(yield)。由于边缘应力的原因,晶圆的边缘出现不合格芯片的概率较大,做成圆的反而可以提高硅片的利用率。而且,圆柱形的单晶硅方便运输,如果做成有棱角的,则容易磕碰。在后续的工艺中,圆形的晶圆也更加方便加工。
很显然,芯片面积(die size)更大时,同一块晶圆上只能切出更小的芯片。而且晶圆上任何位置的瑕疵都会导致包含该瑕疵的整个芯片报废。所以厂商们总希望把芯片做得更小(同时也更多地减少了边缘处的浪费)。换用更小的制程(process)可以缩小单个晶体管的尺寸,从而减小芯片面积。目前(2020年)Intel最先进的制程为14 nm或10 nm,而TSMC和三星半导体则具有7 nm的制程。制程相同时,制作工艺也可以不同,使得代工厂生产出来的芯片的晶体管密度不尽相同。
16、性能(performance)是衡量计算机运行快慢的指标。如果你是个人用户,你一般会认为对同时开始同一个任务的两台计算机,先完成任务的计算机性能更好;数据中心则更喜欢通过量化的指标——吞吐量(throughput)和带宽(bandwidth)等,来进行评估。对不同的场景,评估性能的方式与尺度也不同。
主观上来说,完成一个任务的执行时间包括CPU花费在运算本身的时间,以及磁盘读写、内存访问、IO活动等各个动作的时间。但在衡量CPU性能的时候,CPU时间一般就只包括CPU本身去执行任务的时间,而不包含其它项目。不过需要记住,最终影响用户体验的还是包括上面提到的各个杂项的总的流逝时间。
芯片的运行由时钟(clock)进行控制。单个时钟周期(clock cycle/tick/clock tick/clock period/clock/cycle)是主频的倒数。例如一个4 GHz主频的家用CPU的一个时钟周期是250 ps。
17、每指令周期数(cycles per instruction,CPI)是衡量CPU性能的一种指标。设一段代码包含的指令数量为I,平均每个指令需要耗费的周期CPI为c,易得:执行该段代码需要耗费的总周期数C = Ic。
如果又已知单个时钟周期的时间T,易得:总时间t = CT。而主频 ,所以也有 。
算法、编程语言、编译器和ISA,都会影响将代码转换成的机器指令的总数量和CPI。
当然,现在的CPU已经可以在一个周期内执行多条指令了,所以工程师们一般不会用CPI这个指标,而是取其倒数,称为每周期指令数(Instructions per cycle,IPC)。
18、芯片的功耗分为静态功耗和动态功耗两种。
静态功耗主要是漏电流(leakage current,或简写为leakage)引起的。而动态功耗主要是晶体管的翻转瞬间的功耗和容性负载的功耗。
目前,制造IC普遍采用互补金属氧化物半导体(complementary metal oxide semiconductor,CMOS)。该种半导体使得理论上静态功耗为零,因此动态功耗成为了整个IC的功耗的主要成分。
动态功耗的计算公式是:P = CV2af。C是负载电容,V是电压(VDD),f是频率,a是常数。
随着制程的发展,实际上IC的静态功耗正持续增大。
对多数芯片,输入的电能几乎都会转化为内能,必须及时散热。
19、现在的CPU一般都有多个核心(core)。核心之间是独立的,可以并行运行任务。但针对单核心编写的程序无法利用多个核心,必须修改代码,使得能够将任务拆分到多个核心上正确运行。当核心数进一步增加时,代码还要继续修改。
20、工作负载(workload),常简写为负载(load),在计算机科学中一般指运行在计算机上的若干个程序。
21、基准(benchmark),指的是特别选出的用于评估计算机性能的一组程序。SPEC(Standard Performance Evaluation Corporation)是由多个计算机行业的厂商与高校、科研院所于1988年联合组建的一个非营利组织,用于制定具有一定权威性的性能评测基准。
SPEC CPU是常用的跨平台、跨ISA的CPU性能评测基准,其最新版本为SPEC CPU 2017,并于2019年发布V1.1版本的更新。SPEC CPU 2017是计算密集型性能评测基准,主要评估:CPU性能、内存性能(包括不同层次的内存,如缓存、DRAM等)和编译器性能(C / C++ / Fortran)。SPEC CPU 2017不用于考察其它方面,如网络、图形、Java库、IO系统等。
SPEC CPU 2017提供两种衡量性能的尺度,包括SPECspeed和SPECrate。前者基于时间来评判性能(例如:完成一份同样的任务花费的时间),后者基于吞吐量来评判性能(例如:每小时完成的任务数)。SPECspeed和SPECrate各自提供了整数(integer)和浮点(floating point)性能的测试项目。SPEC CPU 2017还具有基本(base)和峰值(peak)两种性能评估的度量。测定峰值性能时,更多编译选项被允许开启,可以对代码进行深度优化来获得更高性能。需要测定哪种性能,根据需要而定。例如:一个通常只运行一般的桌面应用程序的用户也许更偏向基本性能,而运行定制的建模程序的一群科学家对峰值性能更感兴趣。
SPEC CPU 2017共有43个测试项目,分为4组,列举如下:
其中,KLOC代表代码的行数(千行)。由上表可以看出,测试领域涵盖Perl解释器、GNU C编译器、路径规划、计算机网络、离散事件模拟、XSLT进行的XML到HTML的转换、视频压缩(x264)、α-β树搜索(国际象棋)、蒙特卡洛树搜索(围棋)、递归解生成器(数独)、一般数据压缩、爆炸建模、相对论物理、分子动力学(NAMD / NAB)、生物医疗成像(有限元光学断层摄影)、光线追踪、流体动力学、天气预报、3D渲染与动画(blender渲染器)、大气层建模、大规模海洋建模(气候级)、图像操作、计算电磁学和区域海洋建模。
可见,SPEC CPU 2017其实是更加偏向专业领域的测试。总之,性能的评测没有绝对标准,也不能只看少量的指标。选择计算机时,应当根据自己的应用领域来选取合适的基准。9
常见的性能指标还有:MIPS(百万条指令 / 秒,现多见于微控制单元(Micro controller unit,MCU))、FLOPS(浮点运算次数 / 秒)。
22、如果持续不断地增加芯片的规模,性能并不会等比提升。
假设一个程序在单个CPU核心上需要运行100 s,有80%的耗时用于乘法,且该程序只有这80%能够被并行化。那么并行化不能缩短剩下20%的运行时间。于是,程序并行化后,总的运行时间为: 。其中T为并行化后的时间,n为核心数。可见,即使用无限个核心进行并行化,串行(serial)执行的剩下20%是不会加快的,必须在单个核心上运行完毕。如果我们能够得知一个程序有多少部分不能被并行化,那么就容易得出核心数与理论并行性能的关系,称为Amdahl定律:
T为并行化后所需的运行时间,t为并行化之前的运行时间,n为核心数,p为代码中可以被(完全)并行化的比例。
Amdahl定律告诉我们:如果一个程序具有不能被并行化的代码,那么扩大芯片的规模不会令这个程序的性能线性提升,且程序的运行性能理论上能够提升的幅度也是有限的。
23、如果芯片或计算机系统的使用率很低,那么功耗也不一定低。例如Google的一个大型计算机多数时候的占用率都在10%到50%,满载的时间少于1%。即使在最好的情形下,2012年该计算机在10%的负载时的耗电量仍然达到满载时的33%。能耗比较高的芯片或整台计算机,其占用率和功耗理论上应该成正比例。