基于scrapy的B站UP主信息爬取
文章目录
- 思路分析
- 项目目录
- 代码
- 结果
思路分析
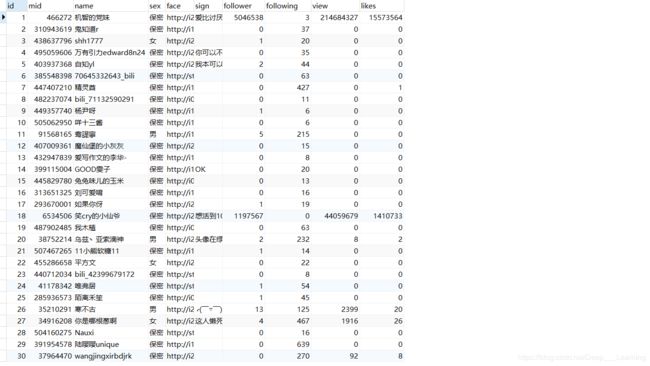
本次爬取的信息,包括UP主的mid、昵称、性别、头像的链接、个人简介、粉丝数、关注数、播放数、获赞数。
我的思路是,首先,选择一位B站比较火的UP主(这里以机智的党妹为例),然后,爬取其信息,再获取其关注列表中的用户和粉丝列表中的用户,重复上述操作。这相当于采用了递归的方式进行爬取。
下面我们来分析一下如何获取UP主的信息、关注列表和粉丝列表。

用户信息请求的URL:
https://api.bilibili.com/x/space/acc/info?mid=466272

粉丝数和关注数请求的URL:
https://api.bilibili.com/x/relation/stat?vmid=466272
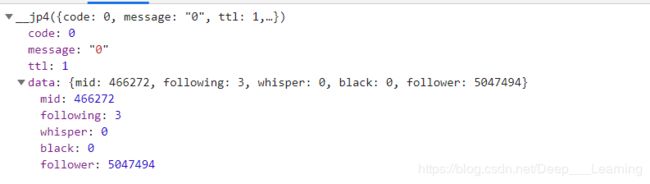
获赞数和播放数请求的URL:
https://api.bilibili.com/x/space/upstat?mid=466272

粉丝列表请求的URL:
https://api.bilibili.com/x/relation/followers?vmid=466272&pn=1&ps=20
关注列表请求的URL:
https://api.bilibili.com/x/relation/followings?vmid=466272&pn=1&ps=20

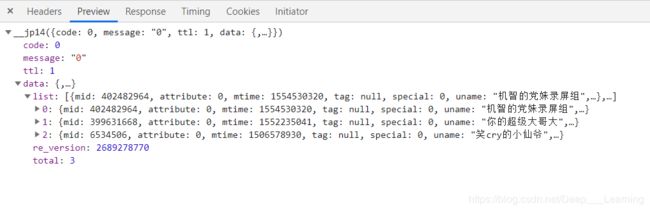
这两个的分析方法其实都差不多,这里只分析其中的一个。
上面URL中的pn代表页数,ps好像是代表一次获取的用户数目,每次固定是20个(ps这个参数,我也没细看,不过这个参数并不重要)
本来以为到这里就可以了,直接写个for循环依次遍历每一页就行了,可是。。。。。。
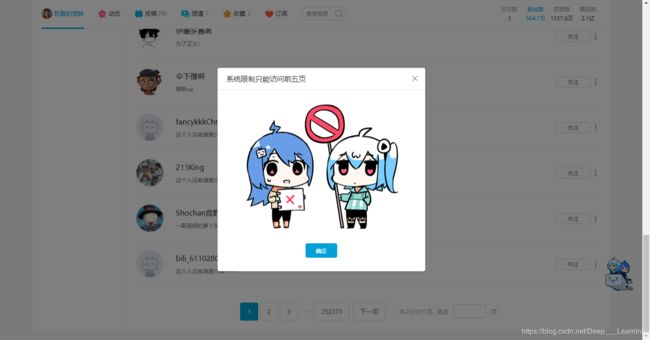
这个系统限制,只能访问前5页是什么鬼。ε=(´ο`*)))唉,难道是我没登陆的问题吗?赶紧手忙脚乱的登上我的B站账号,不过,没有任何卵用,看来是B站做了限制,就只能提取前5页的数据。对于这个问题,我一直没找到解决的方法,不知道各位爬虫大佬有没有好的解决方法呀!
但是,按照我这个思路去爬取的话,还是可以爬到很多用户的,毕竟是递归爬取嘛。如果觉得爬取的用户数不够,还可以在B站的每一个分区中,选取知名UP主(粉丝数多的)作为起始URL进行爬取,这样效果会好一些。
项目目录
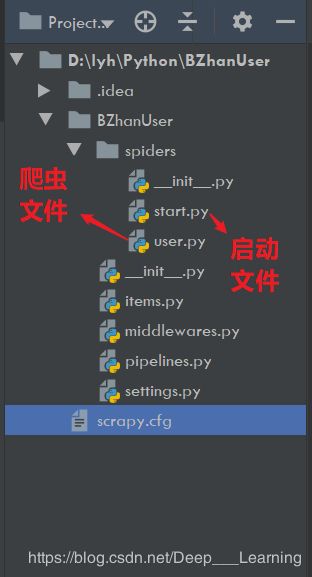
代码
start.py
# !/usr/bin/env python
# —*— coding: utf-8 —*—
# @Time: 2020/2/19 16:24
# @Author: Martin
# @File: start.py
# @Software:PyCharm
from scrapy import cmdline
cmdline.execute("scrapy crawl user".split())
# cmdline.execute("scrapy crawl user --nolog".split())
user.py
# -*- coding: utf-8 -*-
import scrapy
import json
from scrapy.http import Request
from BZhanUser.items import BzhanuserItem
class UserSpider(scrapy.Spider):
name = 'user'
allowed_domains = ['bilibili.com']
start_urls = ['https://api.bilibili.com/x/space/acc/info?mid=466272']
def parse(self, response):
data = json.loads(response.body)['data']
mid = data['mid']
name = data['name']
sex = data['sex']
face = data['face']
sign = data['sign']
# 粉丝数和关注数
url1 = 'https://api.bilibili.com/x/relation/stat?vmid=' + str(mid)
yield Request(url=url1, callback=self.parse_page1,
meta={'mid': mid, 'name': name, 'sex': sex, 'face': face, 'sign': sign})
def parse_page1(self, response):
data = json.loads(response.body)['data']
mid = data['mid']
following = data['following']
follower = data['follower']
# 获赞数和播放数
url2 = 'https://api.bilibili.com/x/space/upstat?mid=' + str(mid)
yield Request(url=url2, callback=self.parse_page2,
meta={'mid': mid, 'name': response.meta['name'], 'sex': response.meta['sex'],
'face': response.meta['face'], 'sign': response.meta['sign'], 'follower': follower,
'following': following})
def parse_page2(self, response):
data = json.loads(response.body)['data']
mid = response.meta['mid']
name = response.meta['name']
sex = response.meta['sex']
face = response.meta['face']
sign = response.meta['sign']
follower = response.meta['follower']
following = response.meta['following']
view = data['archive']['view']
likes = data['likes']
item = BzhanuserItem(
mid=mid,
name=name,
sex=sex,
face=face,
sign=sign,
follower=follower,
following=following,
view=view,
likes=likes
)
yield item
for i in range(1, 6):
following_url = 'https://api.bilibili.com/x/relation/followings?vmid=' + str(mid) + '&pn=' + str(i)
yield Request(url=following_url, callback=self.parse_following)
for i in range(1, 6):
follower_url = 'https://api.bilibili.com/x/relation/followers?vmid=' + str(mid) + '&pn=' + str(i)
yield Request(url=follower_url, callback=self.parse_follower)
def parse_following(self, response):
data = json.loads(response.body)['data']
user_list = data['list']
if user_list:
for item in user_list:
mid = item['mid']
url = 'https://api.bilibili.com/x/space/acc/info?mid=' + str(mid)
yield Request(url=url, callback=self.parse)
def parse_follower(self, response):
data = json.loads(response.body)['data']
user_list = data['list']
if user_list:
for item in user_list:
mid = item['mid']
url = 'https://api.bilibili.com/x/space/acc/info?mid=' + str(mid)
yield Request(url=url, callback=self.parse)
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BzhanuserItem(scrapy.Item):
mid = scrapy.Field()
name = scrapy.Field()
sex = scrapy.Field()
face = scrapy.Field()
sign = scrapy.Field()
follower = scrapy.Field()
following = scrapy.Field()
view = scrapy.Field()
likes = scrapy.Field()
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from twisted.enterprise import adbapi
from pymysql import cursors
class BzhanuserPipeline(object):
def __init__(self):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': 'root',
'database': 'bzhan',
'charset': 'utf8mb4'
}
self.conn = pymysql.connect(**dbparams)
self.cursor = self.conn.cursor()
self._sql = None
def process_item(self, item, spider):
sql = self.sql()
data = dict(item)
self.cursor.execute(
sql,
(data['mid'],
data['name'],
data['sex'],
data['face'],
data['sign'],
data['follower'],
data['following'],
data['view'],
data['likes']))
self.conn.commit()
print(data)
return item
def sql(self):
if not self._sql:
self._sql = "insert into user(id,mid,name,sex,face,sign,follower,following,view,likes) values(null,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
return self._sql
return self._sql
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for BZhanUser project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'BZhanUser'
SPIDER_MODULES = ['BZhanUser.spiders']
NEWSPIDER_MODULE = 'BZhanUser.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'BZhanUser (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'BZhanUser.middlewares.BzhanuserSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'BZhanUser.middlewares.BzhanuserDownloaderMiddleware': 543,
# }
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BZhanUser.pipelines.BzhanuserPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
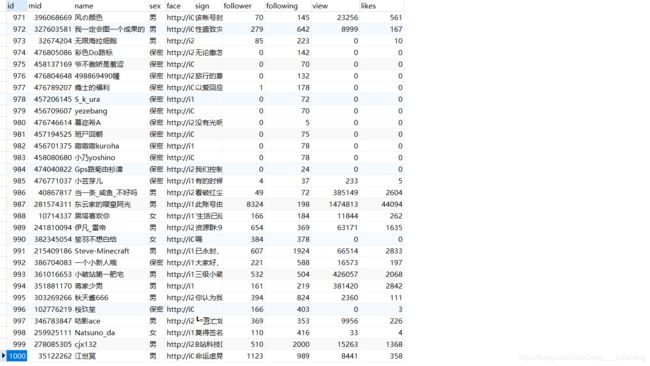
结果
代码没运行完,我就停止了,看了看数据库,大约爬了1000条信息。