python3爬虫系列22之selenium模拟登录带验证码的微博且抓取数据
python3爬虫系列22之selenium模拟登录需要验证码的微博且抓取数据
1.前言
前面一篇说的是 python3爬虫系列21之selenium自动化登录163邮箱并读取未读邮件内容
,实际上呢,163的登录没有遇到验证码的问题。
现在写一个微博的自动登录的,注意这个是需要验证码的。很多网上的代码不适应了,微博代码已经改了,是最新的
2.网页分析
目标地址:https://weibo.com/

那么实际上现在的难点在于这个验证码怎么办?
3. 手动输入验证码版
这一块为讲selenium设置为开发者模式,防止被网站识别出来我们使用了Selenium爬虫。
# 进入开发者模式
options = webdriver.ChromeOptions()
# 此步骤很重要,设置为开发者模式,防止被网站识别出来使用了Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(options=options)
driver.set_page_load_timeout(4) # 设置模拟浏览器最长等待时间
是
# driver.maximize_window() # 最大化窗口
normal_window = driver.get(url)
time.sleep(5) # 加延迟,为了加载元素,避免太快出现异常
整体代码如下:
#!/usr/bin/python3
from fake_useragent import UserAgent
from selenium import webdriver
import time
import requests
from selenium.webdriver.chrome import options
ua = UserAgent()
print(ua.random) # 随机产生
headers = {
'User-Agent': ua.random # 伪装
}
def auto_pc(url,username,password):
# 进入开发者模式
options = webdriver.ChromeOptions()
# 此步骤很重要,设置为开发者模式,防止被网站识别出来使用了Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(options=options)
driver.set_page_load_timeout(4) # 设置模拟浏览器最长等待时间
# driver.maximize_window() # 最大化窗口
normal_window = driver.get(url)
time.sleep(5) # 加延迟,为了加载元素,避免太快出现异常
driver.find_element_by_id('loginname').send_keys(username) #微博号
driver.find_element_by_name('password').send_keys(password) # 微博密码
driver.find_element_by_class_name('W_input').click() # 如果需要输入验证码
time.sleep(2)
pic_path = 'verify_image.jpg'
if '"text=请输入验证码"' in driver.page_source:
img_ele=driver.find_element_by_xpath('//img[@node-type="verifycode_image"]')
image_url = img_ele.get_attribute('src')
# 截取当前url页面的图片,并将截取的图片保存在指定的路径下面(pic_path)
driver.save_screenshot(pic_path)
# 下载验证码-(这里并没有什么卵用,再次get的时候,验证码会变,我写这个是为了收集数据集。-可删掉。)
response = requests.get(image_url,headers=headers)
print('yzm', response.content)
with open('verify_image.jpg', 'wb') as f:
f.write(response.content)
vares_img = input('请输入:\n')
driver.find_element_by_name('verifycode').send_keys(vares_img) # 填入验证码框
driver.find_element_by_css_selector(".info_list.login_btn a[node-type='submitBtn']").click() # 登录按钮
checklogin(driver,normal_window)
def checklogin(driver,normal_window):
# 登录成功后获取cookie
cookie = {}
cookies = []
if "微博-随时随地发现新鲜事" in driver.title:
for elem in driver.get_cookies():
cookie[elem["name"]] = elem["value"]
if len(cookie) > 0:
cookies.append(cookie)
continue
print('成功登录微博', len(cookies))
time.sleep(10)
jumphtml(driver,normal_window)
else:
print("登录 Cookie Failed: !" )
def jumphtml(driver,normal_window):
# 2个方式——跳转到指定的页面去
# driver.get('https://m.weibo.cn/index/friends?format=cards')
# gov = browser.find_element_by_css_selector('#pl_unlogin_home_hotpersoncategory > div > div > div:nth-child(4) > ul > li:nth-child(1) > a > span')
# gov.click()
#####获取所有页面句柄
all_Handles = driver.window_handles
#####如果新的pay_window句柄不是当前句柄,用switch_to_window方法切换
for pay_window in all_Handles:
if pay_window != normal_window:
driver.switch_to.window(pay_window)
print('========================跳转页面============================')
# 获取跳转后页面的源码
time.sleep(10)
source = driver.page_source.encode("gbk", "ignore").decode("gbk")
#print(source)
# 接下来可以根据id,class或css标签,xpath之类的,找到自己需要的内容。
# //*[@id="v6_pl_content_homefeed"]/div/div[4]/div[1]/div[2]/div[4]/div[1]/a
username=driver.find_element_by_xpath('//*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/div/a[1]')
print('用户名:',username.text)
# //*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[1]/a/strong
guanzhu = driver.find_element_by_xpath('//*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[1]/a/strong')
print('关注数:', guanzhu.text)
# //*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[2]/a/strong
fensi = driver.find_element_by_xpath('//*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[2]/a/strong')
print('粉丝数:', fensi.text)
# //*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[3]/a/strong
shumu = driver.find_element_by_xpath('//*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[3]/a/strong')
print('微博数:', shumu.text)
# driver.close()
# driver.quit()
# 查看源代码且存到本地
#print(driver.page_source)
# fileSuc = open("main.html", 'w')
# fileSuc.write(driver.page_source)
if __name__ == '__main__':
url='https://weibo.com/'
username='18285303893'
password='zt123456789'
auto_pc(url, username, password)
运行以后,等出现提示,然后需要在pycharm里面手动输入一下验证码:

登陆成功,就会提取最后的结果:

其中,我们还把验证码截图下来。
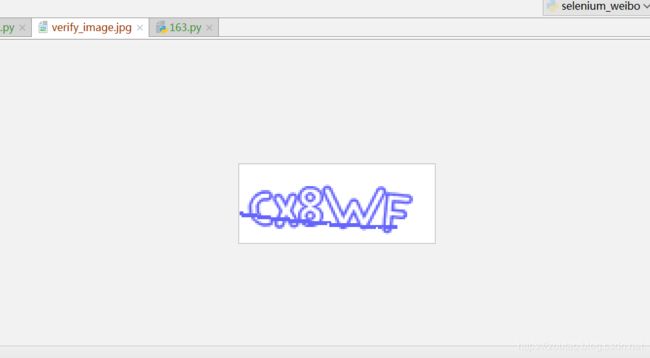
有什么用处?
想想今天这个太LOW了吧,明明说自动化爬虫,最后验证码还是需要手动输入一下?所以我们下一篇整个验证码识别的。
4.报错解决
selenium.common.exceptions.TimeoutException: Message: timeout

driver.set_page_load_timeout(4) # 设置模拟浏览器最长等待时间-如果4秒内没有加载完成就会报错
5. Senlenium为什么要进入开发者模式?
在写爬虫,面对很多js 加载的页面,很多人束手无策,更多的人喜欢用Senlenium+ Webdriver,古语有云:道高一尺魔高一丈。已淘宝为首,众多网站都针对 Selenium的js监测机制, 比如:window.navigator.webdriver,navigator.languages,navigator.plugins.length……
正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为
undefined。
当我们用selenium 的时候, window.navigator.webdriver的值为 true。
解决:
需要设置Chromedriver的启动参数即可解决问题。
在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为[‘enable-automation’]
此时启动的Chrome窗口,在右上角会弹出一个提示,不用管它,不要点击停用按钮。

参考地址:
模拟登陆weibo:
https://www.cnblogs.com/tanqingboke/p/11171786.html