常见分布与假设检验
常见分布与假设检验
- 一、常见分布
- 1、离散型分布
- 1.1 二项分布
- 1.2 泊松分布(描述某段时间内,事件具体发生的概率)
- 2、连续型分布
- 2.1 均匀分布
- 2.2 正态分布
- 2.3 指数分布(描述事件的时间间隔的概率)
- 二、假设检验
- 1、正态检验
- 2、卡方检验
- 3、t检验
- 4、ANOVA检验
- 5、Mann-Whitney U检验
一、常见分布
1、离散型分布
1.1 二项分布
二项分布可以认为是一种只有两种结果(成功/失败)的单次试验重复多次后成功次数的分布概率。
二项分布需要满足以下条件:
试验次数是固定的
每次试验都是独立的
对于每次试验成功的概率都是一样的
一些二项分布的例子:
销售电话成功的次数
一批产品中有缺陷的产品数量
掷硬币正面朝上的次数
在一袋糖果中取糖果吃,拿到红色包装的次数
在n次试验中,单次试验成功率为p,失败率q=1-p,则出现成功次数的概率为 P ( X = x ) = C n x p x q n − x P(X=x) = C_n^x p^x q^{n-x} P(X=x)=Cnxpxqn−x
Python实现:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
# 生成大小为1000的符合b(10,0.5)二项分布的样本集
s = np.random.binomial(n=10,p=0.5,size=1000)
# 计算二项分布B(10,0.5)的PMF
x=range(11)
p=stats.binom.pmf(x, n=10, p=0.5)
# 计算二项分布B(10,0.5)的CDF
x=range(11)
p=stats.binom.cdf(x, n=10, p=0.5)
#比较n=10,p=0.5的二项分布的真实概率质量和10000次随机抽样的结果
x = range(11) # 二项分布成功的次数(X轴)
t = stats.binom.rvs(10,0.5,size=10000) # B(10,0.5)随机抽样10000次
p = stats.binom.pmf(x, 10, 0.5) # B(10,0.5)真实概率质量
fig, ax = plt.subplots(1, 1)
sns.distplot(t,bins=10,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples')
sns.scatterplot(x,p,color='purple')
sns.lineplot(x,p,color='purple',label='True mass density')
plt.title('Binomial distribution')
plt.legend(bbox_to_anchor=(1.05, 1))

1.2 泊松分布(描述某段时间内,事件具体发生的概率)
泊松分布是用来描述泊松试验的一种分布,满足以下两个特征的试验可以认为是泊松试验:
所考察的事件在任意两个长度相等的区间里发生一次的机会均等
所考察的事件在任何一个区间里发生与否和在其他区间里发生与否没有相互影响,即是独立的
泊松分布需要满足一些条件:
试验次数n趋向于无穷大
单次事件发生的概率p趋向于0
np是一个有限的数值
泊松分布的一些例子:
某医院平均每小时出生三个婴儿(λ=3)
某网站平均每分钟有两次访问(λ=2)
更多例子请参考 泊松分布 & 指数分布 及其数字特征.
一个服从泊松分布的随机变量X,在具有比率参数(rate parameter)λ (λ=np)的一段固定时间间隔内,事件发生次数为i的概率为 P { X = i } = e − λ λ i i ! P\lbrace X= i \rbrace = e^{-λ} \frac{λ^i}{i!} P{X=i}=e−λi!λi
Python实现:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
#生成大小为1000的符合P(1)的泊松分布的样本集
s = np.random.poisson(lam=1,size=1000)
#计算泊松分布P(1)的PMF
x=range(11)
p=stats.poisson.pmf(x, mu=1)
#计算泊松分布P(1)的CDF
x=range(11)
p=stats.poisson.cdf(x, mu=1)
#比较λ=2的泊松分布的真实概率质量和10000次随机抽样的结果
x=range(11)
t= stats.poisson.rvs(2,size=10000)
p=stats.poisson.pmf(x, 2)
fig, ax = plt.subplots(1, 1)
sns.distplot(t,bins=10,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples')
sns.scatterplot(x,p,color='purple')
sns.lineplot(x,p,color='purple',label='True mass density')
plt.title('Poisson distribution')
plt.legend()

2、连续型分布
需要注意的是,连续型随机变量的概率密度在某个点的概率密度并不是在这一点发生的概率。即PDF曲线的点并不是该分布在这一点的概率。事实上,连续型分布在各个点的概率均为0,只有区间概率才有意义。
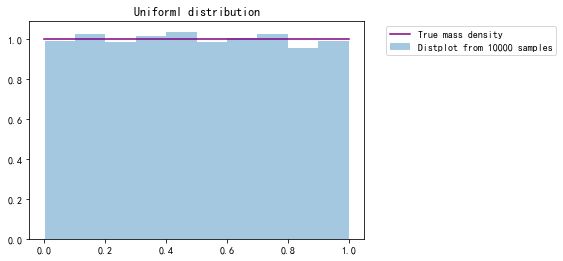
2.1 均匀分布
均匀分布指的是一类在定义域内概率密度函数处处相等的统计分布。
若X是服从区间[a,b]上的均匀分布,则记作X~U[a,b]。
均匀分布X的概率密度函数为 f ( x ) = { 1 b − a , a ≤ x ≤ b 0 , o t h e r s f(x)= \begin{cases} \frac {1} {b-a} , & a \leq x \leq b \\ 0, & others \end{cases} f(x)={b−a1,0,a≤x≤bothers 分布函数为 F ( x ) = { 0 , x < a ( x − a ) ( b − a ) , a ≤ x ≤ b 1 , x > b F(x)=\begin{cases} 0 , & x< a \\ \frac{(x-a)}{(b-a)}, & a \leq x \leq b \\ 1, & x>b \end{cases} F(x)=⎩⎪⎨⎪⎧0,(b−a)(x−a),1,x<aa≤x≤bx>b 均匀分布的一些例子:
一个理想的随机数生成器
一个理想的圆盘以一定力度旋转后静止时的角度
Python实现:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
# 生成大小为1000的符合U(0,1)均匀分布的样本集,注意在此方法中边界值为左闭右开区间
s = np.random.uniform(low=0,high=1,size=1000)
# 计算均匀分布U(0,1)的PDF
x = numpy.linspace(0,1,100)
p= stats.uniform.pdf(x,loc=0, scale=1)
# 计算均匀分布U(0,1)的CDF
x = numpy.linspace(0,1,100)
p= stats.uniform.cdf(x,loc=0, scale=1)
#比较U(0,1)的均匀分布的真实概率密度和10000次随机抽样的结果
x=numpy.linspace(0,1,100)
t= stats.uniform.rvs(0,1,size=10000)
p=stats.uniform.pdf(x, 0, 1)
fig, ax = plt.subplots(1, 1)
sns.distplot(t,bins=10,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples')
sns.lineplot(x,p,color='purple',label='True mass density')
plt.title('Uniforml distribution')
plt.legend(bbox_to_anchor=(1.05, 1))
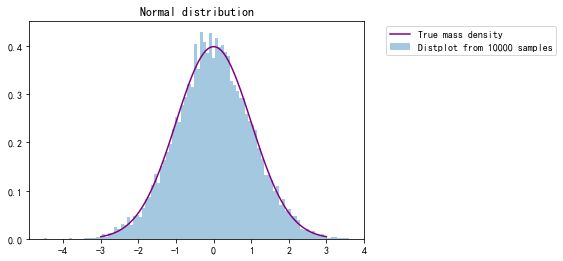
2.2 正态分布
正态分布,也叫做高斯分布,是最为常见的统计分布之一,是一种对称的分布,概率密度呈现钟摆的形状,其概率密度函数为 f ( x ) = 1 2 π σ e − ( x − u ) 2 2 σ 2 f(x)=\frac{1}{\sqrt{2π}\sigma}e^{\frac{-(x-u)^2}{2\sigma^2}} f(x)=2πσ1e2σ2−(x−u)2 记为X ~ N(μ, σ 2 σ^2 σ2) , 其中μ为正态分布的均值,σ为正态分布的标准差
有了一般正态分布后,可以通过公式变换将其转变为标准正态分布 Z ~ N(0,1), Z = X − μ σ Z=\frac {X-μ} {σ} Z=σX−μ 正态分布的一些例子:
成人的身高
不同方向的气体分子的运动速度
测量物体质量时的误差
正态分布在现实生活有着非常多的例子,这一点可以从中心极限定理来解释,中心极限定理说的是一组独立同分布的随机样本的平均值近似为正态分布,无论随机变量的总体符合何种分布。即,只要样本数量足够大(大于等于50),无论总体是何种分布,样本均为正态分布。
Python实现:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
# 生成大小为1000的符合N(0,1)正态分布的样本集,可以用normal函数自定义均值,标准差,也可以直接使用standard_normal函数
s = numpy.random.normal(loc=0,scale=1,size=1000)
s = numpy.random.standard_normal(size=1000)
# 计算正态分布N(0,1)的PDF
x = numpy.linspace(-3,3,1000)
p= stats.norm.pdf(x,loc=0, scale=1)
# 计算正态分布N(0,1)的CDF
x = numpy.linspace(-3,3,1000)
p= stats.norm.cdf(x,loc=0, scale=1)
#比较N(0,1)的正态分布的真实概率密度和10000次随机抽样的结果
x=numpy.linspace(-3,3,100)
t= stats.norm.rvs(0,1,size=10000)
p=stats.norm.pdf(x, 0, 1)
fig, ax = plt.subplots(1, 1)
sns.distplot(t,bins=100,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples')
sns.lineplot(x,p,color='purple',label='True mass density')
plt.title('Normal distribution')
plt.legend(bbox_to_anchor=(1.05, 1))
2.3 指数分布(描述事件的时间间隔的概率)
指数分布通常被广泛用在描述一个特定事件发生所需要的时间,在指数分布随机变量的分布中,有着很少的大数值和非常多的小数值。
指数分布的概率密度函数为 f ( x ) = { λ e − λ x , x ≥ 0 0 , x < 0 f(x)= \begin{cases} λe^{-λx} , & x \geq 0 \\ 0, & x < 0 \end{cases} f(x)={λe−λx,0,x≥0x<0 记为 X~E(λ), 其中λ被称为率参数(rate parameter),表示每单位时间发生该事件的次数。
分布函数为 F ( a ) = P { X ≤ a } = 1 − e − λ a , a ≥ 0 F(a) = P{\{X \leq a\}} = 1-e^{-λa}, a\geq 0 F(a)=P{X≤a}=1−e−λa,a≥0 指数分布的一些例子:
婴儿出生的时间间隔
网站访问的时间间隔
在产线上收到一个问题产品的时间间隔
指数分布与泊松分布相互联系。指数分布公式中的 λ λ λ实际为泊松分布的期望(泊松分布公式中的 λ λ λ)的倒数。此处我们将泊松分布的期望( λ λ λ)暂时成为 μ μ μ,则有 μ = 1 λ , σ 2 = 1 λ 2 μ=\frac1λ, \sigma^2=\frac{1}{λ^2} μ=λ1,σ2=λ21
详细例子请见:python-指数分布介绍.
关于指数分布还有一个有趣的性质的是指数分布是无记忆性的,假定在等候事件发生的过程中已经过了一些时间,此时距离下一次事件发生的时间间隔的分布情况和最开始是完全一样的,就好像中间等候的那一段时间完全没有发生一样,也不会对结果有任何影响,用数学语言来表述是 P { X > s + t ∣ X > t } = P { X > s } P\{X>s+t | X> t\} =P\{X>s\} P{X>s+t∣X>t}=P{X>s}
Python实现:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
# 生成大小为1000的符合E(1/2)指数分布的样本集,注意该方法中的参数为指数分布参数λ的倒数
s = numpy.random.exponential(scale=2,size=1000)
# 计算指数分布E(1)的PDF
x = numpy.linspace(0,10,1000)
p= stats.expon.pdf(x,loc=0,scale=1)
# 计算指数分布E(1)的CDF
x = numpy.linspace(0,10,1000)
p= stats.expon.cdf(x,loc=0,scale=1)
#比较E(1)的指数分布的真实概率密度和10000次随机抽样的结果
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
x=numpy.linspace(0,10,100)
t= stats.expon.rvs(0,1,size=10000)
p=stats.expon.pdf(x, 0, 1)
fig, ax = plt.subplots(1, 1)
sns.distplot(t,bins=100,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples')
sns.lineplot(x,p,color='purple',label='True mass density')
plt.title('Exponential distribution')
plt.legend(bbox_to_anchor=(1, 1))

二、假设检验
1、正态检验
Shapiro-Wilk Test是一种经典的正态检验方法。
H0: 样本总体服从正态分布
H1: 样本总体不服从正态分布
import numpy as np
from scipy.stats import shapiro
data_nonnormal = np.random.exponential(size=100)
data_normal = np.random.normal(size=100)
def normal_judge(data):
stat, p = shapiro(data)
if p > 0.05:
return 'stat={:.3f}, p = {:.3f}, probably gaussian'.format(stat,p)
else:
return 'stat={:.3f}, p = {:.3f}, probably not gaussian'.format(stat,p)
# output
normal_judge(data_nonnormal)
# 'stat=0.850, p = 0.000, probably not gaussian'
normal_judge(data_normal)
# 'stat=0.987, p = 0.415, probably gaussian'
2、卡方检验
目的:检验两组类别变量是相关的还是独立的
H0: 两个样本是独立的
H1: 两组样本不是独立的
from scipy.stats import chi2_contingency
table = [[10, 20, 30],[6, 9, 17]]
stat, p, dof, expected = chi2_contingency(table)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably independent')
else:
print('Probably dependent')
# output
#stat=0.272, p=0.873
#Probably independent
3、t检验
目的:检验两个独立样本集的均值是否具有显著差异
H0: 均值是相等的
H1: 均值是不等的
from scipy.stats import ttest_ind
import numpy as np
data1 = np.random.normal(size=10)
data2 = np.random.normal(size=10)
stat, p = ttest_ind(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
# output
# stat=-1.382, p=0.184
# Probably the same distribution
4、ANOVA检验
目的:与t-test类似,ANOVA可以检验两组及以上独立样本集的均值是否具有显著差异
H0: 均值是相等的
H1: 均值是不等的
from scipy.stats import f_oneway
import numpy as np
data1 = np.random.normal(size=10)
data2 = np.random.normal(size=10)
data3 = np.random.normal(size=10)
stat, p = f_oneway(data1, data2, data3)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
# output
# stat=0.189, p=0.829
# Probably the same distribution
5、Mann-Whitney U检验
目的:检验两个样本集的分布是否相同
H0: 两个样本集的分布相同
H1: 两个样本集的分布不同
from scipy.stats import mannwhitneyu
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169]
stat, p = mannwhitneyu(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably the same distribution')
else:
print('Probably different distributions')
# output
# stat=40.000, p=0.236
# Probably the same distribution