航空公司客户价值分析
1.背景方面
准确的客户分类的结果是企业优化营销资源的重要依据,本文利用了航空公司的部分数据,利用Kmeans聚类方法,对航空公司的客户进行了分类,来识别出不同的客户群体,从来发现有用的客户,从而对不同价值的客户类别提供个性化服务,指定相应的营销策略。
本次数据挖掘与数据分析目标:
(1)借助航空公司数据,对客户进行分类;
(2)对不同类别的客户进行特征分析,比较不同类别客户的价值分析;
(3)对不同价值的客户类别进行个性化服务,制定相应的营销策略。
2.分析过程
识别客户价值应用最广泛的模型是通过3个指标(最近消费时间间隔(Recency)、消费频率(Frequency)和消费金额(Money))来进行客户细分,识别出高价值客户,简称RFM模型。
RFM模型中,消费金额表示一段时间内,客户购买企业产品金额的总和。由于航空票价受到运输距离、舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的。例如,一位购买长航线、低等舱位票的旅客与一位购买短航线、高等级舱位票的旅客相比,后者对于航空公司的价值可能更高。因此,这个指标并不适合航空公司客户价值分析。我们选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值C两个指标代替消费金额。此外,还考虑航空公司会员入会时间的长短在一定程度上影响客户价值,所以在模型中增加客户关系长度L,作为区分客户的另一指标。
综上所述,航空公司识别客户价值模型(LRFMC)指标如下:
客户关系长度L:会员入会时间距观测窗口结束的月份
消费时间间隔R:客户最近一次乘坐公司飞机距观测窗口结束的月数
消费频率F:客户在观测窗口内乘坐公司飞机的次数
飞行里程M:客户在观测窗口内飞行里程
折扣系数的平均值C:客户在观测窗口内乘坐舱位所对应的折扣系数的平均值
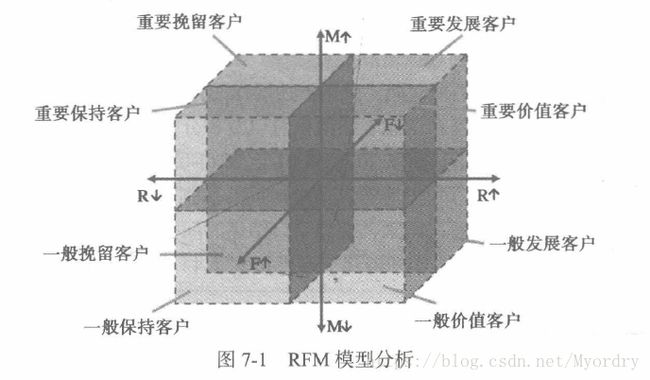
传统的RFM模型采用属性分箱的方法,如下图所示(依据属性的平均值进行划分),虽然也能识别出最有价值客户,但是如果LRFMC模型使用同样的方法,则细分的属性太多,提高了后续根据客户类别的营销成本。故本次分析使用聚类方法,通过对航空公司客户价值的五个指标进行Kmeans聚类分析,识别出最有价值客户。
本项目航空公司客户价值分析的总体流程如下图所示:
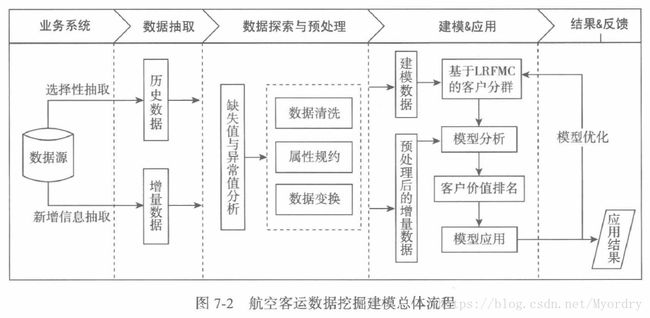
航空公司客户价值信息挖掘主要包話以下步骤:
(1)从航空公司的数据源中进行选择性抽取与新增数据抽取分别形成历史数据和增量数据;
(2)对步骤1)中形成的两个数据集进行数据探索分析和预处理,包括数据缺失值和异常值分析,数据属性的规约、清洗和变换;
(3)利用步骤2)中的处理的数据进行建模,基于旅客价值的LRFMC模型进行客户分类,对各个客户群进行特征分析,识别出最有价值的客户;
(4)针对模型结果得到不同价值的客户,采用不同的营销手段,提供定制化的服务。
3.数据探索分析
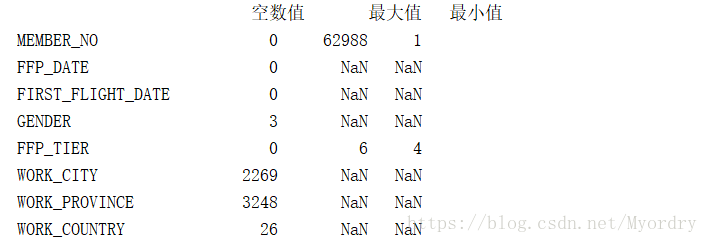
针对本项目的数据,主要进行缺失值分析和异常值分析。比如票价为空值,票价最小值为0、折扣率最小值为、总飞行里程数大于零的记录。
拿到原始数据后,可以使用Python代码实现对数据的初步分析,主要使用pandas库中的describe()函数,代码如下:
# -*- coding:utf-8 -*-
"""
对数据进行基本的探索,返回缺失值个数以及最大值最小值等
"""
import pandas as pd
datafile = "F:\DeskTop\Python-Data\chapter7\demo\data\\air_data.csv" #原始数据
resultfile = "F:\DeskTop\Python-Data\chapter7\demo\data\explore.xls" #数据探索结果总结表
data = pd.read_csv(datafile,encoding = "utf-8") #读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)
"""
包括对数据的基本描述,percentiles参数是指定计算多少的分位数表
(如1/4分位数、中位数等);T是转置,转置后更方便查
"""
explore = data.describe(percentiles=[],include="all").T
#describe()函数自动计算非空值数,需要手动计算空值数
explore["null"] = len(data) - explore["count"]
explore = explore[["null","max","min"]]
explore.columns = [u"空数值",u"最大值",u"最小值"] #对结果统计的表头重命名
"""
'''这里只选取部分探索结果。
describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、
top(频数最高者)、freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)'''
"""
# print(explore)
explore.to_excel(resultfile) ##导出结果
统计结果中的部分如下所示:
4.数据预处理
针对上述问题的数据预处理包括数据清洗、属性规约和数据变换。
4.1 数据清洗
由上述分析可知,原始数据中存在着票价为空值,票价最小值为0、折扣率最小值为0而总飞行里程数大于零的等异常记录。考虑原始数据样本量较大,而这类数据的数量又很小,因此可以选择舍弃处理。
(1)舍弃票价为空的记录;
(2)舍弃票价为零、平均折扣率不为零,总飞行公里大于零的数据。
同样适用Python的Pandas库进行数据清洗,代码如下所示:
#-*- coding: utf-8 -*-
#数据清洗,过滤掉不符合规则的数据
import pandas as pd
datafile = "F:\DeskTop\Python-Data\chapter7\demo\data\\air_data.csv"
cleanfile = "F:\DeskTop\Python-Data\chapter7\demo\data\data_cleaned.csv"
data = pd.read_csv(datafile,encoding="utf-8")
##只保留票价非空值的,每个data["SUM_YR_1"].notnull()返回布尔值的列表,同为True才保留
data = data[data["SUM_YR_1"].notnull() & data["SUM_YR_2"].notnull()]
##只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录
index1 = data["SUM_YR_1"] != 0
index2 = data["SUM_YR_2"] != 0
index3 = (data["SEG_KM_SUM"] == 0) & (data["avg_discount"] == 0)
data = data[index1 | index2 |index3]
data.to_excel(cleanfile)4.2 属性规约
原始数据中有众多属性,需要选取与本次模型相关的属性,最终选取的6个相关属性分别为:入会时间(FFP_DATE)、观测窗口的结束时间(LOAD_TIME)、飞行次数(FLIGHT_COUNT)、平均折扣率(AVG_DISCOUNT)、观测窗口总飞行里程数(SEG_KM_SUM)、最后一次乘机时间至观察窗口末端时长(LAST_TO_END)。删除与模型不相关、弱相关或冗余的属性,比如,会员卡号、性别、工作地城市、工作地所在省份等。
4.3数据变换
数据变换,即将数据变换为“适当的”格式,以适应挖掘任务以及算法的需求。本项目主要的数据变换方式为属性构造和数据标准化。
(1)属性构造
由于数据中并没有直接给出LRFMC5个指标,需要通过属性构造来提取这5个指标。具体的计算方式如下:
(1)L=LOAD_TIME-FFP_DATE
(2)R=LAST_TO_END
(3)F=FLIGHT_COUNT
(4)M=SEG_KM_SUM
(5)C= AVG_DISCOUNT
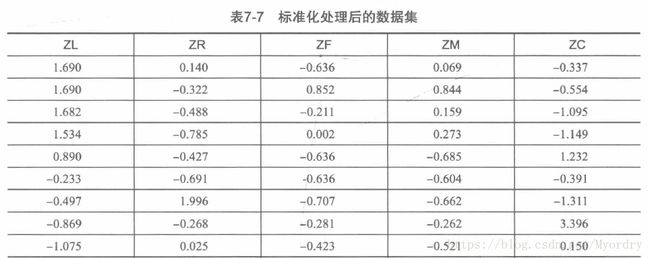
(2)数据标准化
得到LRFMC5个指标后,对这五个指标进行分析,发现五个指标取值范围数据差异较大,为了消除数量级数据带来的影响,需要对数据进行标准化处理,本次使用标准差标准化处理,代码如下所示:
# -*- coding:utf-8 -*-
#标准差标准化
import pandas as pd
datafile = "F:\DeskTop\Python-Data\chapter7\demo\data\\zscoredata.xls"
zscorefile = "F:\DeskTop\Python-Data\chapter7\demo\data\zscoreddata.xls"
#标准化处理
data = pd.read_excel(datafile)
data = (data - data.mean(axis=0))/(data.std(axis=0))
data.columns = ["Z"+i for i in data.columns] ##表头重新命名,前面加上Z
data.to_excel(zscorefile,index=False)
5.构建专家样本
最终得到的专家样本库如下所示,专家样本共62044个。
6.模型构建
采用KMeans聚类算法对客户数据进行客户分群,结合业务相关知识确定聚成5类客户。
Kmeans聚类算法位于Sklearn库下的聚类子库(sklearn.cluster),代码如下所示:
# -*- coding:utf-8 -*-
#KMeans聚类方法
import pandas as pd
from sklearn.cluster import KMeans ##导入KMeans聚类方法
inputfile = "F:\DeskTop\Python-Data\chapter7\demo\data\zscoreddata.xls"
k = 5 #聚类为5类
data = pd.read_excel(inputfile)
#调用KMeans方法,进行分析
kmodel = KMeans(n_clusters=k,n_jobs=1) #n_job为并行数,设定为CPU数目较好
kmodel.fit(data) #训练模型
#查看聚类中心以及聚类数目
r1=pd.Series(kmodel.labels_).value_counts()
r2=pd.DataFrame(kmodel.cluster_centers_)
r=pd.concat([r2,r1],axis=1)
r.columns=list(data.columns)+['类别数目']
print(r)
7.结果分析

对聚类结果进行特征分析,绘制客户群特征分析图(雷达图),如下图所示:
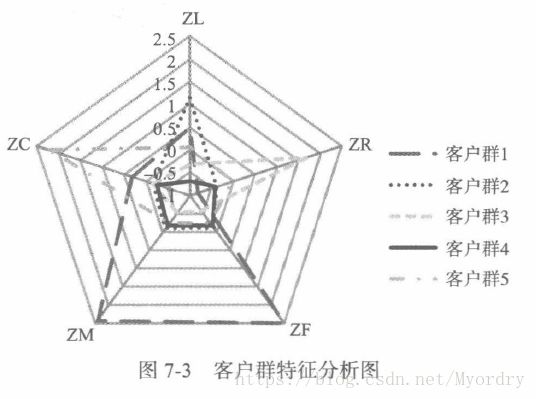
最终将客户可以分为四种,如下表所示:
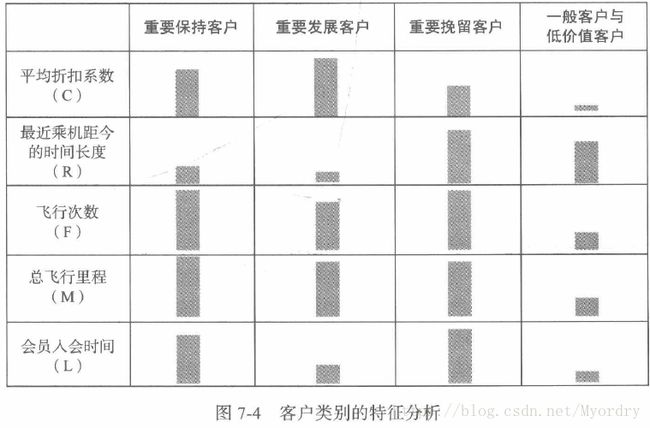
重要保持客户:平均折扣率高,乘坐次数或里程高,最近坐过本公司航班。
重要发展客户:平均折扣率较高,乘坐次数和里程较低。
重要挽留客户:平均折扣率,乘坐次数或者里程较高,较长时间没坐本公司航班。
一般与低价值客户:扣率低,较长时间未做本公司航班,乘坐次数或里程较低,入会时长短。
对于使用历史数据建立的模型而言,要经常对新加入的客户进行聚类中心判断,同时对本次新增客户的特征进行特征分析。如果新增的客户的特征与模型判断有较大误差,需要重点关注和解决。可以每隔半年重新训练一次模型。
8.项目总结
通过“航空公司客户价值分析”项目:
(1)进一步熟悉了数据挖掘以及数据探索分析的一般流程;
(2)加深了对数据预处理中属性规约,数据变化的理解,包括标准差标准化,属性构造等;
(3)加深了对Kmeans聚类方法的理解,进一步熟悉了Sklearn中相关函数的运用;
(4)掌握了使用雷达图对结果进行特征分析的方法。