知识框架(2-2)一遍搞定云计算——Hadoop/HDFS #面试常见 #教科书式整理
- Hadoop Ecosystem囊括的方向:
- 要了解更多关于这些工具,请访问大数据对基本的Hadoop工具的Edureka博客:http://www.edureka.co/blog/essential-hadoop-tools-for-big-data
- 存储,海量的数据怎样有效的存储?主要包括hdfs、Kafka;
- 计算,海量的数据怎样快速计算?主要包括MapReduce、Spark、Flink等;
- 查询,海量数据怎样快速查询?主要为Nosql和Olap(Online analytical processing),Nosql主要包括Hbase、 Cassandra 等,其中olap包括kylin、impla等,其中Nosql主要解决随机查询,Olap技术主要解决关联查询;
- 挖掘,海量数据怎样挖掘出隐藏的知识?也就是当前火热的机器学习和深度学习等技术,包括TensorFlow、caffe、mahout等;
文章目录
- 一、Hadoop = HDFS + Yarn + MR
- 1. Hadoop 概念了解
- 2. SSH登录 & Hadoop安装方式
- 3. Hadoop可以运行在哪三种模式
- 4. 请列出正常工作的hadoop集群【cluster】中hadoop都需要启动哪些进程,他们的作用分别是什么?
- 5. 列出的Hadoop 1和2之间的差异。什么是主动和被动的 “Namenodes”?
- 6. 为什么说hadoop适合处理少量的大文件?(不适合大量的(小)文件)
- 7. 为什么hadoop不适合在非Unix平台上运行?
- 8. 什么是传统的关系型数据库和Hadoop之间的基本区别?
- 9. 在hadoop集群中添加新的节点和删除节点的步骤?
- 10、Hadoop性能调优?
- 二、HDFS【data storage】【written in Java】
- 1. 基本特点
- 2. 什么是“HDFS块”和“输入分片/分割”之间的区别?
- 3. 为什么最佳分片大小应该和块(block)大小(64/128MB)相同?
- 4. 为什么HDFS不适合存储小文件?
- 5. 为什么HDFS中的块如此之大的好处和坏处(64 /128 MB)?
- 6. HDFS文件压缩的好处?
- 7. 当两个客户端尝试访问对HDFS相同的文件,会发生什么?
- 8. 如何写入HDFS?【Write to HDFS】
- 9. Replication Management
- 10. NameNode的地位/重要性?HDFS如何管理数据复制?
- 11. 是否可以在不同集群之间复制文件?如果是的话,怎么能做到这一点?
- 12. 当NameNode关闭时会发生什么?
- 13. 添加新datanode后,作为Hadoop管理员需要做什么?
- 14. 为什么我们有时会得到一个“文件只能被复制到0节点,而不是1”的错误?
- 15. Client (C) read HDFS files——Client如何读HDFS文件?
- 16. 为什么要用flume导入hdfs,hdfs的构架是怎样的
- 17. HDFS常用命令
- 18. Hadoop为namenode容错提供的两套机制?
- **19. 解释HDFS索引过程**
- 20. 为什么在HDFS,“读”是并行的,但“写”不是?
- 21. 如果您在尝试访问HDFS或者其相应的文件得到一个“连接被拒绝Java异常'的错误会发生什么?
- 三、MapReduce programming model 【large scale data processing】
- 1. MapReduce设计的一个理念
- 2.MapReduce在三个层面上的构思
- 3. MapReduce runtime system三大特色
- 4. MR程序组成【按顺序】
- 5. Combiner的作用是什么?
- 6. MapReduce 计算模式与一般的并行计算、分布式计算的异同:
- 7. Map任务将其输出写入本地磁盘local disk,而非HDFS,为什么?
- 8. Reducer怎么知道要从哪台机器上取得map输出呢?
- 9. Reducer之间如何互相沟通?
- 10. 什么是MapReduce的分区(partition)?
- 11. Mapreduce中溢写Spilling发生在什么时候?
- 12. MR工作timeline?若第一个提前开始reducer完成那个cpu的reduce工作, 它可以在提前结束这个reducer全部的reduce工作吗?
- 13. **‘mapreduce.job.reduce.slowstart.completed.maps’ When to Start Reducers?**
- 14. MapReduce中的失败怎么应对?【Fault-Tolerance特性的体现】
- 15. Map数量上升,是否performance就会上升?
- 16. 1000 files * 3M/file (block size 128MB) will create how many map works?
- 17. Mapreduce程序性能调优的方法?MR架构中,用户需要指定哪些参数?
- 18. 如何选择reducer的个数?Map的个数呢?
- 19. Reduce过程是怎样的?
- 20. 运行mapreduce的两种方法?运行“MapReduce的”程序的语法?
- 21. 如何调试Hadoop的代码?
- 22. 什么是“MapReduce的”默认的输入类型/格式?
- 23. 你知道什么关于“SequenceFileInputFormat”?
- 24. 在“MapReduce框架”解释“分布式缓存”
- 25. 如何用hadoop产生 一个全局排序的文件?
- 四、Yarn【OS of Hadoop】【cluster resource management and task scheduling】
- 1. Yarn三要素功能
- 4. 早期的mapreduce内存模型和YARN在内存管理上的区别?
- 五、HBase
- 六、分布式数据库NoSQL
- 七、其他
- **Hive**
- **Pig**
- **Oozie**
- **Sqoop**
- 参考资料
一、Hadoop = HDFS + Yarn + MR
1. Hadoop 概念了解
Apache开源组织的一个分布式计算开源框架,用于存储大量数据,并发处理/查询在具有多个商用/低成本硬件节点的集群上的那些数据;提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的基础软件架构
-
开发语言:基于Java语言开发的,具有很好的跨平台性
-
**特点:**高可靠性、高效性、高可扩展性、成本低、运行在Linux平台上、支持多种编程语言
-
版本对比:2.0的others就是HBase、Hive
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OohOokNd-1583658203655)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/67e34fa4-f16e-48d3-ae1a-067759a460c9/Untitled.png)]
-
核心技术:
- **HDFS:**分布式文件系统
- 可以运行在廉价商用服务器集群上、低成本高可靠性、很高的吞吐率
- HDFS 允许你以一种分布式和冗余的方式存储大量数据。
- 例如,1 GB(即 1024 MB)文本文件可以拆分为 16 * 128MB 文件,并存储在 Hadoop 集群中的 8 个不同节点上。每个分裂可以复制 3 次,以实现容错,以便如果 1 个节点故障的话,也有备份。
- HDFS 适用于顺序的“一次写入、多次读取”的类型访问
- MapReduce(分布式、并行程序)
- 一个计算框架。它以分布式和并行的方式处理大量的数据。
- 当你对所有年龄>18 的用户在上述 1 GB 文件上执行查询时,将会有“8 个Map映射”函数并行运行,以在其 128 MB 拆分文件中提取年龄> 18 的用户,然后“reduce”函数将运行以将所有单独的输出组合成单个最终结果
- ~~Hbase(提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库)~~
- **HDFS:**分布式文件系统
2. SSH登录 & Hadoop安装方式
-
登录:
- 对于Hadoop的伪分布式和全分布而言,Hadop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护程序,这个过程可以通过SSH登录来实现。(Hadoop没有提供SSH输入密码登录的形式,为了顺利登录每台机器,需要将所有机器配置为名称节点可以无密码登录它们)
-
安装方式:
一、 配置hosts文件
二、 建立hadoop运行帐号
三、 配置ssh免密码连入
四、 下载并解压hadoop安装包
五、 配置namenode,修改site文件(core-site.xml,hdfs-site.xml, mapred-site.xml)
六、 配置hadoop-env.sh文件(JDK)
七、 配置masters和slaves文件
八、 向各节点复制hadoop
九、 格式化namenode
十、 启动hadoop
十一、 用jps检验各后台进程是否成功启动
十二、 通过网站查看集群情况
主要修改配置文件为:core-site.xml, hdfs-site.xml,mapred-site.xml。
3. Hadoop可以运行在哪三种模式
- 非分布式 / 本地 / 独立 / 单机模式:【Hadoop默认模式】无需进行其他配置即可运行,单Java进程,方便进行调试
- 伪分布式模式:Hadoop可以在单节点以上为分布式的方式运行,hadoop进程以分离的Java进程来运行,节点既作为NameNode也作为DataNode,同时读取HDFS中的文件
- 完全分布式模式:在生产环境中使用,使用多个节点构成集群环境来运行Hadoop
- 特点:在该模式下有形成Hadoop集群的机器’N’号。 Hadoop守护进程在计算机集群上运行。有一些“的Namenode”运行一台主机,另一台主机上“Datanode”运行,然后有一些“NodeManager”运行的机器。我们有独立的主机和从机在这种分布的
4. 请列出正常工作的hadoop集群【cluster】中hadoop都需要启动哪些进程,他们的作用分别是什么?
HDFS:1 NN + N DN; YARN:1 RM + N NM
-
HDFS架构:存储数据
- NameNode @ Master Node: HDFS的守护进程,运行在Master节点上,负责存储的文件和目录所有元数据【metadata (file names, block locations)】。负责记录文件是如何分割成数据块,管理文件的块信息,以及块在集群中分布的信息【分别被存储到那些数据节点上】;它的主要功能是对内存及IO进行集中管理
- Secondary NameNode:辅助后台程序,与NN进行通信,以便定期【hourly backup】通过Editlog合并NameNode的变化,保存HDFS元数据的快照;从而它的日志不会过大,可以在NN故障的情况下做为副本使用
- DataNode @ each Slave Node:存储实际disk数据;负责把HDFS数据块读写到本地文件系统
- DataNode定期/周期性向NameNode上报心跳&本节点上块的信息【Heartbeats & Blk report】
- NameNode通过响应心跳来控制DataNode。如果 namenode 没有接收到 datanode 的心跳包,就说明 datanode 已经宕机了,不对它发送任何 IO 请求。
-
YARN架构:资源管理平台
- ResourceManager(Hadoop的2.X):负责YARN上运行的资源和调度
- NodeManager(Hadoop的2.X):可以运行在Slave节点,并负责启动应用程序的容器,监测他们的资源使用情况(CPU,内存,磁盘,网络),并报告这些到ResourceManager
- Container:资源对象封装
- Application Master:当前job的管理者
- Note: 【Hadoop 1.x中】JobTracker split into ResourceManager and ApplicationMaster; TaskTracker turns into NodeManager
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTCrR6Y2-1583658203657)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/de3c6317-2f06-44ee-9f1a-d91690d03e8f/Untitled.png)]
-
JobHistoryServer(Hadoop的2.X):它维护有关的MapReduce工作中的应用终止后的信息
-
hadoop 1.X: JobTracker:运行在Namenode上,负责提交和跟踪MapReduce Job的守护程序。它会负责向Tasktracker分配task,并监控所有运行的task -
~~TaskTracker:Datanode上运行的守护进程。它在Slave节点上负责执行具体的task,并与JobTracker进行交互~~

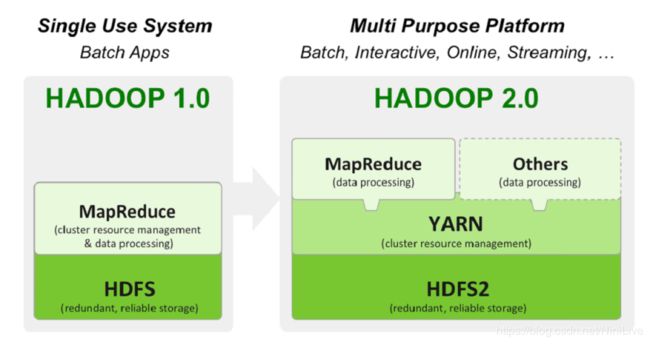
5. 列出的Hadoop 1和2之间的差异。什么是主动和被动的 “Namenodes”?
- 在Hadoop的1.x中,“Namenode”有单r点问题。在Hadoop的2.x中,我们有主动和被动“Namenodes”
- 主动“Namenode”是在集群中运行的Namenode。被动“的Namenode”是一个备用“的Namenode”,里面有主动“的Namenode”的数据。当主动“Namenode”失败,则被动“Namenode”集群中替换主动“Namenode”。因此,集群是从来不会没有“Namenode”,所以它永远不会失败。正因为如此,高可用性可以Hadoop中2.x中来实现
- 在Hadoop的2.X,YARN提供了一个中央资源管理器。通过YARN,你现在可以在Hadoop中运行多个应用程序,共享公共资源。 MR2是一种特殊类型的运行于YARN MapReduce框架之上的分布式应用。其他工具也可以通过YARN执行数据处理。
6. 为什么说hadoop适合处理少量的大文件?(不适合大量的(小)文件)
- 一个原因是FileInputFormat生成的分块是一个文件或该文件的一部分。如果该文件小(意思是比hdfs的块小很多),并且文件数量很多,那么每次map任务只处理很少的输入数据,(一个文件)就会有很多map任务,每次map任务都会造成额外的开销。
- 比如1GB文件分割成16个64MB和100kB的10000个块,**10000个文件每次都需要一个map操作,**作业时间比一个文件上16个map操作慢几十甚至几百倍。
7. 为什么hadoop不适合在非Unix平台上运行?
- hadoop的主体是java语言写成,能够在任意一个安装了JVM的平台上运行。但由于仍然有部分代码(如控制脚本)需要在Unix环境下执行,因而hadoop并不适宜以最终产品的形态运行在非Unix平台上。
8. 什么是传统的关系型数据库和Hadoop之间的基本区别?
- 传统的RDBMS是用于事务性交易系统报告和存档数据,而Hadoop是存储和处理的分布式文件系统的海量数据的方法。如果数据库系统有大量的数据更新,B-Tree的效率就明显落后于MapReduce,因为它需要使用”排序||合并”(sort/merge)来重建数据库。在许多情况下,可以将MapReduce视为关系数据库管理系统的补充。两个系统之间的差异如下图所示:

9. 在hadoop集群中添加新的节点和删除节点的步骤?
-
添加节点:
-
将节点的网络地址添加到include文件中
-
运行以下指令:hadoop dfsadmin –refreshNodes
-
运行以下命令,将经过审核的一些列datanode信息更新至namenode, hadoop mradmin –refreshNodes
-
以新节点更新slaves文件
-
启动新的datanode和namenode
-
检查新的datanode是否出现在网页中
-
-
删除节点:
-
将待解除的节点添加到exclude文件中,不断更新include文件。
-
执行命令:hadoop dfsadmin –refreshNodes。
-
使用一组新的审核过的datanode来更新 namenode设置:hadoop mradmin –refreshNode
-
转到网页界面查看待解除datanode的管理状态是否已经变为“正在解除”,因为此时datanode正在解除的过程中。这些datanode会把它们的快复制到其他的datanode上
-
当所有的datanode的状态变味“解除完毕”之后,表明所有的块已复制完成。关闭已经解除的节点
-
从include文件中移除这些节点,并运行命令:hadoop dfsadmin –refreshNodes;hadoop mradmin –refreshNodes.
-
从slaves文件中移除节点
-
10、Hadoop性能调优?
- 调优可以通过系统配置、程序编写和作业调度算法来进行
- hdfs的block.size可以调到128/256(网络很好的情况下,默认为64)
- 调优的大头:
- mapred.map.tasks、mapred.reduce.tasks设置mr任务数(默认都是1
- 每台机器上的最大map任务数、最大reduce任务数
- mapred.reduce.slowstart.completed.maps配置reduce任务
- 在map任务完成到百分之几的时候开始进入这个几个参数要看实际节点的情况进行配置,reduce任务是在33%的时候完成copy,要在这之前完成map任务(map可以提前完成)
- mapred.compress.map.output,mapred.output.compress配置压缩项,消耗cpu提升网络和磁盘io合理利用combiner注意重用writable对象
二、HDFS【data storage】【written in Java】
Hadoop Distributed File System = 1 NameNode + N DataNode
1. 基本特点
-
分布式存储:
- 使用 客户-服务器模式 ,master 负责进行统一管理各个 slave 的存储空间,slaves 负责存储真实的数据。这样,就能够将多台机器硬盘结合在一起,扩大整机的存储容量。
- 采用主-从结构(Master/Slave)【心跳检测】:NameNode维护/记录DataNode集群内的元数据【存在内存】,对外提供创建、打开、删除和重命名文件或目录的功能。DataNode存储数据,并提负责处理数据的读写请求【参见上面DataNode、NameNode定义】
-
分布式计算:
-
针对MapReduce设计:数据尽可能根据其本地局部性进行访问和计算
-
Google 在 MapReduce 中给出观点 “移动计算比移动数据更划算”,因为数据量很大(几 T),而计算代码很小(几 K)。
-
分布式移动计算的步骤大致可以分为三步:Map(本地计算)、Shuffle(洗牌)、Reduce(合并再计算)。
- Map:在各个 slave 中分别独立进行本地计算,将生成了 KV 对保存在本地。
- Shuffle:将各个 slave 中 Key 值相同的 KV 对通过网络发往同一台机器。
- Reduce:将每台机器各自的 KV 对中的 value 连成链表,进行合并相加。

-
-
冗余存储:
- 命名空间包含:目录、文件、块
- 基本存储单元—Block(数据块)(hadoop2.x默认是128Mb,hadoop1.x是64Mb)
- 块可以被改变/配置;HDFS-site.xml文件中dfs.block.size参数可调大小
- “块”是可被读取或写入的数据的最小量
- HDFS中的文件被分解成块大小的块,它们被存储作为独立的单元
- each block replicates (default 3) across several DN for fault tolerance —> 实现冗余存储,防止一台 slave 宕机导致的数据的丢失 —> reliability (分布式存储可靠性,分布式计算的可靠性)
- 文件每次都是一次性写入的,在任何时候都只能拥有一个写用户
- 你如何在Hadoop中定义“rack-awareness”【机架感知】?
- 这是一种决定如何根据机架定义放置块的方法:Hadoop将尝试限制存在于同一机架中的datanode之间的网络流量,为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上
- 它是在“Namenode”上确定块放置方式,以尽量减少在同一机架内“DataNodes”之间的网络流量的方式。
- 参照下面副本存放策略:“数据的每个块,两个副本将在一个机架中,第三个副本存在于不同的机架”
-
冗余计算:
- 对保存有 file1 的 slave1 和 slave3 同时计算,如果都没有丢失数据,就取最先计算结束的那台机子的计算结果。如果一台丢失,可以使用另一台的
-
基本特征:容量大,高可靠,快速访问,高扩展性,适于顺序读
-
基本需求:数据冗余,异构性,一致性,高效性,安全性
-
基本架构:多层次容错,原子操作保证一致性,自动复制,按块存储,并行读取,效率高
2. 什么是“HDFS块”和“输入分片/分割”之间的区别?
“HDFS块”是数据的基本物理单元,而“输入分割”是数据的逻辑划分
3. 为什么最佳分片大小应该和块(block)大小(64/128MB)相同?
- 因为它是确保可以存储在单个节点上的最大输入块的大小。
- 如果分片跨越两个数据块,那么对于任何一个HDFS节点,基本上都不可能同时存储这两个数据块,因此分片中的部分数据需要数据通过网络传输到map任务节点。与本地数据运行整个map任务相比,这种方法显然效率更低。
4. 为什么HDFS不适合存储小文件?
- 由于NameNode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件的总数受限于NameNode的内存容量,根据经验,每个文件、目录和数据块的存储信息大约占150个字节。所以大量的小文件会占用大量的NN的内存空间,因此HDFS不适合存储大量的小文件
- 当在一个单独文件中的大量的数据,“Namenode”将占据更少的空间。因此,为获得最佳的性能,HDFS支持大数据集,而不是多个小文件
5. 为什么HDFS中的块如此之大的好处和坏处(64 /128 MB)?
- 好处:HDFS中的块比磁盘中的块大,其目的是为了最小化寻址开销。
- 如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个有多个块组成的文件的时间取决于磁盘传输速率
- Keep small table. If 64KB, then 1000x tables to be created**;** 1 map = 1 block, so not too big either
- size depend on true data size and # of map/reduce tasks
- 坏处:如果块(block)的大小过于大之后,有可能会造成在读取相关数据的时候队某个块同时产生大量的IO请求,导致阻塞
6. HDFS文件压缩的好处?
减少存储文件所需要的磁盘空间,并加速数据在网络和磁盘上的传输
7. 当两个客户端尝试访问对HDFS相同的文件,会发生什么?
- HDFS只支持独占写入
- 当第一个客户端连接“NameNode”打开文件进行写入时,“NN”授予租约的客户端创建这个文件
- 当第二个客户端试图打开同一个文件写入时,“NN”会注意到该文件的租约已经授予给另一个客户端,并拒绝第二个客户端打开请求
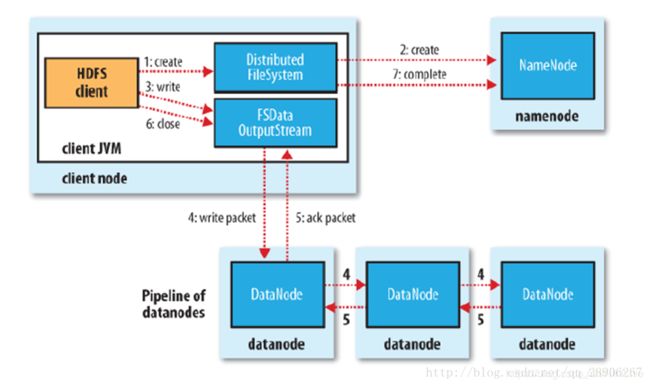
8. 如何写入HDFS?【Write to HDFS】
- Client breaks File.txt into 3 Blocks
- For each block, Client consults NameNode
- Client writes block directly to one DataNode
- DN replicates block 【Replica=3】【Data loss prevention】【Rack-Aware Replica Placement Policy】HDFS副本存放策略?
- 1st:same node as the client (writer) / client outside the cluster then on a random DN
- 2nd : node in different rack (off-rack)
- 3rd: same rack as 2nd, but on different node;Tradeoff between reliability and network (W/R) bandwidth [Communication in-rack → higher bandwidth, lower latency]
- 其他副本放在集群中随机选择的节点上,不过系统会尽量避免在同一个机架上放太多副本
- Why not THREE nodes at three racks?
- Higher ToR switches: Rack failure << node failure
9. Replication Management
- balance storage utilization across DN without reducing block’s availability
- NN ensures each block has intended # of replicas
- NN ensures not all block replicas located on 1 single rack
- DN block report Under/over-replicated detection
- Over replicated? chooses a replica to remove
- not to reduce # of racks that host replicas
- remove a replica from DN with least available disk space
- Over replicated? chooses a replica to remove
10. NameNode的地位/重要性?HDFS如何管理数据复制?
- NameNode是Hadoop的大脑,全权管理数据块的复制、分配,还为客户提出请求时的数据提供特定地址;它周期性的从集群中的每个Datanode接收两样内容:
- 心跳信号:接收到心跳信号意味着该DataNode节点工作正常
- 块状态报告:包含了一个该DataNode上所有数据块的列表
- 数据块(block)复制:
(1)NameNode发现部分文件的Block数不符合最小复制数或者部分DataNode失效
(2)通知DataNode相互复制Block
(3)DataNode开始相互复制
11. 是否可以在不同集群之间复制文件?如果是的话,怎么能做到这一点?
是的,可以在多个Hadoop集群之间复制文件,这可以使用分布式复制来完成
12. 当NameNode关闭时会发生什么?
如果NameNode关闭,文件系统将脱机
13. 添加新datanode后,作为Hadoop管理员需要做什么?
- 需要重新启动平衡器才能在所有数据节点之间重新平均分配数据,以便Hadoop集群自动查找新的datanode,优化集群性能
14. 为什么我们有时会得到一个“文件只能被复制到0节点,而不是1”的错误?
这是因为“Namenode”没有任何可用的DataNode
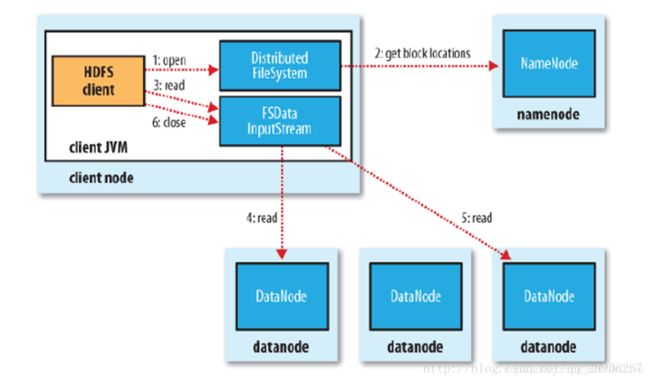
15. Client © read HDFS files——Client如何读HDFS文件?
- Client receives DataNode list for each block —> picks 1st DataNode for each block —> reads blocks sequentially
(√) Client ask NameNode for block location —> NameNode return location —> Client reads data block directly from DataNode
16. 为什么要用flume导入hdfs,hdfs的构架是怎样的
- flume可以实时的导入数据到hdfs中,当hdfs上的文件达到一个指定大小的时候会形成一个文件,或者超过指定时间的话也形成一个文件
- **【同1中分布储存】**文件都是存储在datanode上面的,namenode记录着datanode的元数据信息,而namenode的元数据信息是存在内存中的,所以当文件切片很小或者很多的时候会卡死
17. HDFS常用命令
- 列出HDFS文件:Hadoop fs -ls
- 创建指定的一个或多个文件夹:Hadoop fs -mkdir
- 上传文件到HDFS:Hadoop dfs -put test1 test /hadoop目录下的test1文件上传到HDFS上并重命名为test/
- 将HDFS中的文件复制到本地系统中:hadoop dfs -get test0 test00 /将HDFS中的test0复制到本地系统并命名为test00/
- 删除HDFS下的文档:hadoop dfs -rmr test00 /删除HDFS下名为test00的文档/
- 查看HDFS下的某个文件:hadoop dfs -cat ttt /查看HDFS下ttt文件中的内容/
- 报告HDFS的基本统计信息:hadoop dfsadmin -report
- 退出安全模式:hadoop dfsadmin -safemode leave
- 进入安全模式:hadoop dfsadmin -safemode enter
- 取得安全模式:hadoop dfsadmin –safemode get
- 等待安全模式:hadoop dfsadmin –safemode wait
- 重新启动“Namenode”:点击stop-all.sh,然后点击start-all.sh
18. Hadoop为namenode容错提供的两套机制?
- 第一种机制:备份那些组成文件系统元数据持久状态的文件。
- Hadoop可以通过配置使namenode在多个文件系统上保存数据的持久状态。这些写操作是实时同步的,是原子操作。
- 一般的配置时,将持久的状态写入本地磁盘的同时,写入一个远程挂在的网络文件系统(NFS)
- 第二种机制:运行一个辅助的namenode,但它不能被用作namenode,这个辅助的namenode的重要作用是定期通过编辑日志合并命名空间镜像,以防止编辑日志过大。
- 这个辅助的namenode一般在另外一台单独的物理计算机上运行,因为它需要占用大量的CPU时间与namenode相同容量的内存来执行合并操作。它会保存合并后的命名空间镜像的副本,并在namenode发生故障时启用。
- 但是辅助namenode保存的状态总是滞后于主节点,所以在主节点全部失效的时候,难免会丢失部分数据。在这个时候一般情况是,把存储在NFS上的namenode元数据复制到辅助namenode并作为新的主namenode运行。
19. 解释HDFS索引过程
Hadoop的有它自己的索引数据的方式。取决于块大小,HDFS将继续存储数据的最后部分。它还会告诉你数据的下一部分的位置
20. 为什么在HDFS,“读”是并行的,但“写”不是?
使用的MapReduce程序,该文件可以通过分割成块被读取。写入时MapReduce并行不能适用
21. 如果您在尝试访问HDFS或者其相应的文件得到一个“连接被拒绝Java异常’的错误会发生什么?
- 这可能意味着“NameNode”不工作了:
- “NameNode”可能是在“安全模式”
- 或“NameNode”的IP地址可能改变
三、MapReduce programming model 【large scale data processing】
MR is a software framework to support distributed computing on large data sets but simple operation on clusters
【MR是一个框架或用于通过使用分布式编程的计算机的集群处理大型数据集的编程模型】
MapReduce is now an “application” of YARN.
1. MapReduce设计的一个理念
MapReduce设计的一个理念就是**“计算向数据靠拢”**,而不是“数据向计算靠拢”,因为引动数据需要大量的网络传输开销,尤其是在大规模数据环境下,这种开销尤为惊人,所以,移动计算要比移动数据更加经济
2.MapReduce在三个层面上的构思
- 如何对付大数据:分而治之
- 上升到抽象模型:映射和归约——Mapper和Reducer
- 上升到架构:统一架构,为程序员隐藏系统细节
- 总结——基本思想:“分而治之、映射和归约"
- 将需要处理海量数据的大任务分解成若干个处理数量级更低的数据的小任务【数据块】,并通过分配到不同的计算设备上【自动调度计算节点】,高性能地并行解析、计算,中间结果数据会进行合并,使得数据通信开销减少,最后再归并汇总计算
- 提升了整个任务处理的效率和设备的利用率,降低了运行时间和传输开销,使得计算性能得到优化
3. MapReduce runtime system三大特色
- Fault-tolerance:支持出错检测和恢复
- I/O scheduling:并行计算parallelized computation
- Job status monitoring:通过监控一个节点的运行状态和时间来判断其是否正常,提高了技术的可靠性
4. MR程序组成【按顺序】
- **Mapper:【output over network】用于将文件中的大数据筛选并以键值对【key-value pair】**的形式输入到系统中
- **Combiner:**用于将Mapper读取的数据按照键进行简单的汇总
- **Partitioner:**用于按照给定的划分规则划分分区,将数据分别传输到不同的Reducer中;total # of partitions = # of reduce tasks
- **Reducer:【output to disk】**分成多个,每个Reducer将接收到的数据进行统计和求值,以键值对的方式输出需要的数据
- **Driver:**接收从多个Reducer中得到的数据并汇总,生成文件
5. Combiner的作用是什么?
- Combiner属于优化方案,把map的输出结果进行合并之后作为reduce的输入,减少map和reduce任务之间的数据传输,减少network congestion,提高效率
- 不管调用combiner多少次,reducer的输出结果都是一样的
6. MapReduce 计算模式与一般的并行计算、分布式计算的异同:
- **同:**把一个大问题分解成许多子问题,利用多个计算节点/CPU 核心分别进行处理,以缩短解决整个问题的时间
- 异:并行计算是相对于串行计算而言的,它通常关注单个节点上的多个 CPU 核心之间的并行协作,而不是节点间的通信
- MapReduce 和分布式计算通常将任务分发到网络中的多个节点,分别处理后再汇总结果。 MapReduce 对一次计算过程的 Map 和 Reduce 阶段做了明显的定义和区分,而一般的分布式计算根据任务的不同有可能具有其他形式的阶段性特征
7. Map任务将其输出写入本地磁盘local disk,而非HDFS,为什么?
- 因为map的输出是中间结果【intermediate result】:该中间结果由reduce任务处理后才产生最终的结果;一旦作业完成,map的输出结果就可以删除。因此如果把它存储在HDFS中并实现备份,难免小题大做
8. Reducer怎么知道要从哪台机器上取得map输出呢?
- map任务完成后,通知其application master,这些通知都是通过心跳机制传输。Reducer中的一个线程定期询问application master以便获取map输出的位置,直到获得所有输出位置
9. Reducer之间如何互相沟通?
- MapReduce编程模型不允许Reducer相互沟通,Reducer单独运行
10. 什么是MapReduce的分区(partition)?
- MapReduce的分区可以确保”同一个key的所有值去到同一个“reducer”,从而允许“reducer”对应的map输出的平均分布。它通过确定哪个“reducer”是负责该特定键从而把map输出重定向给reducer
11. Mapreduce中溢写Spilling发生在什么时候?
- 首先每个map任务都有一个环形缓冲区用于存储任务输出,默认大小为100MB,此值可以通过io.sort.mb属性来调整。一旦缓冲内容达到阈值(io.sort.spill.percent,默认为0.8),一个后台线程便开始把内容溢写(spill)到磁盘【copying the data from memory buffer to disk】在溢写到磁盘过程中,map输出继续写到缓冲区,但如果在此期间缓冲区被填满,map会被阻塞直到写磁盘过程完成
- Spilled Records: indicates how much data, map, reduce tasks wrote (spilled) to disk. Higher numbers make the job go slower
12. MR工作timeline?若第一个提前开始reducer完成那个cpu的reduce工作, 它可以在提前结束这个reducer全部的reduce工作吗?
- Reduce task can be launched and begin copying data as soon as the first mapper
- 不可以, 其他cpu的map结果可能需要到这个reducer
13. ‘mapreduce.job.reduce.slowstart.completed.maps’ When to Start Reducers?
- Default = 0.05, R start when 5% M tasks complete
- ****= 1: wait for ALL Map finish before starting reducers [Underutilized network bandwidth problem] ****
- = 0: start reducers right away may cause R “Slot Hoarding” problem (idle waiting for slow mappers)
14. MapReduce中的失败怎么应对?【Fault-Tolerance特性的体现】
- **task crashes:【运行任务失败】:**map或reduce任务中的代码异常、子进程JVM突然退出等
- Retry on another node
- same task fails repeatedly:fail the job 或 ignore that input block
- node crashes:
- Re-launch current tasks on other nodes
- Re-run runned maps
- task goes slowly:
- Launch 2nd task copy on another node (speculative execution)
- Take output of whichever copy finishes first, and kill the other
15. Map数量上升,是否performance就会上升?
×, ∵ Limited by block number
16. 1000 files * 3M/file (block size 128MB) will create how many map works?
【one file = one map】1000 map. To reduce the number, can merge
17. Mapreduce程序性能调优的方法?MR架构中,用户需要指定哪些参数?
- mapper的数量、reducer的数量、combiner、中间值的压缩(map输出压缩)、自定义序列、调整shuffle相关参数(调整环形缓冲区的大小、减少溢写的次数、io.sort.factor 合并文件时最多合并的流的数量等)、reduce端的性能调优、推测执行(默认是启用的),partition
- 指定参数:
- 在分布式文件系统作业的输入位置
- 在分布式文件系统作业的输出位置
- 输入格式
- 输出格式
- 包含“map”功能类
- 包含“reduce”功能类
18. 如何选择reducer的个数?Map的个数呢?
- 真实的应用中,都把作业设置成一个较大的数字,否则由于所有的中间数据都会放到一个reducer中,作业处理十分低效。本地运行作业时,只支持0个或者1个reducer。
- Reducer最优个数和集群中可用的任务槽数有关。总槽数由集群中的节点数和每个节点的任务槽数相乘得到
- 一个常用的方法就是设置的reducer数比总槽数稍微少一点,给reducer任务留点余地。如果reduce任务很大,比较明智的是使用更多的reducer,使得任务粒度更小,从而使任务的失败不至于显著影响作业的执行情况
- 规律:
- M >> R> # of workers; One block (64MB) per map
- M = R = (# of cores available - 1)
- Shuffled M ≤ M * R
19. Reduce过程是怎样的?
- Shuffle/Copy: moving map outputs (sorted) to the reducers, Guarantees keys ordered + all values with particular key presented to same reducer
- Sort: framework merge sorts Reducer inputs by keys; Automatically sorted before they are presented to the Reducer.
- Reduce [output store in Disk/HDFS]: Perform the actual Reduce function that you wrote; output is not re-sorted/merged
20. 运行mapreduce的两种方法?运行“MapReduce的”程序的语法?
- job.submit(); ToolRunner.run()
- Hadoop jar file.jar / input_path / output_path
21. 如何调试Hadoop的代码?
- 使用计数器
- 利用Hadoop框架所提供的Web UI
22. 什么是“MapReduce的”默认的输入类型/格式?
默认情况下是文本
23. 你知道什么关于“SequenceFileInputFormat”?
“SequenceFileInputFormat”是序列文件内读取输入格式。键和值是用户定义的。它是被一个“MapReduce的”作业的输出之间传递数据到一些其他的“MapReduce的”作业的输入优化的特定压缩二进制文件格式
24. 在“MapReduce框架”解释“分布式缓存”
- “MapReduce框架”提供的一个重要特征
- 当你想在Hadoop集群共享跨多个节点的文件,“分布式缓存”便会被用到。这些文件可以以可执行的“jar”文件或简单的“属性”文件驻留
- 特性:在作业执行时间“只读”
25. 如何用hadoop产生 一个全局排序的文件?
- 方案一:最简单的的方法就是使用给一个分区,但是该方法在处理大型文件的时候效率极低。
- 方案二:首先创建一系列排好序的文件;其次,串联这些文件;最后生成一个全局排序的文件。主要的思路是使用一个partitioner来描述输出的全局排序。其关键点是如何划分各个分区,一般在划分分区的时候我们会用到采样器。采样的核心思想是只查看一小部分键,获得键的近似分布,并由此构建分区
四、Yarn【OS of Hadoop】【cluster resource management and task scheduling】
Yarn = Global ResourceManager + Per-server NodeManager + Per-application ApplicationManager
Yarn 除了像一般的操作系统功能一样管理整个集群的计算资源(CPU、内存等),还提供用户程序访问系统资源的 API
1. Yarn三要素功能
- ResourceManager【RM】
- 接受客户端的请求【./bin/yarn jar xxx.jar wordcount /input /output】
- 启动、监控[ApplicationMaster]
- 监控NodeManager
- 资源分配和任务调度
- NodeManager【NM】
- worker daemon that launch AM and task Containers
- 单个节点上的资源管理
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
- ApplicationMaster【AM】
- 当前任务的管理者,任务运行结束后自动消失
- 数据切分
- 为当前程序申请资源,并分配给内部任务; supervisory task requesting resources needed for executing tasks based on “containers”
- 任务的监控【tracking task status, monitoring】和容错
- Container
- JVM process, 不等于Docker Container
- Launch and monitor by the NM
- (location) Scheduled by the RM
- run YARN task
- 每一个Container ID对应specific Resource (vcore, RAM) allocated
- 对当前任务运行环境的一个抽象,封装了CPU、内存、网络带宽等等和任务相关的信息
2. Control Flow
- Resource Request → Granting a container→ Container-launch request→ NM launches the container
- AM→RM→AM→NM→Container
3. MR文件写M=16, R=8, H cluster metric显示containers running=25, why? 什么时候会
25=# of M + # of R + AM(x1); 当cpu/memory不足时, running总是<=sum【container running不表示同一时刻同时运行的个数】
4. 早期的mapreduce内存模型和YARN在内存管理上的区别?
- 早期的mapreduce会设定固定的map槽数和reduce槽数,但是在YARN中,节点管理器(NodeManager)从一个内存池中分配内存,这意味着可同时运行的数量依赖于内存需求总量,而非槽的数量
- YARN会随着计算过程的变化去调整map槽和reduce槽,因为在计算前期可能对map槽的需求很大,而在计算后期对reduce槽的需求更大,因此实现这样细粒度的去控制内存分配使得计算过程更加合理和高效
5. Configurations [to make reasonable # of containers in 1 VM]
- yarn-site.xml:
- NM: ①yarn.nodemanager.resource.memory-mb: Default 8GB
- RM: ②yarn.scheduler.minimum/maximum-allocation-mb: Default 1/8GB
- mapred-site.xml:
- ④mapreduce.map/reduce**.java.opts**: Java heap size (store java object) for each map/reduce task (Default 200 MB);
- If set too low, could lead to Java Out of Memory (OOM) errors
- solution: xxx map / reduce.java.opts < ③xxx map / reduce.memory.mb
- Yarn.nodemanager**.vmem-pmem-ratio** (default 2.1)
- Garbage Collect (GC) time:
- high=not enough CPU memory allocated & nearly crash
- best GC=0
- solution: ↑ CPU memory assigned
五、HBase
Hbase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据
- 解释hbase中的“WAL”和“Hlog”
“WAL”(预写日志)是类似于“MySQL的BIN”登录;它记录中发生的数据的所有更改。它是Hadoop中“HLogkeys”标准序列文件。这些密钥由一个序列号,以及实际数据,并用于重播尚未在服务器崩溃后保留的数据。所以,在服务器发生故障的情况下,“WAL”作品作为生命线和检索丢失的数据。
- 提起“HBase的”和“关系型数据库”之间的区别是什么?
HBase的和关系型的数据库-TOP-50-Hadoop的采访,问题
- 你能在任何特定的Hadoop版本和hbase建立spark吗?
是的,你可以建立“spark”为特定的Hadoop版本
六、分布式数据库NoSQL
- NoSQL类型
- Key-value(K-V数据库):使用键值(key-value)存储的数据库,其数据按照键值对的形式进行组织、索引和存储。
- Document-based(文档数据库):旨在将半结构化数据存储为文档的一种数据库,通常以JSON或XML格式存储数据。
- Column-based(列式数据库):以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询。
- Graph-based(图形数据库):应用图像理论存储实体之间的关系信息,解决关系型数据库存储和处理复杂关系型数据功能较弱的问题。
- 优点:
- 非关系型,不需要表
- 数据被复制到多个节点,可以进行分区
- 可水平扩展
- 成本低,易于实施
- 适于海量数据写入
- 快速键值访问
- 缺点:
- 不完全支持关系型特征,e.g. join, group by
- 没有声明式查询语言,e.g. SQL
- 事务库事务功能的缺失,e.g. ACID
- 不易于与其他支持SQL的应用软件集成
- NoSQL数据库与传统的关系数据库之间的关系:
- 关系数据库读写慢,处理海量数据效率低下。而NoSQL处理数据快,适合于云计算中处理大量数据,支持海量数据的分布式存储。
- 关系数据库支持SQL而NoSQL不支持。
- 传统的关系数据库则很难处理大量的非结构化数据。而NoSQL不是关系型数据库管理系统,它支持处理非结构化的数据,主要用于云计算上。
- 关系数据库成本高,NoSQL数据库成本低廉。
- 关系数据库很难实现扩展,通常是纵向扩展,但到达一定程度时只能横向扩展。而NoSQL很容易实现可伸缩性,包括向上扩展与水平扩展。
七、其他
-
什么是“speculative running”在Hadoop中?
- 如果一个节点出现运行一个任务较慢,主节点可以冗余另一个节点上执行同一任务的另一实例。这里,它第一个完成任务的将被接受,而另一个被杀死。这个过程被称为“speculative running”
- 当一个作业由几百或几千个任务组成时,可能出现任务执行缓慢,当一个任务执行比平均执行速度慢的时候,启动另一个相同的任务作为备份(当所有的任务都已经启动之后),其中一个任务完成之后,任何正在运行的重复任务将被终止,默认情况下是启动的。这就是推测执行。
-
你如何在Hadoop集群中实现HA(高可用性)?
您可以设置HA两种不同的方式;使用Quorum Jounal Manager(QJM),或NFS共享存储
-
应该使用哪种压缩格式?
- 使用容器格式,例如顺序文件、RCfile或者Avro数据文件,所有这些文件格式同时支持压缩和切分。通常最好与一种快速压缩工具联合使用,例如LZO,LZ4,或者Snappy
- 使用支持切分的压缩格式,例如bzip2或者使用索引实现切分的压缩格式,例如LZO
- 在应用中将文件切分成块,并使用任意一种压缩格式为每个数据块建立压缩文件(不论它是否支持切分)。这种情况下,需要合理选择数据块的大小,以确保压缩后数据块的大小近似于HDFS块的大小
- 对于大文件来说,不要使用不支持切分整个文件的压缩格式,因为会失去数据的本地特性,进而造成MapReduce应用效率低下。
-
RPC序列化格式的4大理想属性?
- 紧凑—紧凑格式能充分利用网络带宽(数据中心最稀缺的资源)。
- 快速—进程间通信新城了分布式系统的骨架,所以需要尽量减少序列化和反序列化的性能开销,这是最基本的。
- 可扩展—以可以透明地读取老格式的数据。
- 支持互操作—以可以使用不同的语言读/写永久存储的数据。
-
Hadoop的skipping mode是什么?具体的运行机制是什么?
-
大型数据集经常有少数坏的数据,比如字段确实等,但是这些少数的坏的数据并不影响最终的结果,但是在运行mapreduce的时候却会出现异常和失败,为了解决这个问题,skipping mode来了,启动是skipping mode之后,任务将正在处理的记录报告给
tasktracker。任务失败时,tasktracker重新运行该任务,跳过导致任务失败的记录。由于额外的网络浏量和记录错误以维护失败记录范围,所以只有在任务失败后两次之后才会使用skipping mode -
具体的运行机制:
a) 任务失败
b) 任务失败
c) 开启skipping mode。任务失败,但是失败记录有tasktracker记录保存。
d) 任然启用skipping mode。任务继续执行,但跳过上一次尝试中失败的坏记录。
-
在默认情况下,skipping mode是关闭的。每次任务尝试,skippingmode只能检测出一个坏记录,因此这种机制仅适合检测个别坏记录。为了给skipping mode足够多尝试次数来检测并跳过一个输入分片中的所有坏记录,需要增加最多任务尝试次数(通过mapred.map.max.attemps和 mapred.reduce.max.attemps进行设置)。
-
Hadoop检测出来的坏记录以序列化文件形式保存在_logs/skip子目录下的作业输出目录中
-
-
分片大小的计算公式?
- max(minmumSize,min(maximumSize,blockSize))
- 在默认一般情况下:mimumSize
-
什么方法可以避免文件切分?
- 第一:修改minmumSize的参数,使之大于文件的大小
- 第二:使用FileInputFormat具体子类,并且重载isSplitable()方法把返回值设为false
-
“zookeeper”在Hadoop集群中的作用?
“zookeeper”的目的是集群管理。 “zookeeper”将帮助你实现的Hadoop节点之间的协调。 也有助于:
Hive
-
Hive中存放是什么?
表。存的是和hdfs的映射关系,hive是逻辑上的数据仓库,实际操作的都是hdfs上的文件,HQL就是用sql语法来写的MR程序。
-
Hive与关系型数据库的关系?
没有关系,hive是数据仓库,不能和数据库一样进行实时的CURD操作。是一次写入多次读取的操作,可以看成是ETL工具。
-
什么是Hive中的“SERDE”?
通过“SERDE”你可以让“Hive”来处理记录。“SERDE”是一种“串行”和一个“解串器”的组合。 “hive”使用“SERDE”(和“FILEFORMAT”)来读取和写入表行。
-
可以默认的hive Metastore”被多个用户(进程)在同一时间使用?
“Derby数据库”是默认的“hive Metastore”。多个用户(进程)不能在同一时间访问它。它主要用于执行单元测试。
-
“hive”存储表中的数据的默认位置是?
HDFS://NameNode/用户/hive/warehouse
-
Hive中什么是通用的UDF?
这是使用Java程序来服务一些具体根据现行的功能不需要覆盖“hive”创建UDF。它可以通过编程方式检测输入参数的类型,并提供适当的响应。
Pig
-
什么是“Bag”?
Bag是“Pig”的数据模型之一。这是可能出现的重复元组的无序集合。 “包”在分组时用于存储集合。 Bag的大小是本地磁盘大小,这意味着“bag”的大小是有限的大小。当一个“bag”是满的,“Pig”将这个“bag”放到本地磁盘,只保留“bag”的某些部分在内存中。这是没有必要的完整“bag”装配到存储器。我们代表用“{}”代表bag。
-
什么是“FOREACH”?
- “FOREACH”用于转换数据,并产生新的数据项。名称本身表示为数据“bag”的各要素,将执行相应的动作。
- 语法:FOREACH bagname GENERATE表达式,表达式,… …
- 这句话的意思是,经过提到的表达式“生成”将应用于数据“bag”当前记录
-
为什么我们需要在“pig”规划“的MapReduce”?
“pig”是一个高层次的平台,Hadoop的数据分析问题,更容易执行。我们使用这个平台的语言是“pig拉丁”。写在“pig拉丁”程序就像是写在SQL,这里我们需要执行引擎来执行查询的查询。所以,当一个程序是用“隐语”,“pig编译器”可将程序转换成“MapReduce的”工作。在这里,“MapReduce的”充当执行引擎。
-
pig中的co-group是什么?
“co-group”通过分组来连接数据。这组需要他们有共同的域的元素,然后返回一组包含两个独立的“bag”的记录。第一个“bag”包括从第一数据与公共数据集记录集,而第二个“bag”包括从所述第二数据集与公共数据集设定记录。
-
什么是“猪拉丁”不同的关系操作?
i. for each
ii. order by
iii. filters
iv. group
v. distinct
vi. join
vii. limit
Oozie
-
你如何配置Hadoop的一个“Oozie的”工作?
“Oozie的”集成了Hadoop的堆栈支持多种类型的Hadoop作业,如“Java的MapReduce的”,“流MapReduce”,“pig”,“hive”和“Sqoop”中的其余部分
Sqoop
- 解释在Hadoop中“Sqoop”
- hadoop生态圈上的数据传输工具:用于一个RDBMS并在Hadoop HDFS之间传送数据的一种工具
- 可以将关系型数据库RDBMS(如MySQL或Oracle)的数据导入非结构化的hdfs、hive或者Hbase中,也可以将hdfs中的数据导出到关系型数据库或者文本文件中。使用的是MR程序来执行任务,使用jdbc和关系型数据库进行交互
- Sqoop工作原理是什么?
- import原理:通过指定的分隔符进行数据切分,将分片传入各个map中,在map任务中在每行数据进行写入处理没有reduce
- export原理:根据要操作的表名生成一个java类,并读取其元数据信息和分隔符对非结构化的数据进行匹配,多个map作业同时执行写入关系型数据库
参考资料
- Cloud Computing Course Material
- 云计算知识点梳理
- 云计算知识点
- 【云计算与大数据】知识点总结
- 如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系?
- hadoop面试常见问题及相关总结
- 50个Hadoop的面试问题
- hadoop常见的面试题
- TOP 25大常见Hadoop面试题及答案
- hadoop知识点汇总
- Hadoop基础知识总结