Hadoop集群集成kerberos
上周周会领导让研究kerberos,要在我们的大集群中使用,研究任务指派给了我。这周的话也是用测试集群大概的做了一遍。目前为止的研究还比较粗糙,网上众多资料都是CDH的集群,而我们的集群是不是用的CDH,所以在集成kerberos的过程中有一些不同之处。
测试环境是由5台机器搭建的集群,hadoop版本是2.7.2。5台机器host分别是
rm1、rm2、test-nn1、test-nn2、10-140-60-50。选取rm1为kdc服务器。
1、安装软件
rm1上安装krb5、krb5-server和krb5-client
命令行执行 : yum install krb5-server krb5-libs krb5-auth-dialog krb5-workstation -y
其它4台机器安装krb5-level、krb5-workstation
4台机器命令行分别执行 : yum install krb5-devel krb5-workstation -y
2、配置文件修改
kdc服务器涉及到的配置文件有3个
/etc/krb5.conf 、/var/kerberos/krb5kdc/kdc.conf 、/var/kerberos/krb5kdc/kadm5.acl
krb5.conf文件内容如下:
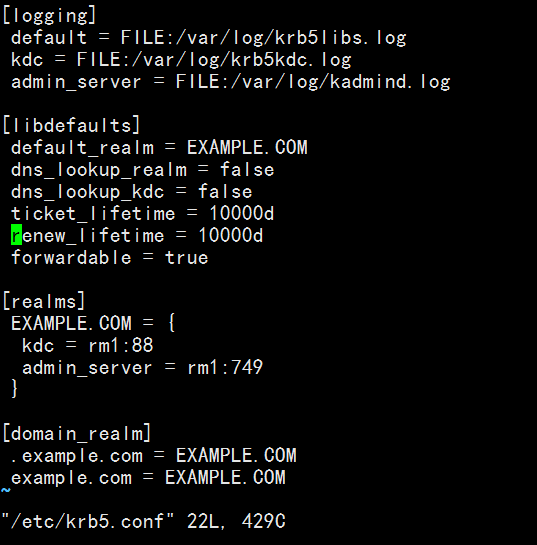
其中的ticket_lifetime和renew_lifetime是比较重要的参数,这两个参数都是时间参数,前者表示的是访问凭证的有效时间,默认是24小时,这里我已经做了修改,修改成了10000天。因为有效期过期后,再在节点上执行hadoop fs -ls类似的命令都会失效,凭证默认存放在/tmp下,文件格式为krb5cc_xxx(xxx是用户代码,即/etc/passwd中用户对应的代码)。如何修改下文会介绍。
另外可以修改的就是[libdefaults]中的default_realm参数,图中为EXAMPLE.COM,这里可以任意命名字符串,大写,以.COM结尾。[realms]中的参数也需要对应修改,前面介绍了我选择的是rm1作为kdc服务器。
配置完后将该文件分发到其它所有节点的/etc下。
kdc.conf文件内容如下:
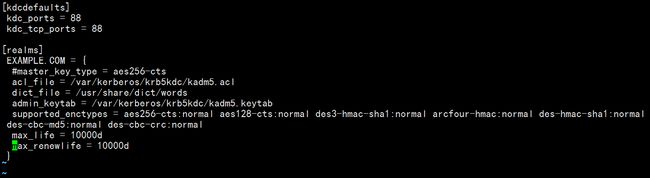
这里还是配置了max_life和max_renewlife参数的值为10000天,其它都是默认值。
kadm5.acl文件可以不做改动。
集群每个节点安装JCE,需要安装与当前java版本相同的JCE。我使用的是java1.7的,下载链接如下:
http://www.oracle.com/technetwork/java/embedded/embedded-se/downloads/jce-7-download-432124.html
下载完后得到的压缩包解压,将其中的local_policy.jar以及US_export_policy.jar复制到JAVA_HOME/jre/lib/security下。
3、创建数据库
软件安装完毕后,需要在rm1上运行初始化数据库命令,命令行执行:
kdb5_util create -r JAVACHEN.COM -s。这里要根据krb5.conf中default-realm中对应的值。运行完毕后在/var/kerberos/krb5kdc/下生成principal数据库。
4、启动服务
在rm1命令行上执行:
service krb5kdc start
service kadmin start
5、创建principals
在rm1命令行上键入kadmin.local后,而后键入
addprinc -randkey hadoop/rm1@EXAMPLE.COM(我这里配置文件中的是EXAMPLE.COM)
addprinc -randkey hadoop/rm2@EXAMPLE.COM
addprinc -randkey hadoop/test-nn1@EXAMPLE.COM
addprinc -randkey hadoop/test-nn2@EXAMPLE.COM
addprinc -randkey hadoop/10-140-60-50@EXAMPLE.COM
addprinc -randkey HTTP/rm1@EXAMPLE.COM
addprinc -randkey HTTP/rm2@EXAMPLE.COM
addprinc -randkey HTTP/test-nn1@EXAMPLE.COM
addprinc -randkey HTTP/test-nn2@EXAMPLE.COM
addprinc -randkey HTTP/10-140-60-50@EXAMPLE.COM因为集群所有的服务都是以hadoop用户启动的,所以仅需要创建hadoop的principals。CDH集群则需要hdfs、yarn、mapred3个用户
6、创建keytab文件
rm1命令行执行:
kadmin.local -q "xst -k hadoop.keytab hadoop/rm1@EXAMPLE.COM"
kadmin.local -q "xst -k hadoop.keytab hadoop/rm2@EXAMPLE.COM"
kadmin.local -q "xst -k hadoop.keytab hadoop/test-nn1@EXAMPLE.COM"
kadmin.local -q "xst -k hadoop.keytab hadoop/test-nn2@EXAMPLE.COM"
kadmin.local -q "xst -k hadoop.keytab hadoop/10-140-60-50@EXAMPLE.COM"
kadmin.local -q "xst -k HTTP.keytab HTTP/rm1@EXAMPLE.COM"
kadmin.local -q "xst -k HTTP.keytab HTTP/rm2@EXAMPLE.COM"
kadmin.local -q "xst -k HTTP.keytab HTTP/test-nn1@EXAMPLE.COM"
kadmin.local -q "xst -k HTTP.keytab HTTP/test-nn2@EXAMPLE.COM"
kadmin.local -q "xst -k HTTP.keytab HTTP/10-140-60-50@EXAMPLE.COM"这样会在/var/kerberos/krb5kdc目录下生成hadoop.keytab和HTTP.keytab文件。
继续rm1命令行键入 ktutil
继而键入 rkt hadoop.keytab 回车
再次键入 rkt HTTP.keytab 回车
最后键入 wkt hdfs.keytab 回车
这样即生成文件hdfs.keytab,用klist命令显示列表(部分内容)
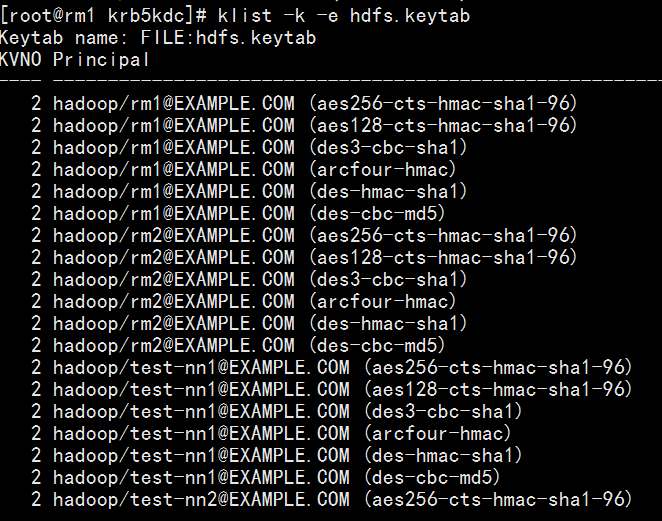
7、部署keytab文件
将rm1上生成的hdfs.keytab文件分发到各个节点的/etc/hadoop 下。安全起见,可以将该文件权限设置为400。
8、停止集群所有服务
9、修改相关配置文件
a、core-site.xml,加入
<property>
<name>hadoop.security.authenticationname>
<value>kerberosvalue>
property>
<property>
<name>hadoop.security.authorizationname>
<value>truevalue>
property>
b、hdfs-site.xml,加入
<property>
<name>dfs.block.access.token.enablename>
<value>truevalue>
property>
<property>
<name>dfs.https.enablename>
<value>truevalue>
property>
<property>
<name>dfs.https.policyname>
<value>HTTPS_ONLYvalue>
property>
<property>
<name>dfs.namenode.https-address.pin-cluster1.testnn1name>
<value>test-nn1:50470value>
property>
<property>
<name>dfs.namenode.https-address.pin-cluster1.testnn2name>
<value>test-nn2:50470value>
property>
<property>
<name>dfs.https.portname>
<value>50470value>
property>
<property>
<name>dfs.namenode.keytab.filename>
<value>/usr/local/hadoop/etc/hadoop/hdfs.keytabvalue>
property>
<property>
<name>dfs.namenode.kerberos.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>dfs.namenode.kerberos.internal.spnego.principalname>
<value>HTTP/[email protected]value>
property>
<property>
<name>dfs.datanode.data.dir.permname>
<value>700value>
property>
<property>
<name>dfs.datanode.addressname>
<value>0.0.0.0:1004value>
property>
<property>
<name>dfs.datanode.http.addressname>
<value>0.0.0.0:1006value>
property>
<property>
<name>dfs.datanode.keytab.filename>
<value>/usr/local/hadoop/etc/hadoop/hdfs.keytabvalue>
property>
<property>
<name>dfs.datanode.kerberos.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<property>
<name>dfs.journalnode.keytab.filename>
<value>/usr/local/hadoop/etc/hadoop/hdfs.keytabvalue>
property>
<property>
<name>dfs.journalnode.kerberos.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>dfs.journalnode.kerberos.internal.spnego.principalname>
<value>HTTP/[email protected]value>
property>
<property>
<name>dfs.web.authentication.kerberos.principalname>
<value>HTTP/[email protected]value>
property>
<property>
<name>dfs.web.authentication.kerberos.keytabname>
<value>/usr/local/hadoop/etc/hadoop/hdfs.keytabvalue>
property>注意 : dfs.https.policy项,一定是https而不是http,否则启动服务会报错。
c、yarn-site.xml,加入
<property>
<name>yarn.resourcemanager.keytabname>
<value>/usr/local/hadoop/etc/hadoop/hdfs.keytabvalue>
property>
<property>
<name>yarn.resourcemanager.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>yarn.nodemanager.keytabname>
<value>/usr/local/hadoop/etc/hadoop/hdfs.keytabvalue>
property>
<property>
<name>yarn.nodemanager.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>yarn.nodemanager.container-executor.classname>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutorvalue>
property>
<property>
<name>yarn.nodemanager.linux-container-executor.groupname>
<value>hadoopvalue>
property>
<property>
<name>yarn.https.policyname>
<value>HTTPS_ONLYvalue>
property>
d、mapred-site.xml,加入
<property>
<name>mapreduce.jobhistory.keytabname>
<value>/usr/local/hadoop/etc/hadoop/hdfs.keytabvalue>
property>
<property>
<name>mapreduce.jobhistory.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>mapreduce.jobhistory.http.policyname>
<value>HTTPS_ONLYvalue>
property>
e、zookeeper的配置文件zoo.cfg,加入
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
jaasLoginRenew=3600000
同时在同目录下新建文件jaas.conf :
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/usr/local/hadoop/etc/hadoop/hdfs.keytab"
storeKey=true
useTicketCache=true
principal="hadoop/[email protected]";
};principal要根据不同的主机变化。
再新建文件java.env文件:
export JVMFLAGS="-Djava.security.auth.login.config=/usr/local/zookeeper/conf/jaas.conf"f、hadoop-env.sh,加入
export HADOOP_SECURE_DN_USER=hadoop
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_HOME}/sec_pids
export HADOOP_SECURE_DN_LOG_DIR=/data/hadoop/data12/hadoop-sec-logs
export JSVC_HOME=/usr/local/jsvc
这里jsvc是需要另外安装的,下面会介绍。
g、container-executor.cfg,加入
allowed.system.users=##comma separated list of system users who CAN run applications
yarn.nodemanager.local-dirs=/data/hadoop/data1/yarn/data,/data/hadoop/data2/yarn/data,/data/hadoop/data3/yarn/data,/data/hadoop/data4/yarn/data,/data/hadoop/data5/yarn/data,/data/hadoop/data6/yarn/data,/data/hadoop/data7/yarn/data,/data/hadoop/data8/yarn/data,/data/hadoop/data9/yarn/data,/data/hadoop/data10/yarn/data,/data/hadoop/data11/yarn/data,/data/hadoop/data12/yarn/data
yarn.nodemanager.linux-container-executor.group=hadoop
yarn.nodemanager.log-dirs=/data/hadoop/data1/yarn/log,/data/hadoop/data2/yarn/log,/data/hadoop/data3/yarn/log,/data/hadoop/data4/yarn/log,/data/hadoop/data5/yarn/log,/data/hadoop/data6/yarn/log,/data/hadoop/data7/yarn/log,/data/hadoop/data8/yarn/log,/data/hadoop/data9/yarn/log,/data/hadoop/data10/yarn/log,/data/hadoop/data11/yarn/log,/data/hadoop/data12/yarn/log
#banned.users=hadoop
min.user.id=1yarn-nodemanager.local-dirs和yarn.nodemanager.log-dirs要和yarn-site.xml中配置一致。min.user.id也要注意,这里设定的是可以使用提交任务用户id的最小值,用户id就是 /etc/passwd中用户对应的id。默认是1000如果不配置的话,这样如果用户id小于1000,则提交任务报错。所以这里设定成了1.原本1000是为了防止其它的超级用户使用集群的。
10、编译源码
因为container-executor(在 HADOOP_HOME/bin下)要求container-executor.cfg这个文件及其所有父目录都属于root用户,否则启动nodemanager会报错。配置文件container-executor.cfg默认的路径在HADOOP_HOME/etc/hadoop/container-executor.cfg。如果,按照默认的路径修改所有父目录都属于root,显然不可能。于是,把路径编译到/etc/container-executor.cfg中。
下载hadoop-2,7,2-src源码包解压,进入src目录下,执行
mvn package -Pdist,native -DskipTests -Dtar -Dcontainer-executor.conf.dir=/etc
执行过程时间较长。(公司有专门的编译服务器使用)
完后,进入hadoop-2.7.2/src/hadoop-dist/target下,新编译完成的代码已经生成,当然,编译源码需要搭建相应的环境,这里不做介绍。
将新生成的container-executor替换所有节点原来的container-executor,并且所有节点上均要将HADOOP_HOME/etc/hadoop下的container-executor.cfg文件复制到/etc 下,且设置权限为root:root。在bin文件夹下执行
strings container-executor | grep etc如果结果是/etc而非../etc,则表示操作成功了。另外最重要的是将bin下的container-executor
文件权限设定为root:hadoop和4750,如果权限不是4750,则启动nodemanager时会报错,报错是不能提供合理的container-executor.cfg文件。
10、启动服务
a、zookeeper启动与正常一样启动
b、journalnode启动与正常一样启动
c、namenode启动与正常一样启动
d、zkfc启动与正常一样启动
e、nodemanager启动与正常一样启动
以上所有服务均用hadoop用户启动
f、datanode启动要用root用户启动,且需要安装jsvc
jsvc安装需要下载commons-daemon-1.0.15-src.tar.gz
解压后进入 commons-daemon-1.0.15-src/src/native/unix
按步执行:
sh support/buildconf.sh
./configure 这里要在/etc/profile中配置好JAVA_HOME。
make
3步过后即可。这时在当前目录有文件jsvc,将其路径配置到前文叙述过的hadoop-env.sh中即可,配置前可试一下是否有用。使用命令在当前目录执行./jsvc -help
最后以root用户启动datanode即可。
(之后发现,其实不必须使用root启动datanode,在hdfs-site.xml中添加
11、检查
全部服务启动完毕后,namenode页面出现Security is on。
使用hadoop用户执行
kinit -k -e /usr/local/hadoop/etc/hadoop/hdfs.keytab hadoop/rm1@EXAMPLE.COM
kinit -k -e /usr/local/hadoop/etc/hadoop/hdfs.keytab hadoop/rm2@EXAMPLE.COM
kinit -k -e /usr/local/hadoop/etc/hadoop/hdfs.keytab hadoop/test-nn1@EXAMPLE.COM
kinit -k -e /usr/local/hadoop/etc/hadoop/hdfs.keytab hadoop/test-nn2@EXAMPLE.COM
kinit -k -e /usr/local/hadoop/etc/hadoop/hdfs.keytab hadoop/10-140-60-50@EXAMPLE.COM5条指令在5台机器上分别执行。这样便会在/tmp下生成krb5cc_xxx文件,前文已经交代过用处。
这时再用hadoop用户在任意节点执行 hadoop fs -ls 即可成功,否则报错,错误为无法找到tgt。之前将ticket_lifetime改为10000也是因为这里,过了24小时的话,再执行hadoop fs 又会报错,因为默认ticket时间只有24小时,需要加长。
这里ticket_lifetime和renew_lifetime查看和修改方式做一下介绍
这两个时间的确定是由
(1)Kerberos server上 /var/kerberos/krb5kdc/kdc.conf中的max_life和max_renewable_life
(2)建立Principal时自动内置了这两个时间,可用命令查看和修改
(3)/etc/krb5.conf中的ticket_lifetime和renew_lifetime
(4)kinit -l 命令后跟的时间参数
这4个中中最小的一个值决定.
使用kinit -l 命令后面加时间回车之后,提示需要输入密码,经测试,该密码并非添加principals时指定的密码,所以还未知如何修改。建议修改完配置文件中的ticket_lifetime后再添加principals,可保证时间修改。
配置文件改动即可,该完后需要重启服务
service krb5kdc restart
service kadmin restart
查看Principal相关信息使用命令
kadmin.local : getprinc {principal}
修改命令
kadmin.local : modprinc -maxlife 10000days {principal}
kadmin.local : modprinc -maxrenewlife 10000days {principal}
至此,hadoop层面集成kerberos完成,当然还远远不够,还需要后续跟进很多测试,得出结论是否可行。还有hbase、hive、hbase等服务也需要集成kerberos,任重而道远~~