手撸网络结构—ResNet
常规的卷积网络是将卷积层一层一层地堆叠起来的,每层输入都是前一层的输出。这样当网络深度达到一定的程度就会出现训练效果反而变差的现象。这种现象并不是因为出现了过拟合,一种可能的原因就是,随着深度的加深,反向传播的梯度变得越来越小,最终导致很多层的死亡。
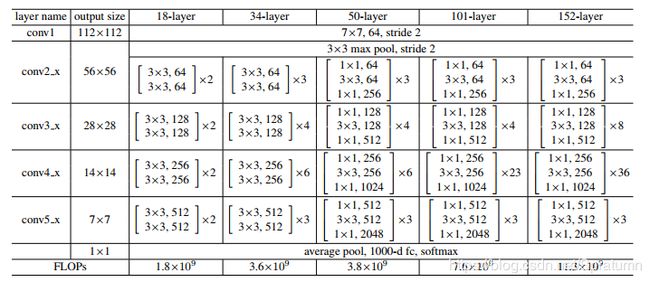
ResNet网络参数
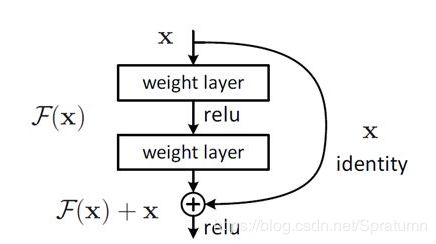
ResNet 核心就是残差学习单元,相比常规神经网络残差学习单元能够避免出现梯度消失的现象。残差网络中每层的输出为 f ( x ) + x f(x)+x f(x)+x,这样其梯度至少都为1.也就保证了不会发生梯度消失的现象。这样后续的网络的学习结果一定不会比前面的网络结果差。
ResNetResNet是一系列的网络,包括ResNet18、ResNet34、ResNet50、ResNet101、ResNet152。
主要的区别就是:
- 网络深度逐渐增多;
- 基础Block有所差异。
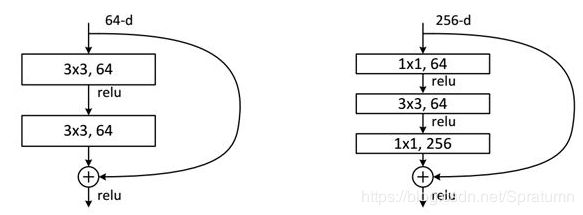
左图(BasicBlock)对应的是浅层网络,而右图(Bottleneck)对应的是深层网络。
需要注意的是:
- Block中的卷积操作不改变featuremap的尺寸,只会影响通道数;
- 在每个阶段的第一个Block可能需要对输入的尺寸进行调整然后才能进行相加操作。
在每组残差单元中,第一个单元需要进行下采样从而与单元输出的结果进行匹配。
resnet18采用的都是BasicBlock进行的叠加,前两组残差单元如下图:
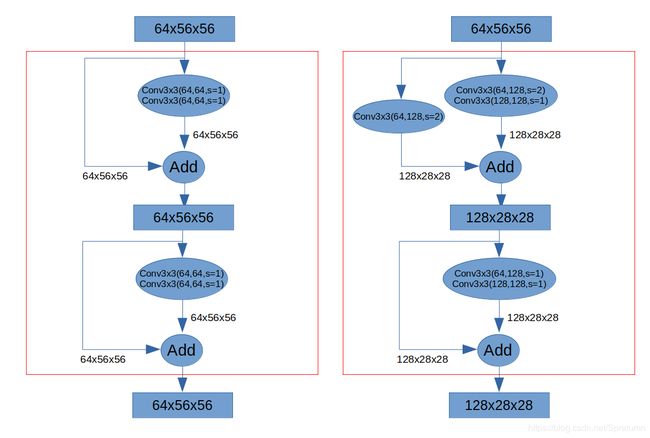
resnet50采用的都是Bottleneck进行的叠加,前两组残差单元如下图:
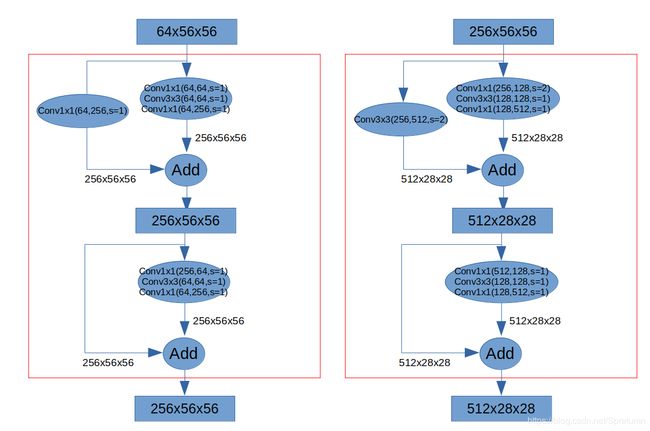
文字功力有限,直接上代码:
import torch
import torch.nn as nn
from torchsummary import summary
def conv3x3(in_planes, out_planes, padding=0, stride=1,bn=True,rl=True):
"""3x3 convolution with padding"""
layers = []
layers.append(nn.Conv2d(in_planes, out_planes,
kernel_size=3,
padding=padding,
stride=stride))
if bn:
layers.append(nn.BatchNorm2d(out_planes))
if rl:
layers.append(nn.ReLU())
return nn.Sequential(*layers)
def conv1x1(in_planes, out_planes, stride=1,bn=True,rl=True):
"""1x1 convolution without padding"""
layers = []
layers.append(nn.Conv2d(in_planes,
out_planes,
kernel_size=1,
padding=0,
stride=stride))
if bn:
layers.append(nn.BatchNorm2d(out_planes))
if rl:
layers.append(nn.ReLU())
return nn.Sequential(*layers)
class BasicBlock(nn.Module):
"""
apply in shallow net: resnet18,resnet34
conv3x3 (bn+rl)
conv3x3 (bn)
relu(bn(x+shortcut))
"""
expansion = 1
def __init__(self, inchannel, channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.downsample = downsample
self.conv1 = conv3x3(inchannel, channel, padding=1,stride=stride)
self.conv2 = conv3x3(channel, channel * self.expansion,
padding=1, bn=False, rl=False)
self.bn = nn.BatchNorm2d(channel*self.expansion)
self.relu = nn.ReLU()
def forward(self, x):
shortcut = x
x = self.conv1(x)
x = self.conv2(x)
if self.downsample is not None:
shortcut = self.downsample(shortcut)
x += shortcut
x = self.relu(self.bn(x))
return x
class Bottleneck(nn.Module):
"""
apply in deep net: : resnet50,resnet101,resnet152
conv1x1 (bn+rl)
conv3x3 (bn+rl)
conv1x1 (bn)
relu(bn(x+shortcut))
"""
expansion = 4
def __init__(self, inchannel, channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.downsample = downsample
self.conv1 = conv1x1(inchannel, channel, stride=stride)
self.conv2 = conv3x3(channel, channel, padding=1)
self.conv3 = conv1x1(channel, channel * self.expansion,
bn=False, rl=False)
self.bn = nn.BatchNorm2d(channel*self.expansion)
self.relu = nn.ReLU()
def forward(self, x):
shortcut = x
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
if self.downsample is not None:
shortcut = self.downsample(shortcut)
x += shortcut
x = self.relu(self.bn(x))
return x
class ResNet(nn.Module):
def __init__(self, block, layers, class_num=1000):
super(ResNet, self).__init__()
self.inchannel_num = 64
self.conv = nn.Conv2d(3,self.inchannel_num,kernel_size=7,stride=2,padding=3,bias=False)
self.bn = nn.BatchNorm2d(self.inchannel_num)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], change_size=False)
self.layer2 = self._make_layer(block, 128, layers[1], change_size=True)
self.layer3 = self._make_layer(block, 256, layers[2], change_size=True)
self.layer4 = self._make_layer(block, 512, layers[3], change_size=True)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, class_num)
def _make_layer(self, block, channel_num, block_num,change_size=False):
# change_size=True means the first block need change input size
if change_size:
stride = 2
else:
stride = 1
if block is BasicBlock:
if change_size:
downsample = conv3x3(self.inchannel_num, channel_num*block.expansion,
padding=1,stride=stride)
else:
downsample = None
elif block is Bottleneck:
downsample = conv1x1(self.inchannel_num, channel_num*block.expansion,
stride=stride)
else:
raise ValueError('"block" should be "BasicBlock" or "Bottleneck"')
layers = []
layers.append(block(self.inchannel_num, channel_num, stride=stride,downsample=downsample))
for _ in range(1, block_num):
layers.append(block(channel_num*block.expansion,channel_num))
self.inchannel_num = channel_num * block.expansion
return nn.Sequential(*layers)
def forward(self,x):
x = self.conv(x)
x = self.relu(self.bn(x))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# define net create function
def resnet18(class_num=1000):
return ResNet(BasicBlock, [2, 2, 2, 2],class_num)
def resnet34(class_num=1000):
return ResNet(BasicBlock, [3, 4, 6, 3],class_num)
def resnet50(class_num=1000):
return ResNet(Bottleneck, [3, 4, 6, 3],class_num)
def resnet101(class_num=1000):
return ResNet(Bottleneck, [3, 4, 23, 3],class_num)
def resnet152(class_num=1000):
return ResNet(Bottleneck, [3, 8, 36, 3],class_num)
if __name__ == '__main__':
rs = resnet18()
summary(rs,(3,224,224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,928
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,928
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,928
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,928
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,856
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,584
Conv2d-23 [-1, 128, 28, 28] 73,856
BatchNorm2d-24 [-1, 128, 28, 28] 256
ReLU-25 [-1, 128, 28, 28] 0
BatchNorm2d-26 [-1, 128, 28, 28] 256
ReLU-27 [-1, 128, 28, 28] 0
BasicBlock-28 [-1, 128, 28, 28] 0
Conv2d-29 [-1, 128, 28, 28] 147,584
BatchNorm2d-30 [-1, 128, 28, 28] 256
ReLU-31 [-1, 128, 28, 28] 0
Conv2d-32 [-1, 128, 28, 28] 147,584
BatchNorm2d-33 [-1, 128, 28, 28] 256
ReLU-34 [-1, 128, 28, 28] 0
BasicBlock-35 [-1, 128, 28, 28] 0
Conv2d-36 [-1, 256, 14, 14] 295,168
BatchNorm2d-37 [-1, 256, 14, 14] 512
ReLU-38 [-1, 256, 14, 14] 0
Conv2d-39 [-1, 256, 14, 14] 590,080
Conv2d-40 [-1, 256, 14, 14] 295,168
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BatchNorm2d-43 [-1, 256, 14, 14] 512
ReLU-44 [-1, 256, 14, 14] 0
BasicBlock-45 [-1, 256, 14, 14] 0
Conv2d-46 [-1, 256, 14, 14] 590,080
BatchNorm2d-47 [-1, 256, 14, 14] 512
ReLU-48 [-1, 256, 14, 14] 0
Conv2d-49 [-1, 256, 14, 14] 590,080
BatchNorm2d-50 [-1, 256, 14, 14] 512
ReLU-51 [-1, 256, 14, 14] 0
BasicBlock-52 [-1, 256, 14, 14] 0
Conv2d-53 [-1, 512, 7, 7] 1,180,160
BatchNorm2d-54 [-1, 512, 7, 7] 1,024
ReLU-55 [-1, 512, 7, 7] 0
Conv2d-56 [-1, 512, 7, 7] 2,359,808
Conv2d-57 [-1, 512, 7, 7] 1,180,160
BatchNorm2d-58 [-1, 512, 7, 7] 1,024
ReLU-59 [-1, 512, 7, 7] 0
BatchNorm2d-60 [-1, 512, 7, 7] 1,024
ReLU-61 [-1, 512, 7, 7] 0
BasicBlock-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,808
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
Conv2d-66 [-1, 512, 7, 7] 2,359,808
BatchNorm2d-67 [-1, 512, 7, 7] 1,024
ReLU-68 [-1, 512, 7, 7] 0
BasicBlock-69 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-70 [-1, 512, 1, 1] 0
Linear-71 [-1, 1000] 513,000
================================================================
Total params: 13,070,504
Trainable params: 13,070,504
Non-trainable params: 0
----------------------------------------------------------------