【Python】爬取的图片不对怎么办?Python爬取网页图片小结
相信很多刚开始学习Python的朋友都会对如何网上爬取图片感兴趣,既能练习python,又可以下载精美的图片壁纸。部分网站直接通过图片链接就能下载图片,但最近朋友反馈mm131上面爬取的图片竟然是个二维码。。。被反爬了,在这总结我是如何绕过反爬虫下载最终图片的。
网站页数获取
登录图片总网站比如,https://www.mm131.net/xinggan 通过翻页发现图片网站地址规律为
第一页:https://www.mm131.net/xinggan/
第二页:https://www.mm131.net/xinggan/list_6_2.html
…
第n页:https://www.mm131.net/xinggan/list_6_n.html
根据规律定义各页网站获取地址方法:
def get_page(url,page=10):
u1 = url
html_list = list()
for i in range(1,page):
if i == 1:
url = u1
else:
url = u1 + '/list_6_' + str(i) + '.html'
req = requests.get(url)
req.encoding = 'gb2312'
soup = bs4.BeautifulSoup(req.text,'html.parser')
html_num = soup.find('div',class_='main')
html_num = html_num.find_all('dd')
#print (html_num)
for each in html_num:
if "https://www.mm131.net/xinggan/" in each.a['href']:
#print (each.a['href'])
html_list.append(each.a['href'])
return html_list
以相同的方式获取各组图片的地址
下载图片
点击图片打开检查元素窗口,找到header信息
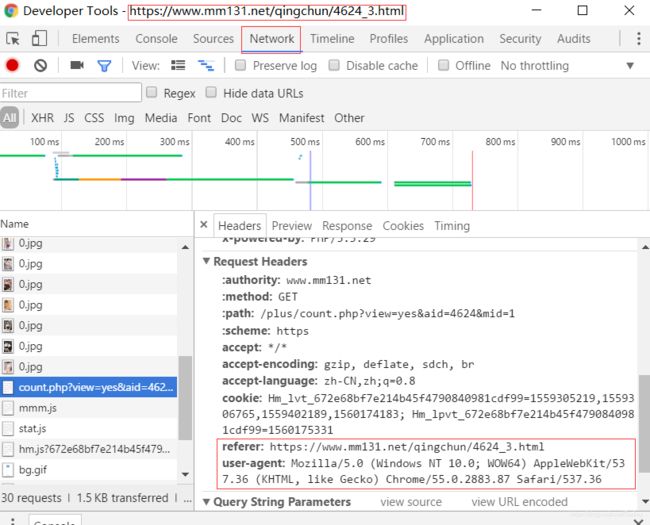
其中的referer和user-agent信息必须填写,要不下载下来的图片是网页另外的默认图片,一般这个headers信息越全越好。具体下载方法:
def save_img(folder,img_addrs):
filename = img_addrs.split('/')[-1]
print(img_addrs)
print(filename)
headers = {
'Referer':'http://www.mm131.com/qingchun/4076_5.html',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
img = requests.get(img_addrs,headers=headers)
if img ==1:
raise UnboundLocalError
with open(filename,'wb') as f:
f.write(img.content)
源码
保存图片的目录默认在当前目录以组图名称命名文件夹存储图片,爬取图片的频率太高一般也会被网站识别为爬虫,所以我每次下载图片的时候都随机等待了一段时间,代码如下
import os
import random
import time
import re
import requests
import bs4
def get_page(url,page=10):
'''
获取各组网图第一张图片的地址
返回组图url列表
'''
u1 = url
html_list = list()
for i in range(1,page):
if i == 1:
url = u1
else:
url = u1 + '/list_6_' + str(i) + '.html'
req = requests.get(url)
req.encoding = 'gb2312'
soup = bs4.BeautifulSoup(req.text,'html.parser')
html_num = soup.find('div',class_='main')
html_num = html_num.find_all('dd')
#print (html_num)
for each in html_num:
if "https://www.mm131.net/xinggan/" in each.a['href']:
#print (each.a['href'])
html_list.append(each.a['href'])
return html_list
def find_image(url):
'''
找到图片的实际下载地址
'''
html = requests.get(url)
html.encoding =" gb2312"
soup = bs4.BeautifulSoup(html.text,'html.parser')
picture_html = soup.find_all('div',class_="content-pic")
for i in picture_html:
picture_html = i.img['src']
return picture_html
def image_dir(url):
'''
根据图片url获取组图名称
'''
html = requests.get(url)
html.encoding =" gb2312"
soup = bs4.BeautifulSoup(html.text,'html.parser')
picture_html = soup.find_all('div',class_="content-pic")
#picture_html = picture_html.find_all('img')
#print (picture_html)
for i in picture_html:
picture_dir = i.img['alt']
print(picture_dir)
return picture_dir
def save_img(folder,img_addrs):
'''
下载图片到folder
'''
filename = img_addrs.split('/')[-1]
print(img_addrs)
print(filename)
headers = {
'Referer':'http://www.mm131.com/qingchun/4076_5.html',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
img = requests.get(img_addrs,headers=headers)
if img ==1:
raise UnboundLocalError
with open(filename,'wb') as f:
f.write(img.content)
#创建并进入目录
def cd(folder):
'''
进入目录,如果不存在则先创建
'''
m_dir = os.getcwd() + '\\'
folder = m_dir + folder
print(folder)
try:
os.chdir(folder)
except FileNotFoundError as reason:
print(reason)
print("本地无" + folder + "目录,创建目录")
os.mkdir(folder)
os.chdir(folder)
def down_load_mm(folder='xingganmn',pages=2,url=r'http://www.mm131.com/xinggan/'):
'''
下载图片
根据图片的标题信息创建文件夹保存图片
'''
cd(folder)
u1 = url
#获取组图url列表
page_url_list = get_page(u1,pages)
#print(page_url_list)
count = 1
for page_url in page_url_list:
ooxx_dir = home_dir + '\\' + folder
os.chdir(ooxx_dir)
#下载网图,每个图组的网图数量一般在100以内,这里缺省是下载100页,当网图不存在时进入下一组
for j in range(1,100):
print(page_url)
if j != 1:
page_url_type = '.' + page_url.split('.')[-1]
page_url = page_url.replace(page_url_type,'_' + j + page_url_type)
try:
#下载图组第一页时根据图组标题创建存放图组的目录
if j == 1:
try:
dir_name = image_dir(page_url)
dir_name = "['" + dir_name.split('(')[0] + "']"
print (dir_name)
except:
print("dir_name目录不存在")
dir_name = count
#cd(dir_name)
f_dir = os.getcwd() + '\\' + dir_name
print(f_dir)
try:
#假如之前有相同的目录说明已经下载过,这里就不重复下载了直接break
os.chdir(f_dir)
break
except FileNotFoundError as reason:
print(reason)
print("本地无" + f_dir + "目录,创建目录")
cd(f_dir)
#获取图片下载地址
img_addrs = find_image(page_url)
save_img(folder,img_addrs)
#下载图片的频率太高有可能被服务器的反爬机制检查到所以加了随机等待时间
sleeptime = random.randint(3,6)
time.sleep(sleeptime)
end_tag = 'go on' + str(count) + '_' + str(j)
print(end_tag)
except:
print (str(dir_name) + ":目录的图片数量是:" + str(j))
break
count += 1
sleeptimeb = random.randint(50,67)
time.sleep(sleeptimeb)
if __name__ == "__main__":
home_dir = os.getcwd()
os.chdir(home_dir)
down_load_mm(pages=100)