LeetCode45——从搜索算法推导到贪心
本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是LeetCode系列的第25篇文章,今天我们一起来看的是LeetCode的第45题,Jump Game II。
有同学后台留言问我说,我每次写文章的题目是怎么选的,很简单基本上是按照顺序选择Medium和Hard难度,然后会根据题目内容以及评价过滤掉一些不太靠谱或者是比较变态没有意思的题。
这些题当然会比Easy难度的要难上一点,但是并不是高不可攀的。至少如果你熟悉编程语言,然后会一点基础算法的话,就可以尝试了,我个人觉得不是很高的门槛。
好了,我们回到正题。
今天这题的题目蛮有意思,它是说给定我们一个非负整数的数组。让我们把这个数组想象成一个大富翁里的那种长条形的地图。数组当中的数字表示这个位置向前最多能前进的距离。现在我们从数组0号位置开始移动,请问至少需要移动多少步可以走到数组的结尾?

搜索
我拿到题目的第一反应就是搜索,因为感觉贪心是不可以的。我们把数组当中每个位置的数字称为前进能力,我们当下能达到的最远的位置前进能力可能很差,所以贪心能够达到最远的位置并不可行,举个例子:
[3, 1, 5, 1, 4, 2]
如果我们从0开始的时候走到3的话,由于3的前进能力很小,所以我们需要3步才能走完数组。但是如果我们一开始不走满3,而是走到2的话,我们只需要两步就可以完成。所以贪心是有反例的,我们不能简单地来贪心。而且这题的状态转移十分明显,几乎是裸的顺推。那么我们只需要搜就完事了,由于这是一个求解最优的问题,所以我们应该使用宽度优先搜索。
这个代码我想应该很好写,我们信手拈来:
class Solution:
def jump(self, nums: List[int]) -> int:
import queue
n = len(nums)
que = queue.Queue()
que.put((0, 0))
while not que.empty():
pos, step = que.get()
if pos >= n-1:
return step
for i in range(pos, min(n, pos+nums[pos] + 1)):
que.put((i, step+1))
但是显然这么交上去是一定会gg的,想想也知道,我们遍历转移状态的这个for-loop看起来就很恐怖,数组当中的状态很有可能出现重复,那么必然会出现大量的冗余。所以我们需要加上一些剪枝,由于我们使用的是宽度优先搜索,所以所有状态第一次在队列当中弹出的时候就是最优解,不可能同样的位置,我多走几步会达到更优的结果,所以我们可以放心地把之前出现过的位置全部标记起来,阻止重复遍历:
class Solution:
def jump(self, nums: List[int]) -> int:
import queue
n = len(nums)
que = queue.Queue()
que.put((0, 0))
visited = set()
while not que.empty():
pos, step = que.get()
if pos >= n-1:
return step
for i in range(pos, min(n, pos+nums[pos] + 1)):
# 如果已经入过队列了则跳过
if i in visited:
continue
que.put((i, step+1))
visited.add(i)
很遗憾,虽然我们加上了优化,但是还是会被卡掉。所以还需要继续优化,我们来分析一下会超时的原因很简单,虽然我们通过标记排除了重复进入队列的情况。但是for循环本身的计算量可能就很大,尤其在数组当中存在大量前进能力很大的位置的时候。举个例子,比如我们超时的样例:
[25000,24999,24998,24997,24996,24995,24994…]
可以看到,这个数组的前进能力都很大,我们会大量地重复遍历,这个才是计算量的根源。所以我们要避免循环重复的部分,有办法解决吗?
当然是有的,我们来分析一下问题,对于某一个位置x而言,它的前进能力是m。那么它可以达到的最远距离是x + m,这是显然的,但是很有可能从x到x+m的区间当中已经有一部分被加入队列了。所以当我们从x向x+m遍历的时候,必然会重复遍历一部分已经在队列当中的状态。那怎么解决呢?
其实很简单,我们只需要把遍历的顺序倒过来就好了。也就是说我们从x+m向x反向遍历,当我们遇到一个状态已经在队列当中的时候,就可以break了,没必要继续往下了。因为后面的状态肯定已经遍历过了。
这个时候代码如下:
class Solution:
def jump(self, nums: List[int]) -> int:
import queue
n = len(nums)
que = queue.Queue()
que.put((0, 0))
visited = set()
while not que.empty():
pos, step = que.get()
if pos >= n-1:
return step
# 倒叙遍历
for i in range(min(n-1, pos+nums[pos]), pos, -1):
# 当遇到已经遍历过的元素的时候直接break
if i in visited:
break
que.put((i, step+1))
visited.add(i)
除了上面的方法之外,我们还可以想到一种优化,我们可以使用优先队列对队列当中的元素进行排列,将潜力比较大的元素排在前面,而将潜力差的排在后面。但是你会发现如果我们把前进能力当做是潜力或者是所处的位置当做潜力都有反例,因为位置靠前的可能前进能力很差,但是前进能力比较好的,又可能位置靠后。有没有两全其美的办法呢?
当然是有的,方法也很简单,我们把两者相加,也就是位置加上它的前进能力当做这个位置的潜力。也可以认为是最远能够移动到的位置当做是潜力,这样我们每次都挑选出其中潜力最好的进行迭代,从而保证我们可以最快地找到答案。
class Solution:
def jump(self, nums: List[int]) -> int:
import queue
n = len(nums)
# 使用优先队列
que = queue.PriorityQueue()
que.put((0, 0, 0))
visited = set()
while not que.empty():
_, pos, step = que.get()
if pos >= n-1:
return step
# 倒叙遍历
for i in range(min(n-1, pos+nums[pos]), pos, -1):
if i in visited:
break
# 由于优先队列是默认元素小的排在前面,所以加上负号
que.put((-i - nums[i] ,i, step+1))
visited.add(i)
这种方法也是可以AC的,耗时比上一种方法略小。
贪心
不知道大家在写完上面这串代码之后有什么感觉,我最大的感觉不是成就感,而是觉得奇怪,就好像总觉得有哪里不太对劲,但是又不知道到底是哪里不对。
后来我想了很久,终于想明白了。不对的地方在于既然我们已经想到了这么具体的策略来优化搜索,我们为什么还要用搜索呢?因为我们没必要维护状态了,直接贪心不行吗?
在正常的bfs搜索当中,我们是一层一层地遍历状态的,每次遍历的都是搜索树上同样深度的节点。只有某一个深度的节点都遍历结束了,我们才会遍历下一个深度的节点。但是现在使用了优先队列之后,我们打破了这个限制,也就是说我们拿到的状态根本不知道是来源于哪一个深度的。而从这个题目的题意来看,潜力大的排在前面,会使得一开始潜力小的状态一直得不到迭代,沉积在队列的底部。
既然如此,我们为什么还要用队列来存储呢,直接维护最大的潜力值不就可以了?
解释一下上面这段话的意思,在当前问题当中,由于我们可以走的距离是连续的。我们可以维护一个当前步数能够移动的范围,举个例子,比如nums[0]=10,也就是说从0开始,一直到10的区间都是我们可以移动的。对于这个区间里的每一个x来说,它可以移动的范围就是[x, x+nums[x]]。所以我们可以得到x+nums[x]的集合,这里面最大的那个,就是下一步我们能够移动的范围。也就是说第二步的移动范围就是[11, max(x+nums[x])]。我们不停地迭代,当能够达到的最远位置大于或等于数组长度的时候,就表示遍历结束了。
如果还不明白,我们来看下下面这张图:
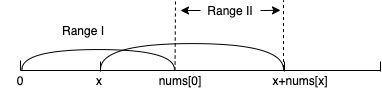
rangeI表示第一步能够移动到的范围,显然由于我们起始位置是0,所以这个范围就是[0, nums[0]]。等于rangeI当中的每一个位置都有一个潜力值,其实就是它能达到的最远的距离。对于rangeI当中的每一个位置的潜力值而言,它们显然有一个最大值,我们假设最大值的下标是x,它的潜力值就是x+nums[x]。那么我们就可以得到rangeII的范围是[nums[0]+1, x+nums[x]]。我们只需要在遍历rangeI的时候记录下这个x就可以得到rangeII的范围,我们重复以上过程迭代就行了。
这个思路理解了之后,代码就很好写了:
class Solution:
def jump(self, nums: List[int]) -> int:
n = len(nums)
start, end = 0, nums[0]
step = 1
if n == 1:
return 0
while end < n-1:
maxi, idx = 0, 0
# 维护下一个区间
for i in range(start, end+1):
if i + nums[i] > maxi:
maxi, idx = i + nums[i], i
# 下一个区间的起始范围
start, end = end+1, maxi
step += 1
return step
只有短短十来行,我们就解出了一个LeetCode当中的难题。一般来说都是我们先试着用贪心,然后发现不行,再换算法用搜索,而这道题刚好相反,我们是先想到搜索的解法,然后一点一点推导出了贪心。我想如果你能把上面思路推导的过程全部理解清楚,一定可以对这两种算法都有更深的感悟。当然,也有些大神是可以直接想到最优解的,如果做不到也没什么好遗憾的,只要我们勤于思考,多多理解,迟早有一天,这些问题对我们来说也不会是难事。
今天的文章就是这些,如果觉得有所收获,请顺手点个关注或者转发吧,你们的举手之劳对我来说很重要。
