在Spark SQL对人类数据实现K-Means聚类,并对聚类中心格式化输出
简介
本篇博文对UCI提供的 Machine-Learning-Databases 数据集进行数据分析,并通过K-Means模型实现聚类,最后格式化输出聚类中心点。
本文主要包括以下内容:
- 通过VectorAssembler来将多列数据合成一列features数据,作为聚类模型的inputCol
- K-Means模型的基础理论和参数的意义
github地址:Truedick23 - AdultBase
配置
- 语言:Scala 2.11
- Spark版本:Spark 2.3.1
聚类理论基础
- 聚类属于“无监督学习”,即训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
- 聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称作“簇”,簇所对应的概念语义需由使用者来把握和命名。
- “簇内相似度”高且“簇间相似度”低的簇类结果是最理想的情况,我们可以用“外部指标”和“内部指标”来对簇类结果进行性能度量,前者是通过“参考模型”进行比较,后者是直接考察聚类结果。
- 常用外部指标:雅卡尔指数、FM指数、Rand指数
- 常用内部指标:DB指数、Dunn指数
- 常用距离度量:闵可夫斯基距离
本篇文章中我们使用K-Means,即k均值算法来计算聚类
给定一个观测数据集(x1, x2, …, xn),每个数据为一个d维度的向量,K-Means算法的目的是最小化WCSS(within-cluster sum of squares), 即聚类内部的平方和,即最小化以下值:
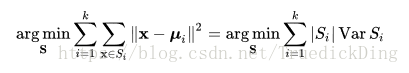
具体算法步骤如下:
- Assignment Step(赋值操作):对每一个数据分配到与其有最小的欧几里得距离的聚类中:
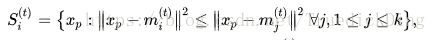
- Update Step:通过聚类中的所有点取平均来更新聚类中心点坐标:
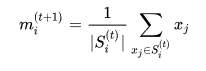
聚类模型参数设置
聚类模型在Spark 2.3.2中分为ml与mllib两种,之前博主尝试写过mllib类的K-Means模型,当时水平有限,方法比较笨,大家可以参考一下,在此我们使用ml中的KMeans来对DataFrame类的数据集计算聚类。
首先查阅一下官方文档中给出的信息:Spark 2.3.2 ScalaDoc - KMeans
可见其有6个参数:
| 参数名 | 意义 |
|---|---|
| featuresCol | 用于生成聚类的信息所在列名,其类型必须为Array |
| k | 簇的个数 |
| maxIter | 迭代的最大次数 |
| seed | 用于生成随机数的种子 |
| predictionCol | 用于输出算法所得所属簇序号的列名 |
| tol | 收敛偏差(Convergence Tolerance)的参数值 |
我们可以通过如下示例代码所示调用KMeans算法:
val kmeans = new KMeans()
.setK(8)
.setMaxIter(500)
.setSeed(1L)
.setFeaturesCol("features")
可见此段代码设置了四个参数值,我们可以用一下代码对其赋予数据集,并得到模型的参数:
val model = kmeans.fit(indexed_assembled_table)
val predictions = model.transform(indexed_assembled_table)
println(model.explainParams())
val evaluator = new ClusteringEvaluator()
val silhouette = evaluator.evaluate(predictions)
我们用以上代码将数据集indexed_assembled_table赋予KMeans模型,用explainParams可以输出参数信息,用ClusteringEvaluator可以分析聚类模型,并输出得到的Silhouette值:
featuresCol: features column name (default: features, current: features)
initMode: The initialization algorithm. Supported options: 'random' and 'k-means||'. (default: k-means||)
initSteps: The number of steps for k-means|| initialization mode. Must be > 0. (default: 2)
k: The number of clusters to create. Must be > 1. (default: 2, current: 8)
maxIter: maximum number of iterations (>= 0) (default: 20, current: 500)
predictionCol: prediction column name (default: prediction)
seed: random seed (default: -1689246527, current: 1)
tol: the convergence tolerance for iterative algorithms (>= 0) (default: 1.0E-4)
0.389470051502839
我们还得到clusterCenters,即聚类中心:
model.clusterCenters.foreach(println)
输出如下:
[37.406960769348196,7.173255991451687,12.741413524652726,5.199969470309877,10.209738971149443,3.9113112501908107,3.8009464203938332,0.7029461150969318,40.70691497481301]
[56.7424205675479,6.8239146252728595,12.242056754790202,5.122726170264371,10.039291777831675,4.166626243026922,3.839437302934756,0.7203492602473927,40.690031530439]
[46.18890761452428,6.9128236555844955,12.565650375363873,5.177110464225525,10.363260303355293,4.017925540064348,3.811858434196415,0.7099739543434962,40.74490577600735]
[21.371826371826373,7.3641277641277645,12.695986895986897,5.0175266175266175,8.841769041769043,3.111875511875512,3.7890253890253893,0.5580671580671581,40.75479115479116]
[48.94514767932489,7.261603375527425,10.656118143459915,4.881856540084388,10.09704641350211,3.6497890295358646,3.1561181434599153,0.6265822784810126,19.567510548523206]
[69.74337957124843,6.372005044136191,11.478562421185371,4.66078184110971,9.004413619167718,4.171500630517024,3.8549810844892813,0.6740226986128626,40.433165195460276]
[29.456709628506445,7.339802880970432,12.796512509476877,5.178468536770281,10.080515542077332,3.7164518574677787,3.7707354056103113,0.6694465504169826,40.711902956785444]
[28.708333333333336,7.346666666666668,11.891666666666667,5.091666666666667,9.626666666666667,3.2800000000000002,3.0083333333333337,0.655,19.125]
其他函数介绍
VectorAssembler
由于聚类的生成需要我们输入的数据集有features列提供聚合的数据,我们需要用VectorAssembler将不同行的数据合成到一个Array中,首先我们查看其文档:Spark 2.3.2 ScalaDoc - VectorAssembler
可见其需要两个参数:
| 参数 | 意义 |
|---|---|
| inputCols | StringArrayParam类数据,一般是一个由字符串组成的Array,规定了需要聚合的列名 |
| outputCol | 聚合所得结果的名称,默认为features |
示例代码如下:
val assembler = new VectorAssembler()
.setInputCols(info_elements)
.setOutputCol("features")
val indexed_assembled_table = assembler.transform(indexed_table)
效果对比如下:
+---+--------------+--------------+--------------------+---------------+-----------------+---------+--------+-------------------+
|age|workclassIndex|educationIndex|maritial_statusIndex|occupationIndex|relationshipIndex|raceIndex|sexIndex|native_countryIndex|
+---+--------------+--------------+--------------------+---------------+-----------------+---------+--------+-------------------+
| 50| 8.0| 14.0| 6.0| 13.0| 5.0| 4.0| 1.0| 41.0|
| 34| 6.0| 13.0| 6.0| 14.0| 5.0| 4.0| 1.0| 41.0|
| 44| 8.0| 15.0| 4.0| 10.0| 4.0| 4.0| 1.0| 41.0|
| 21| 8.0| 15.0| 5.0| 2.0| 3.0| 4.0| 1.0| 41.0|
| 37| 8.0| 14.0| 6.0| 8.0| 5.0| 4.0| 1.0| 41.0|
| 34| 5.0| 8.0| 4.0| 7.0| 4.0| 4.0| 1.0| 21.0|
| 18| 8.0| 4.0| 5.0| 11.0| 4.0| 4.0| 0.0| 41.0|
| 34| 5.0| 15.0| 6.0| 7.0| 5.0| 4.0| 1.0| 41.0|
+---+--------------+--------------+--------------------+---------------+-----------------+---------+--------+-------------------+
+--------------------+
| features|
+--------------------+
|[37.0,7.0,13.0,5....|
|[57.0,7.0,12.0,5....|
|[46.0,7.0,13.0,5....|
|[21.0,7.0,13.0,5....|
|[49.0,7.0,11.0,5....|
|[70.0,6.0,11.0,5....|
|[29.0,7.0,13.0,5....|
|[29.0,7.0,12.0,5....|
+--------------------+
聚类中心的格式化输出
博主之前对于此问题特别写过一篇博文,希望大家参考:
Spark中使用UDF函数、zipWithIndex配合Array数组来对Vector类的列进行分割,实现聚类中心读取为DataFrame
最后可以实现如下效果:
+----+----------------+---------+---------------+-------------+-------------+-----+----+
|age |workclass |education|maritial_status|occupation |relationship |race |sex |
+----+----------------+---------+---------------+-------------+-------------+-----+----+
|37.0|Self-emp-not-inc|Bachelors|Never-married |Sales |Not-in-family|White|Male|
|57.0|Self-emp-not-inc|Masters |Never-married |Sales |Not-in-family|White|Male|
|46.0|Self-emp-not-inc|Bachelors|Never-married |Sales |Not-in-family|White|Male|
|21.0|Self-emp-not-inc|Bachelors|Never-married |Other-service|Own-child |White|Male|
|49.0|Self-emp-not-inc|Assoc-voc|Never-married |Sales |Not-in-family|Black|Male|
|70.0|Local-gov |Assoc-voc|Never-married |Other-service|Not-in-family|White|Male|
|29.0|Self-emp-not-inc|Bachelors|Never-married |Sales |Not-in-family|White|Male|
|29.0|Self-emp-not-inc|Masters |Never-married |Sales |Own-child |Black|Male|
+----+----------------+---------+---------------+-------------+-------------+-----+----+
参考资料
- 《机器学习》(周志华 著)第九章 聚类
- Unsupervised learning - Wikipedia
- k-means clustering - Wikipedia
- Spark 2.3.2 ScalaDoc - KMeans
- Spark 2.3.2 ScalaDoc - HasFeaturesCol
- Spark 2.3.2 ScalaDoc - VectorAssembler
- Silhouette (clustering) - Wikipedia