聚类经典算法之DBSCAN算法
这一篇主要记录下对dbscan算法的学习。下一篇将说说把此算法具体运用到热点区域分析。好了,切入正题。
第一个,什么是dbscan?全称为:Density-Based Spatial Clustering of Applications with Noise(具有噪声的基于密度的聚类方法)。这是一种基于密度的聚类算法,能够除去噪音点,并且聚类的结果是划分为多个簇,簇的形状是任意的。基于密度的聚类算法都是寻找被低密度区域分离的高密度区域。
第二个,关于点的概念。基于密度的定义(以某一点为中心,在单位半径范围内所有点的集合),我们可以把点分为3种: 核心点,边界点,噪音点。
核心点: 在半径Eps内含有超多MinPts数目点,则该点就是核心点。
边界点: 在半径Eps内含有小于MinPts数目,并且是在核心点的领域内。
噪音点: 任何不适核心点或边界点的点。(那么在Eps内数目为0的点必定是噪音点,想想为什么?)
画图举例:
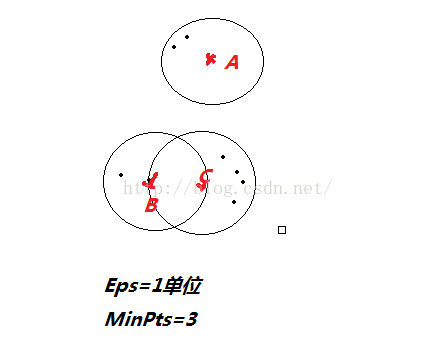
在上图中,因为A点在Eps半径内的点数目为2<3 且另外两个点也不是核心点,所以A为噪音点。C在Eps半径内的数目为4>3,所以C为核心点,而B中则为2个点,但是B在A的Eps半径范围内。
另外,什么是Eps邻域呢?给定对象半径Eps内的邻域称为该对象的Eps邻域,我们习惯用Neps(p)表示点p的Eps半径内点的集合,也就是:
Neps(p) = {q| q在数据集D中,distance(p,q)<= Eps};
第三个,关于dbscan的几个概念:
1)直接密度可达:从字面上,给人的感觉就是某点p在一个密度范围内可以找到点q。好了,我们规范理解下,就是,给定一个对象集合D,如果说p在q的邻域内,而q是一个核心对象,则称对象p从对象q出发时时直接密度可达的。
2)密度可达: 有了上面的经验,这不难理解就是经过一个或多个密度范围能够找到。。规范理解就是,如果存在一条对象链P1, P2, P3, P4 ,...Pn。其中P1 = q, Pn =q。如果对于集合D内的一点Pi存在Pi+1是从Pi关于Eps和MinPts直接密度可达的,则对象p是从对象q关于Eps和MinPts密度可达的。
3)密度相连。这是重点,简单理解就是,如果存在属于集合D的对象O,使得对象p和q都是从O关于Eps和MInPts密度可达的,那么对象p到q是关于Eps和MinPts密度相连的。而dbscan算法的目的就是要找出最大的密度相连集合。这里,直接找网上的一个例子就好了。
第四个,dbscan算法的原理。dbscan遍历每个对象,假设检查到对象P,此时判断p的Eps邻域内的对象个数是否大于等于MinPts个,如果满足,则创建以P为核心对象的簇,然后呢,我们说要尽可能的找最大的密度相连集合,那么就是要迭代查找P的Eps邻域内每个点的直接密度可达对象。。
第五个,代码如何实现? 以下用伪代码实现
1.将数据集D中的所有点标记为未访问状态,且簇Id为0.
2.
for p in D:
if p 已经访问过或者p的簇Id !=0:
continue;
else:
标记点p已经访问过;
获取p点Eps邻域内的点集合,个数为Neps(p);
if Neps(p) <=0 :
标记p的簇Id为-1(噪音点);
else if Neps(p) >= MinPts:
此时标记对象p为核心点,簇Id +=1,并设置邻域内各点的簇Id;
for q in p的Eps邻域所有未处理点的集合:
检查q的簇Id是否等于0,若不,则判断Neps(q)是否大于等于MInPts,满足则标记簇Id为p的簇Id.
第六个,关于Eps和MinPts的那点事。 通过实践表明,Eps和MinPts的取值会影响到算法的效果。那么在实际运用当中,我们又该如何取值呢? 有些人说是看经验。好吧,反正我是没那个能力。我会选择通过不断调节MinPts和Eps的范围来查看聚合的效果。还有通过绘制辅助图来查看效果。看看每次的聚合数占数据集D的比率。
第七个,关于dbscan的优点与缺点。优点的话,正如他的定义,他是基于密度的,所以它的效果不言而喻,簇的形状可以是任意的。并且能够分离出那些噪音点。当然,再好的算法也有它不足的地方,正如那句上帝为你关闭了一扇门,自然为你开启你了一扇窗。dbscan的不足还是挺明显的。如果簇的密度变化很大时,效果很差的。这个后面在运用地图查找热点区域时会说到。 还有个就是处理高维问题时,如何定义密度,是一个很棘手的问题(这个真要具体问题具体分析)。
以上就是关于dbscan的初步学习。后面会谈具体运用,以及在hadoop下面编写dbscan算法(当然有相关库,但还是要自己动手学习学习,这样才能不断进度,才会去考虑如何改进)。