此系列文章是《数据蛙三个月就业班》Adventure电商分析案例的总结,如要了解此项目,参考Adventure电商分析项目总结(2020版本)整个案例包括linux、shell、python、hive、pycharm、git、pyechart、sqoop等的使用,为了让就业班同学能够更好的学习,所以对上面大家有疑问的内容进行了总结。本篇是Adventure电商分析案例第三篇---hive初步学习
阅读目录:
- hive与mysql的区别
- hive的基本使用
- python脚本和hive的结合使用
一:hive与mysql的区别
对于没有接触过hadoop集群的同学,大家可以暂时理解hive为像mysql一样的数据库。之所以这样来理解,就是想先让大家把hive数据库操作语句中的知识点给掌握起来,然后能够完成我们的项目。大家切记,不要一开始就是装hadoop集群,找各种hive 的学习视频。下面,我带着大家来一起使用下hive 数据库,大家可以直接在服务器上来操作的。
二: hive的基本使用
- 建库和建表
create database if not exists ods;#建立ods数据库
drop table if exists ods.ods_stock_basics;#建立ods_stock_basic表
create table ods.ods_stock_basics(
ts_code varchar(10) comment 'TS代码',
symbol varchar(10) comment '股票代码',
name varchar(10) comment '股票名称',
area varchar(10) comment '所在地域',
industry varchar(10) comment '所属行业',
fullname varchar(256) comment '股票全称',
-- enname varchar(256) comment '英文全称',#"Ping An Bank Co., Ltd."会报错,不使用
market varchar(10) comment '市场类型(主板/中小板/创业板)',
exchanges varchar(10) comment '交易所代码',
curr_type varchar(10) comment '交易货币',
list_status varchar(10) comment '上市状态:L上市 D退市 P暂停上市',
list_date date comment '上市日期',
is_hs varchar(10) comment '是否沪深港通标的,N否 H沪股通 S深股通' )
COMMENT '股票基础信息数据'
ROW FORMAT DELIMITED
fields terminated by ',' #这句和上面一句一起理解为:字段之间以逗号为分隔
stored as textfile location '/home/mike/ods';# 数据的文件格式是textfile
#关于这个路径/home/mike/ods/ 这个是hadfs的路径,大家不用去想,也可以不用写
- 给表中传入数据
首先找到要传入到ods_stock_basic这个表中的数据,这个我们在linux服务器上已经上传了,可以微信我,提供服务器给大家来使用
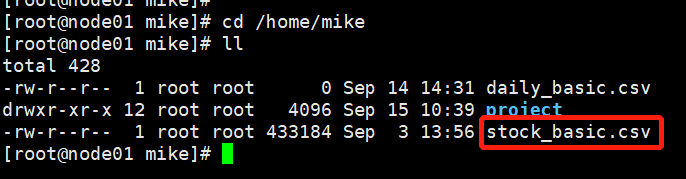
我们再来看下文件内容,命令是more stock_baisc.csv

在咱们的服务器上直接输入 hive命令,我们就可以直接来操作hive数据库了
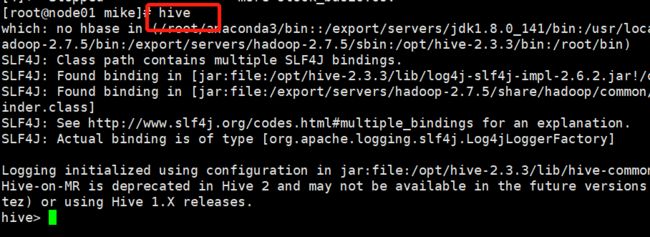
紧接着我们把数据传入到 ods_stock_basic这个表中,命令如下:
load data local inpath '/home/mike/stock_basic.csv' into table ods.ods_stock_basic 操作完 hive这个命令后直接复制粘贴上面这段话, enter换行来运行下就好(由于数据已经加载进去了,这里就不做演示了)
最后我们来查找下看看有没有数据

通过上面的操作是不是感觉和mysql基本一样呢
三:python脚本和hive的结合使用
由于咱们课程中涉及到每日股票的交易数据进入hive中,如果每天导入一次的话,就太麻烦了,应该写成脚本的形式,然后设置成定时任务来执行。
下面给大家提前看下脚本:
def add_sql_daily_basic(yesterday_date):
# 从mysql中取出昨日的交易数据
query_sql = "select * from stock_daily_basic where trade_date='{yesterday_date}'".format(yesterday_date=yesterday_date)
daily_basic_df = pd.read_sql_query(query_sql, con=datafrog)
# 数据转成csv 格式
daily_basic_df.to_csv('/home/mike/daily_basic.csv', header=False, index=False)
# 加载数据到mysql中
load = str("load data local inpath '/home/mike/daily_basic.csv' into table ods.ods_daily_basic")
load_sql = str('hive -e' + '"' + load + '"')
os.system(load_sql)
最后给大家准备了一份hive 的练习题目。

hive练习题目,大家可以在咱们的服务器中找到这份数据,然后进行练习操作哈