Python基础语法全体系 | 流程控制(分支结构与循环结构)
 《Python基础语法全体系》系列博文第四篇,本篇博文将详细深入地讲解Python的流程控制,if分支结构、断言、循环与控制循环结构。本文整理自疯狂python编程。
《Python基础语法全体系》系列博文第四篇,本篇博文将详细深入地讲解Python的流程控制,if分支结构、断言、循环与控制循环结构。本文整理自疯狂python编程。
文章目录
- if 分支结构
- 基本语法
- pass语句
- 断言
- 循环结构
- while循环
- for-in 循环
- 循环使用else
- for表达式(列表生成式、生成器)
- 常用工具函数
- 控制循环结构
- 使用break结束循环
- 使用continue控制循环
- 使用return结束循环
Python提供了现代编程语言都支持的两种基本流程控制结构:分支结构和循环结构。Python使用if语句提供分支支持,提供while、for-in循环,也提供了break和continue来控制程序的循环结构。
在任何编程语言中最常见的就是顺序结构,顺序结构就是程序从上到下一行行地执行,中间没有任何判断加跳转。如果Python程序的多行代码之间没有任何流程控制,则程序总是从上向下依次执行,排在前面的代码先执行,排在后面的代码后执行。
if 分支结构
基本语法
if 分支使用布尔表达式或布尔值作为分支条件来进行分支控制。Python的 if 分支即可以作为语句使用,也可以作为表达式使用。if 表达式相当于其他语言中三目运算符,我们在这篇文章中讲过,故不再赘述。《Python基础语法全体系 | 基本语法元素、基本数据类型》
Python发if语句有如下三种形式:
# 第一种形式
if expression:
statements ...
# 第二种形式
if expression:
statements ...
else:
statements ...
# 第三种形式
if expression:
statements ...
elif expression:
statements ...
... // 可以有零条或多条elif
else:
statements ...
Python的代码块是通过缩进来标记的,具有相同缩进的多行代码属于同一个代码块,注意 if 条件后的条件执行体一定要缩进,只有缩进后的代码才能算条件执行体。另外位于同一个代码块中的所有语句必须保持相同的缩进,既不能多,也不能少。
if、else、elif 后的条件执行体必须使用相同缩进的代码块,将这个代码块整体作为条件执行体。当 if 后有多条语句作为条件执行体时,如果忘记了缩进某一行代码,则会引起语法错误。
从Python解释器的角度来看,Python冒号精确表示代码块的开始点——这个功能不仅在条件执行体中如此,之后要介绍的循环体、方法体、类体中也都全部遵守该规则。
if 条件可以是任意类型,当下面的值最为bool表达式时,会被解释器当做False处理。
False、None、0、""、()、[]、{}
除了False本身,各种代表“空”的None、空字符串、空元祖、空列表、空字典都会被当做False处理。
# 定义空字符串
s = ""
if s :
print('s不是空字符串')
else:
print('s是空字符串')
# 定义空列表
my_list = []
if my_list:
print('my_list不是空列表')
else:
print('my_list是空列表')
# 定义空字典
my_dict = {}
if my_dict:
print('my_dict不是空字典')
else:
print('my_dict是空字典')
pass语句
很多语言都提供了“空语句”支持,Python中pass语句就是空语句。
有时候程序需要占位但又不希望这条语句做任何事情,此时就可以使用pass语句来实现。
s = input("请输入一个整数: ")
s = int(s)
if s > 5:
print("大于5")
elif s < 5:
# 空语句,相当于占位符
pass
else:
print("等于5")
例如上面的程序,对于s小于5的情形,程序暂不想处理(或者不知道如何处理),此时程序就需要通过空语句来占一个位。
断言
断言语句和if分支语句有点类似,它用于对一个bool表达式进行断言,如果该bool表达式为True,该程序可以继续向下执行;否则会引发AssertionError错误。
s_age = input("请输入您的年龄:")
age = int(s_age)
assert 20 < age < 80
print("您输入的年龄在20和80之间")
上述程序断言了这条语句20 < age < 80,即用户输入的s_age必须位于20到80之间,如果不在,那么将会触发AssertionError错误。
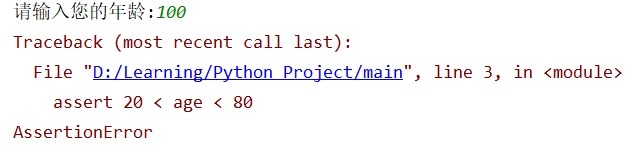
实际上断言也相当于一种特殊的分支。assert断言的执行逻辑是:
if 条件为False:
程序引发AssertionError错误
循环结构
循环语句可以在满足循环条件的情况下,反复执行某一段代码,这段被重复执行的代码被称为循环体。当反复执行这个循环体时,需要在合适的时候使得循环条件为假,从而结束循环:否则循环将一直执行下去,形成死循环。
循环语句可能包含如下4 个部分:
① 初始化语句:一条或多条语句,用于完成一些初始化工作。初始化语句在循环开始之前执行。
② 循环条件:这是一个布尔表达式,这个表达式能决定是否执行循环体。
③ 循环体:这个部分是循环的主体,如果循环条件允许,这个代码块将被重复执行。
④ 迭代语句:这个部分在一次执行循环体结束后,对循环条件求值之前执行,通常用于控制循环条件中的变量,使得循环在合适的时候结束。
while循环
while 循环的语法格式如下:
[init statements] # 初始化
while test_expression : # 循环条件
body_statements # 循环体
[iteration statements] # 迭代语句
在使用while循环时,一定要保证循环条件有变成假的时候;否则这个循环将成为一个死循环,永远无法结束这个循环。
由于列表和元组的元素都是有索引的,因此程序可以通过while循环、列表或元组的索引来遍历列表和元组中的所有元素。
a_tuple = ('blog', 'zyzmzm', 'jimmy')
i = 0
# 只有i小于len(a_list),继续执行循环体
while i < len(a_tuple):
print(a_tuple[i]) # 根据i来访问元组的元素
i += 1
运行上述程序,结果如下:
blog
zyzmzm
jimmy
按照上面的方法,while循环也可以用于遍历列表。接下来我们实现一个小程序,实现对一个整数列表的元素进行分类,能整除3的放入一个列表中;除以3余1的放入另一个列表中;除以3余2的放入第三个列表中。
src_list = [12, 45, 34, 13, 100, 24, 56, 74, 109]
a_list = [] # 定义保存整除3的元素
b_list = [] # 定义保存除以3余1的元素
c_list = [] # 定义保存除以3余2的元素
# 只要src_list还有元素,继续执行循环体
while len(src_list) > 0:
# 弹出src_list最后一个元素
ele = src_list.pop()
# 如果ele % 2不等于0
if ele % 3 == 0 :
a_list.append(ele) # 添加元素
elif ele % 3 == 1:
b_list.append(ele) # 添加元素
else:
c_list.append(ele) # 添加元素
print("整除3:", a_list) # 整除3: [24, 45, 12]
print("除以3余1:",b_list) # 除以3余1: [109, 100, 13, 34]
print("除以3余2:",c_list) # 除以3余2: [74, 56]
for-in 循环
for-in循环专门用于遍历范围、列表、元素和字典等可迭代对象包含的元素。for-in循环的语法格式如下:
for 变量 in 字符串|范围|集合 :
statements
两点说明:
① for-in 循环中的变量的值受for-in循环控制,该变量将会在每次循环开始时自动被赋值,因此程序不应该在循环中对该变量赋值。
② for-in 循环可用于遍历任何可迭代对象。所谓可迭代对象,就是指该对象中包含一个_iter_方法,且该方法的返回值对象具有next()方法。
for-in循环可用于遍历范围。例如,如下程序使用for-in循环来计算指定整数的阶乘。
s_max = input("请输入您想计算的阶乘:")
mx = int(s_max)
result = 1
# 使用for-in循环遍历范围
for num in range(1, mx + 1):
result *= num
print(result)
在使用for-in循环遍历列表和元组时,列表或元组有几个元素,for-in循环的循环体就执行几次,针对每个元素执行一次,循环计数器会依次被赋值为元素的值。
a_tuple = ('zyzmzm', 'blog', 'jimmy')
for ele in a_tuple:
print('当前元素是:', ele)
当然,我们也可以按照上面的方法来遍历列表。例如下面程序要计算列表中所有数值元素的总和、平均值。
src_list = [12, 45, 3.4, 13, 'a', 4, 56, 'zyzmzm', 109.5]
my_sum = 0
my_count = 0
for ele in src_list:
# 如果该元素是整数或浮点数
if isinstance(ele, int) or isinstance(ele, float):
print(ele, end=" ")
# 累加该元素
my_sum += ele
# 数值元素的个数加1
my_count += 1
print("\n"+'总和:', my_sum)
print('平均数:', my_sum / my_count)
# 运行结果如下:
12 45 3.4 13 4 56 109.5
总和: 242.9
平均数: 34.7
上面程序使用了Python的isinstance()函数,该函数用于判断某个变量是否为指定类型的实例,其中前一个参数是要判断的变量,后一个参数是类型。
for-in循环可以根据索引来遍历列表或元组:只要让循环计数器遍历0到列表长度的区间,即可通过该循环计数器来访问列表元素。
a_list = [330, 1.4, 50, 'blog', -3.5]
# 遍历0到len(a_list)的范围
for i in range(0, len(a_list)) :
# 根据索引访问列表元素
print("第%d个元素是 %s" % (i , a_list[i]))
# 运行结果
第0个元素是 330
第1个元素是 1.4
第2个元素是 50
第3个元素是 blog
第4个元素是 -3.5
使用 for-in 循环遍历字典其实也是通过遍历普通列表来实现的。前面介绍字典时已经提到,字典包含了如下三个方法:
- items():返回字典中所有key-value对的列表。
- keys():返回字典中所有key的列表。
- values():返回字典中所有value的列表。
因此,如果要遍历字典,则可以先调用字典的上面三个方法之一来获取字典的所有key-value对、所有key、所有value,再进行遍历。
my_dict = {'语文': 89, '数学': 92, '英语': 80}
# 通过items()方法遍历所有key-value对
# 由于items方法返回的列表元素是key-value对,因此要声明两个变量
for key, value in my_dict.items():
print('key:', key)
print('value:', value)
print('-------------')
# 通过keys()方法遍历所有key
for key in my_dict.keys():
print('key:', key)
# 在通过key获取value
print('value:', my_dict[key])
print('-------------')
# 通过values()方法遍历所有value
for value in my_dict.values():
print('value:', value)
假如要实现一个程序,用于统计列表中各元素出现的次数。由于我们并不清楚列表中包含多少个元素,因此考虑定义一个字典,以列表的元素为key,该元素出现的次数为value,程序如下:
src_list = [12, 45, 3.4, 12, 'zyzmzm', 45, 3.4, 'zyzmzm', 45, 3.4]
statistics = {}
for ele in src_list:
# 如果字典中包含ele代表的key
if ele in statistics:
# 将ele元素代表出现次数加1
statistics[ele] += 1
# 如果字典中不包含ele代表的key,说明该元素还未出现国
else:
# 将ele元素代表出现次数设为1
statistics[ele] = 1
# 遍历dict,打印出各元素的出现次数
for ele, count in statistics.items():
print("%s的出现次数为:%d" % (ele, count))
# 运行结果
12 的出现次数为:2
45 的出现次数为:3
3.4 的出现次数为:3
zyzmzm 的出现次数为:2
循环使用else
python的循环都可以定义else代码块,当循环条件为False时,程序会执行else代码块。
count_i = 0
print('count_i小于5: ', end="")
while count_i < 5:
print(count_i, end=" ")
count_i += 1
else:
print('\ncount_i大于或等于5:', count_i)
# 运行结果
count_i小于5: 0 1 2 3 4
count_i大于或等于5: 5
循环的else代码块时Python的一个很特殊的语法,else代码块的作用主要是生成更优雅的Python代码。
for循环同样可以使用else代码块,当for循环把区间、元组或列表的所有元素遍历一次之后,for循环会执行else代码块,在else代码块中,循环计数器的值依然等于最后一个元素的值。
a_list = [330, 1.4, 50, 'blog', -3.5]
print('元素: ',end="")
for ele in a_list:
print(ele, end=" ")
else:
# 访问循环计数器的值,依然等于最后一个元素的值
print('\nelse块:', ele)
# 运行结果
元素: 330 1.4 50 blog -3.5
else块: -3.5
for表达式(列表生成式、生成器)
for表达式用于其他区间、元组、列表等可迭代对象创建的列表。for表达式的语法格式:
[表达式 for 循环计数器 in 可迭代对象]
从上面的语法格式可以看出,for表达式与普通for循环的区别有两点。
- 在for关键字之前定义一个表达式,该表达式通常会包含循环计数器。
- for表达式没有循环体,因此不需要冒号
for 表达式最终返回的是列表,因此for表达式也被称为列表推导式。
a_range = range(10)
# 对a_range执行for表达式
a_list = [x * x for x in a_range]
# a_list集合包含10个元素
print(a_list) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
还可以在for表达式的后面添加if条件,这样for表达式将只迭代那些符合条件的元素。
b_list = [x * x for x in a_range if x % 2 == 0]
# a_list集合包含5个元素
print(b_list) # [0, 4, 16, 36, 64]
如果将for表达式的方括号改为圆括号,for表达式将不再生成列表,而是生成一个生成器(generator),该生成器同样可使用for循环迭代。
对于使用圆括号的for表达式,它最终返回的是生成器,因此这种for表达式也被称为生成器推导式。
# 使用for表达式创建生成器
c_generator = (x * x for x in a_range if x % 2 == 0)
# 使用for循环迭代生成器
for i in c_generator:
print(i, end='\t')
print() # 0 4 16 36 64
在前面看到的for表达式都只有一个循环,实际上for表达式可使用多个循环,就像嵌套循环一样。
d_list = [(x, y) for x in range(5) for y in range(4)]
# d_list列表包含20个元素
print(d_list)
# 运行结果
[(0, 0), (0, 1), (0, 2), (0, 3),
(1, 0), (1, 1), (1, 2), (1, 3),
(2, 0), (2, 1), (2, 2), (2, 3),
(3, 0), (3, 1), (3, 2), (3, 3),
(4, 0), (4, 1), (4, 2), (4, 3)]
上面的for表达式相当于如下嵌套循环:
dd_list = []
for x in range(5):
for y in range(4):
dd_list.append((x, y))
print(dd_list)
当然,也支持类似于三层嵌套的for表达式。
e_list = [[x, y, z] for x in range(5) for y in range(4) for z in range(6)]
# 3_list列表包含120个元素
print(e_list)
对于包含多个循环的for表达式,同样可指定if条件。
src_a = [30, 12, 66, 34, 39, 78, 36, 57, 121]
src_b = [3, 5, 7, 11]
# 只要y能整除x,就将它们配对在一起
result = [(x, y) for x in src_b for y in src_a if y % x == 0]
print(result)
# 运行结果
[(3, 30), (3, 12), (3, 66), (3, 39),
(3, 78), (3, 36), (3, 57), (5, 30),
(11, 66), (11, 121)]
常用工具函数
使用zip()函数可以把两个列表“压缩”成一个zip对象(可迭代对象),这样就可以使用一个循环并行遍历两个列表。
blogs = ['ZYZMZM', 'C++', 'Python']
fans = [1500, 690, 890]
# 使用zip()函数压缩两个列表,从而实现并行遍历
for book, price in zip(blogs, fans):
print("%s的粉丝: %5.2f" % (book, price))
# 运行结果
ZYZMZM的粉丝: 1500.00
C++的粉丝: 690.00
Python的粉丝: 890.00
有些时候,程序需要进行反向遍历,此时可通过reversed()函数,该函数可接收各种序列(元组、列表、区间等)参数,然后返回一个“反序排列”的迭代器,该函数对参数本身不会产生任何影响。
blogs = ['ZYZMZM', 'C++', 'Python']
reverse_blogs = reversed(blogs)
for x in reverse_blogs:
print(x, end=" ") # Python C++ ZYZMZM
之前有提到,str 其实也是序列因此可以通过该函数实现在不影响字符串本身的前提下,对字符串进行反序遍历。
str = "ZYZMZM-BLOG"
for x in reversed(str):
print(x, end="") # GOLB-MZMZYZ
另一个常用的工具函数是sorted(),sorted()函数也不会改变所传入的可迭代对象,该函数只是返回一个新的、排序好的列表。
在使用sorted()函数时,还可传入一个reverse参数,如果将该参数设置为True,则表示反向排序。
nums = [20, 30, -1.2, 3.5, 90, 3.6]
print(sorted(nums, reverse = True))
# [90, 30, 20, 3.6, 3.5, -1.2]
在使用sorted()函数时,还可传入一个key参数,该参数可指定一个函数来生成排序的关键值,比如希望根据字符串长度排序,则可为key传入len函数。
strs = ['blog', 'ZYZMZM', 'python', 'c++', 'go', 'lua']
print(sorted(strs, key = len))
# ['go', 'c++', 'lua', 'blog', 'ZYZMZM', 'python']
控制循环结构
Python语言没有提供goto语句来控制程序的跳转,只提供了continue和break来控制循环结构。除此之外,使用return方法可以结束整个方法,当然也就结束了一次循环。
使用break结束循环
我们使用break来强行终止循环,而不是等到循环条件为False时才退出循环。break用于完全结束一个循环,跳出循环体,执行之后的代码。
# 一个简单的for循环
for i in range(0, 10) :
print("i的值是: ", i)
if i == 2 :
# 执行该语句时将结束循环
break
对于带else块的for循环,如果使用break强行中止循环,程序将不会执行else块,即若循环正常结束,则执行else块中的语句。
# 一个简单的for循环
for i in range(0, 10) :
print("i的值是: ", i)
if i == 2 :
# 执行该语句时将结束循环
break
else:
print('else块: ', i)
# 运行结果
i的值是: 0
i的值是: 1
i的值是: 2
为了使用break语句跳出嵌套循环中的外层循环,可先定义bool类型的变量来标志是否需要跳出外层循环,然后在内层循环、外层循环中分别使用两条break语句来实现。
exit_flag = False
# 外层循环
for i in range(0, 5) :
# 内层循环
for j in range(0, 3 ) :
print("i的值为: %d, j的值为: %d" % (i, j))
if j == 1 :
exit_flag = True
# 跳出里层循环
break
# 如果exit_flag为True,跳出外层循环
if exit_flag :
break
使用continue控制循环
之前讲解的break是结束中止整个循环,跳出循环体;而continue只是忽略当次循环的剩下语句,接着开始下一次循环,并不会中止循环。
# 一个简单的for循环
for i in range(0, 3 ) :
print("i的值是: ", i)
if i == 1 :
# 忽略本次循环的剩下语句
continue
print("continue后的输出语句")
# 运行结果
i的值是: 0
continue后的输出语句
i的值是: 1
i的值是: 2
continue后的输出语句
使用return结束循环
return 用于从包围它的最直接方法、函数或匿名函数返回。当函数或方法执行到一条return语句时,这个函数或方法将被结束,有关函数我们会在之后的博文中详细讲解。
Python程序中的大部分循环都被放在函数或方法中执行,一旦在循环体内执行到一条return语句时,return语句就会结束该函数或方法,循环自然也随之结束。
def test():
for i in range(10):
for j in range(10):
print("i的值是: %d, j的值是: %d" % (i, j))
if j == 1:
return
print("return后的输出语句")
test()
# 运行结果
i的值是: 0, j的值是: 0
return后的输出语句
i的值是: 0, j的值是: 1