R语言 使用regsubsets等函数进行回归模型的选择
两模型比较:
anova()函数:可以比较两个嵌套模型的拟合优度。
fit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
fit2<-lm(Murder~Population+Illiteracy,data=states)
anova(fit2,fit1)

结论:p=0.994,不显著,不需要将Income和Frost添加到线性模型中。
AIC()函数:考虑了模型的统计拟合度遗迹用来拟合的参数数目。
fit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
fit2<-lm(Murder~Population+Illiteracy,data=states)
AIC(fit2,fit1)
结论:AIC越小越优先选择,这个结果说明模型用较少的参数获得了足够的拟合度。
多模型比较:
使用stepAIC()函数作逐步回归:
library(MASS)
fit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
stepAIC(fit,direction = "backward")
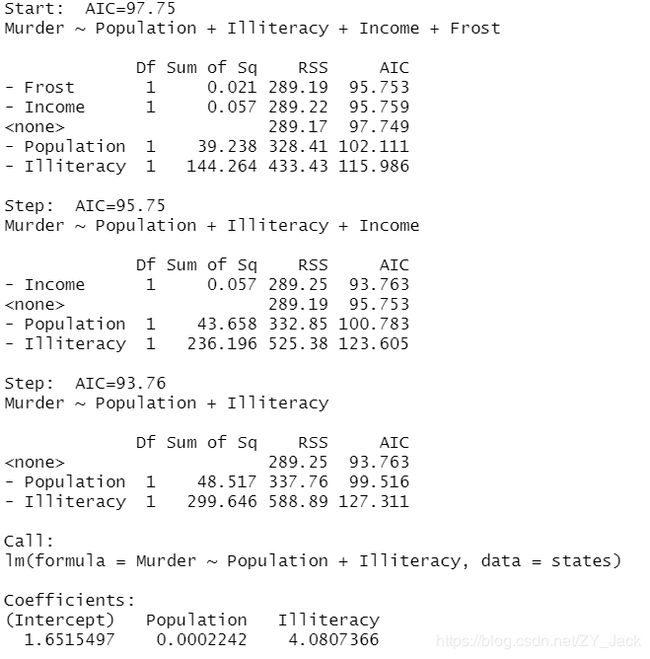
例子中采用该向后逐步回归,从模型包含所有预测变量开始,一次删除一个变量直到会降低模型质量为止。
具体表现为:
第一步删除Frost,AIC: 97.75 --> 95.75
第二步删除Income,AIC: 95.75 --> 93.76
第三步删除之后AIC不下降,因此终止选择过程。
这种方法虽然或许可以找到更好一些的模型,但是并不能保证找到最佳模型,因此有了全子集回归法。
使用regsubsets()函数作全子集回归:
library(leaps)
leaps<-regsubsets(Murder~Population+Illiteracy+Income+Frost,data=states,nbest=4)
plot(leaps,scale="adjr2")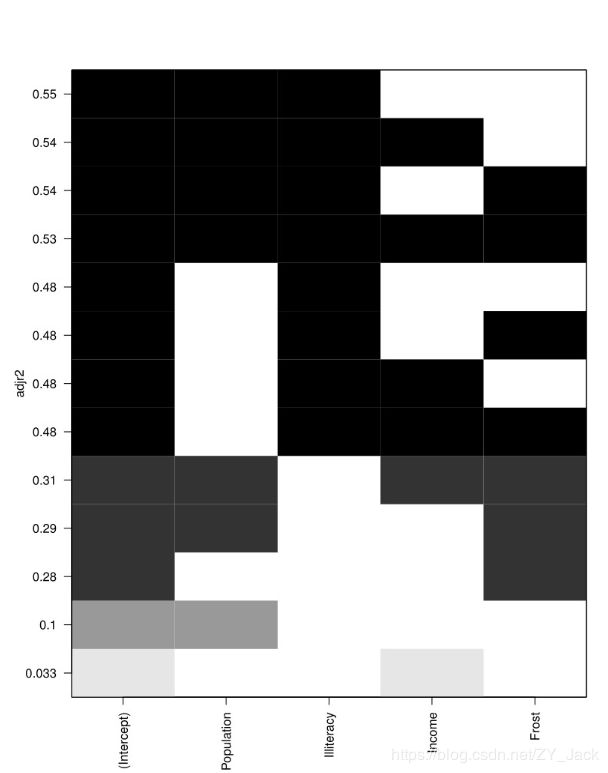
(R平方含义是预测变量解释响应变量的程度,但是会随着变量数目的增加而增加,所以这里使用R调整平方来展示更加真实的R平方估计)
可以从上图中看出,当变量只有Population和Illiteracy时,R调整平方是最大的,因此双预测变量模型是最佳的。
(对nbset参数的解释:若nbest=2,先展示两个最佳的单预测变量模型,然后展示两个最佳的双预测变量模型,以此类推,直到包含所有的预测变量。)
总的来说,regsubsets函数代表的全子集回归会优于逐步回归,但是对变量很多的时候会比较乏力。但是这几种方法只是辅助,对主题的深入理解才能最终找到最佳模型。