论文链接:https://arxiv.org/pdf/1705.04304.pdf
attentional,基于RNN的encoder-decoder模型,用于短句输入和输出的摘要生成表现很好。但是长一点的文档和总结,用这些模型往往会生成重复和不连贯的短语。本文介绍一个结合了intra-attention机制的神将网络模型,可以在输入之上,分离的生成输出,使用新的训练方法:结合标准的有监督的单词预测和强化学习(reinforcement learning)。
当模型只使用有监督学习来训练经常会“exposure bias”,假设训练时每一步都有ground truth。当将标准的单词预测和global序列的预测(用RL训练的)来生成summary可以更加可读。
Models trained only with supervised learning often exhibit "exposure bias"---they assume ground truth is provided at each step during training. However, when standard word prediction is combined with the global sequence prediction training of RL the resulting summaries become more readable.
Introduction:
文本摘要是从自然语言中自动生成自然语言摘要的过程,从输入文档中获取重要信息。主要有两种summarization algorithms。1)抽取摘要系统通过复制部分输入来形成摘要。2)抽象概括的系统产生新的短语,可能改写或用不在原文中的词。
过去的attentional encoder-decoder模型在做摘要生成时效果可以得到很高的ROUGE分数,但是只能输入短句,生成短的summaries。使用attentional encoder-decoder模型,输入长句的问题在于会生成很多重复的短语。
But their analysis illustrates a key problem with attentional encoder-decoder models: they often unnatural summaries consisting of repeated phrases.
本文的模型,一个端对端的模型,使用a key attention mechanism,a new learning objective来解决重复短语的问题。1)在encoder中使用intra-temporal attention,可以记录之前的每个input token的attention weights,decoder中使用a sequential intra-attention模型。2)使用新的目标函数,combining the maximum-likelihood cross-entropy loss used in prior work with rewards from policy gradient reinforcement learning to reduce exposure bias.
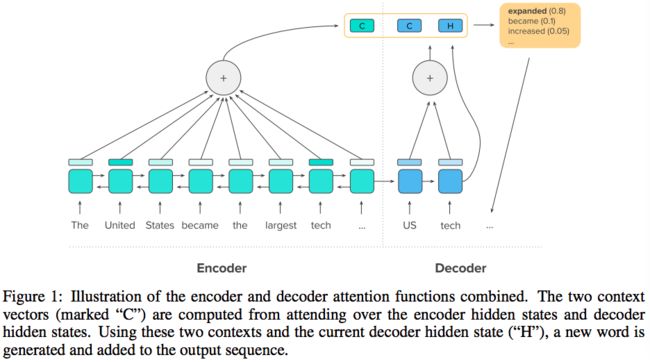
Neural intra-attention model:
输入是x={x1, x2, ..., xn},输出是y={y1, y2, ..., yn}, || 代表向量级联操作。本文的模型通过双向LSTM encoder读取输入,single LSTM作为decoder
初始化decoder的hidden state为:
2.1 Intra-temporal attention on input sequence
可以减少重复,eti为attention分数
f是任意一个可以返回标量eti的函数。一些attention模型使用两个向量间的dot-product,本文选择使用a bilinear function:

惩罚过去已经获得高attention score的。Finally we compute the normalized scores scores aeti across the inputs and use these weights to obtain the input context vector cet.

2.2 Intra-decoder attention
计算新的decoder context vector
对于t>1,使用如下的等式:
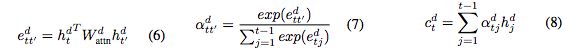
2.3 Token generation and pointer
使用switch function来确定每一步是使用token generation或者pointer。定义ut为二元值,如果pointer机制在输出yt中使用了,就为1,否则为0.
pointer机制使用temporal attention weights作为从输入拷贝xi的概率。
使用copy机制计算decoding阶段t的概率:
得到最终的输出yt的概率分布:
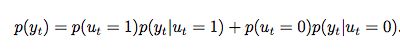
3. hybrid learning objective
3.1 supervised learning with teacher forcing
decoder RNN:使用teacher forcing‘’ algorithm,最小化 maximum-likelihood loss。
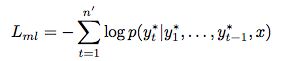
3.2 Policy learning
强化学习,self-critical policy gradient training algorithm

3.3 Mixed training objective function