干货来了!菜鸟入门最经典的机器学习项目,面试必考!

今天小编带领大家完整的走完一个简单机器学习小的实战项目,这个项目是Kaggle上的经典项目《泰坦尼克号之灾》,也是面试经常考的项目。大家对于泰坦尼克号一定不会陌生,但是不知道大家想过没有,泰坦尼克号上生还的都是哪些人,他们都有什么样的特征呢?
今天小编将从以下的几个点进行分析:
对于数据的认知
特征工程
进行模型的构建
1
对于数据认知
首先为什么要讲数据的认知,只有对数据进行充分的了解,你才能从大量的冰冷的数据中发现潜在的规律;只有对数据进行充分的认识,你才能从数据中提取有价值的信息。没有对于数据的了解,其他的都是空谈。那么我们首先来看一下,我们所要处理的数据吧。
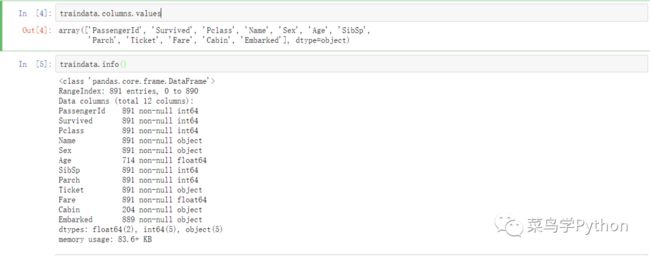
数据一共有12个维度,也就是12个特征,分别对应如下:
PassengerId => 乘客的ID
Survived=> 乘客是否存活
Pclass => 乘客的等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 船票的价格
Cabin => 船舱号
Embarked => 登船港口
其中Survived变量是我们需要求的变量。数据中像是Sex、Embarked属于类目型数据,数值类型的数据有:Age,Fare,SibSphe Parch。
2
从数据分布中获取信息
从数据的分布信息中,我们可以得到一些统计信息,帮助我们更快的对数据集有一个整体的理解。
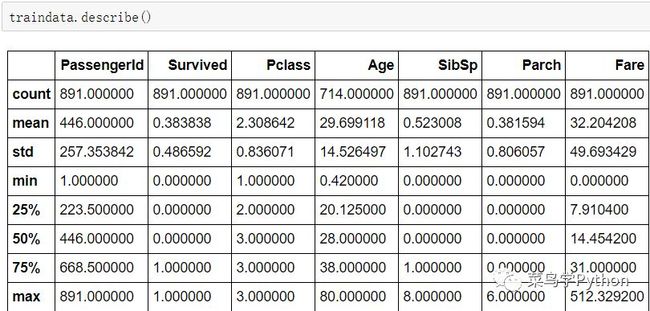
从上面的表格中,我们可以知道训练样本集中包含样本891例,891例中最终幸存的概率是38.4%左右;,二等舱和三等舱的人要多于一等舱的人;乘客的平均年龄为29.7岁左右;有超过75%的人没有与父母或者是子女一起登上泰坦尼克号。

乘客中男性的比例为577/891=65%;客舱(cabin)中存在重复项,也就是说存在乘客共用一个客舱;从‘S’口登船的乘客比例是最高的。
3
特征关联分析
接下来,我们将分析“Survived”与其他特征属性之间可能存在的关联,帮助我们进一步对数据进行分析。
1).首先我们来看一下乘客的等级、性别、Parch和SibSp与生存率的关系

从Pclass与生存率的关系来看,乘客等级越高,存活的几率也是越大的,所以有钱有地位到什么时候都是很重要的。从性别来看,女性的存活几率达到了74%,明显的高于男性,看来国外对于女士优先做的不错。而性别特征也是一个很重要的特征。从Parch和SibSp中我们无法直接获取到相关的内在联系,所以我们可以将这两个特征提取成一个特征。
2).接下来我们要针对于年龄这个特征来进行分析,看看“尊老爱幼”这个设想是否能够在这个事件中成立。
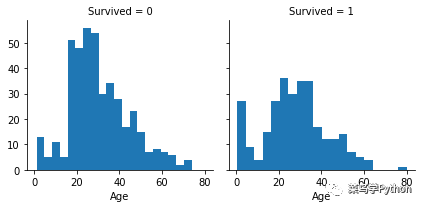
从上图中可以看出,年龄小于四岁的具有很高的存活几率,最高的幸存者年龄达到了80岁;同时年龄在15到25之间的人大都没有能够存活。所以针对于年龄因素,我们可以将其按照年龄进行分组,将年龄特征进行离散化处理,同时注意年龄确实数据的填补。
4
进行特征组合分析
通过不同特征之间的组合,创造出更具有表现力的特征。
1).首先来看一下年龄和乘客等级的组合对于存活率的影响。

从上图可以发掘的信息有等级为3的乘客数量最多,但是大部分却都没能够存活;等级为2和3中的婴幼儿乘客大部分存活了下来;而等级为1的乘客绝大部分都得以存活下来;不同等级的乘客间年龄分布不相同。上述的分析佐证了我们之前的分析。
2).继续探索一下登船口,与乘客等级以及性别对存活率的影响
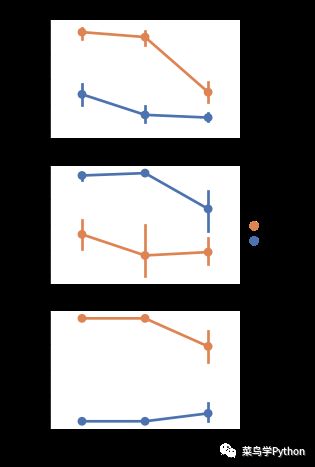
从上图我们可以提取到的信息有女性乘客在整体上的存活率要高于男性;在Q口登船的等级为3的男性比等级为2的男性具有更高的生存率。因此登船口特征也需要进行缺失值填充并加入到训练模型中。
5
特征工程
通过前面的几个步骤,我们已经对感兴趣的属性也有个大概的了解了。下一步我们就该处理这些数据,为机器学习的建模做准备。特征工程对于一个项目来说非常重要,从某种程度上来说,它比机器学习模型还要重要。
1).增添和删除特征
首先,针对于最原始的数据,我们需要把对最终建模没有帮助或者是数据确实比较严重的特征进行删除,这里,我们将'Ticket'和'Cabin'两个特征进行删除。需要注意的是,特征工程需要在训练集和测试集上进行一样的操作。

2).从数据分析中得到的结果
重新组合新的特征来增加特征维度。这里,我们将乘客的名字,进行重新组合,因为名字也是一个维度特征,其包含Master、Miss、Mr等代表身份性别的信息。我们按照其名字中的关键字,对数据集添加新的特征‘Title’,并删除训练集的‘Name’和‘PassengerId’特征,以及测试集中的‘Name’特征,处理完成后的训练集如下所示:

3).合并特征和特征因子化
由于机器学习的模型大都是针对与数值型特征进行处理,所以我们需要将类目型或者字符型特征转化为数值型特征,然后根据前面的数据分析,来判断是否将数值进行离散化或者是将数据进行合并。
根据前面的分析,我们可以将年龄特征进行离散化,而年龄特征中存在缺失数据,因此需要对缺失的数据进行填充。一般对于连续数值型特征有三种填充方式。
根据已知的数据,计算出均值和标准差,然后根据均值和标准差产生随机数据进行填充
根据缺失数值的特征跟其他特征之间的关系,进行分类,然后根据分类特征的中位数进行填充,例如,我们以年龄、性别和Pclass为相关性特征,使用Pclass、Sex的组合数据来推测年龄。
结合前面的两种方法。因此,不需要基于中位数猜测年龄值,而应根据Pclass和Sex组合的集合在均值和标准差之间产生随机数来进行填充。
这里我们采用第二种方法对年龄特征中的缺失数据进行填充。

4).然后处理填充之后的年龄特征
根据年龄大小切分成5等分,并根据年龄的分布范围,对其进行编码,增加‘AgeBand’特征。对于票价‘Fare’特征,同样也按照年龄特征的处理方式进行处理。
对于‘Parch’和‘SibSp’特征,按照我们前面所介绍的那样,将其合并为一个单独的特征,命名为‘FamilySize’。然后根据‘FamilySize’的数值是否为‘0’,增加特征‘IsAlone’。
如果‘FamilySize’数值大于0,那么‘IsAlone’就为0,否则‘IsAlone’特征就为1。对于‘Sex’和‘Embarked’特征,我们对其进行特征因子化处理,也即根据其特征数值将其转化为数字。
最终数据集如下所示:
traindata:

testdata:

数据处理完毕,接下来我们就用二分类问题中常见的逻辑回归算法来处理数据,我们首先用训练集来训练sklearn中的LogisticRegression模型,然后在针对测试集进行预测:

我们将预测的结果提交到kaggle官网上进行评测,看一下

结果还算理想,毕竟只是一个简单的baseline模型。后续如果大家想继续调优的话,可以从数据入手,继续挖掘数据本身的潜在特征,结合特征工程,重新处理特征或者组合特征,也可以从模型入手,进行模型的调优,或者是采取模型融合的方式,进一步提高正确率。
以上就是小编为大家带来的机器学习实战 ,希望大家能够有所收获。觉得对你有用,欢迎吱一声,捧个场!
趣味游戏文章:
太好玩了!用Python写个弹球游戏2.0
巧妙的Python数据结构玩法|实战德州扑克
手把手教你,菜鸟也能用Python写一个2048游戏
用Python做个美少女大战小怪兽
强烈推荐,用Python轻松打造定制款《植物大战僵尸》
Python心得和技巧:
零基础学了8个月的Python,到底有啥感悟
我珍藏的一些好的Python代码,技巧
菜鸟写Python程序,如何从新手变老手
菜鸟必收藏,13个Python惯用小技巧