论文读书笔记-主题-word representations learning & Evaluation
[2014]Dani Yogatama Manaal Faruqui Chris Dyer Noah A. Smith.Learning word representations with hierarchical sparse coding Word Embedding learning&evaluation 类文章
卡内基梅隆大学的语言技术研究所的学者所写
基于稀疏编码的改进。什么是稀疏编码可以参考http://www.cnblogs.com/tornadomeet/archive/2013/04/13/3018393.html
文中作者将自己提出的方法与其它几个baseline 方法比较:
- PCA(principal component ananlysis) from Turney and Pantel
- RNN(recurisive neural network) from Mikolov et al.
- log bilinear model&noise-contrastive estimation(NCE) from Mnih and Teh
- CBOW&negative sampling from Mikolov et al.
- Skip gram&negative sampling from Mikolov et al.
- NNSE(non0negative sparse embedding) from Murphy et al.
-
CBOW&HS from Mikolov et al.
-
Skip gram&HS from Mikolov et al.
在以下四个benchemark tasks上(这四个是最常用的用于检验word embedding质量的任务):
- Word similarity(使用了10个不同的word similarity datasets)
- Syntactic and semantic analogies
- Sentence completion
- Sentiment analysis
- CW from Collobert et al. (Senna系统)
- RNN-DC from Huang et al
- HLBL from Mnih and Hinto
- NNSE from Murphy et al.(来自于另外的人的实现 from Mairal,J. et al.)
[2011]A. Bordes, J. Weston, R. Collobert, and Y. Bengio. Learning structured embeddings of knowledge bases. In AAAI, 2011. Word Embedding Learnig类文章
概述:尽管知识库能够被用于许多目的,如接近人类推理、产生直观可用的词典、为语义网提供全球的在线信息来源等,但是,其高度结构化和有组织的数据可以被用于其它人工智能领域。
主旨:学习知识库中的entities的vector representations。为了实现generalizing to new reasonable relations,提出一个基于创新的神经网络架构的学习过程,使得任何一种之前知识库中已有的符号表示嵌入到一个更灵活的连续向量空间中,而在这个空间中原有的知识被增强。Our work is based on a model that learnsto represent elements of any KB into a relatively low (e.g.50) dimensional embedding vector space.Our model learns one embedding foreach entity (i.e. one low dimensional vector) and one operator for eachrelation (i.e. a matrix).
在含有成千上万的entity和entity之间relationship的WordNet上训练出新的低维(简洁的)词向量。
实验评估:应用学习出的word representations于四个具体应用上Ranking、Generalization、Entity Embeddings、Knowledge Extraction from Raw Text。
一些笔记:
- 类似于C&W的SENNA,训练中采用的目标函数是关于三元组的打分函数,思路就是判断一个词被随机另一个词取代后(建立负训练样本),两者打分函数的差值是否大于1。利用随机梯度下降迭代,求
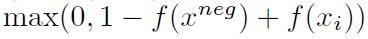 的最小值,其中f函数是
的最小值,其中f函数是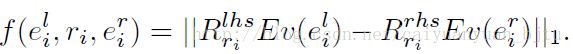 。
。 - 衡量算法的好坏用rank指标(Table3),这儿没看明白。疑问:没有明确关系的entity之间由训练函数训练出的结果,由什么判断?准确率?显然不合适。
- embedding能捕获语义,在没有句子结构的情况下。
- 探索维度的影响,找出最小的有效维度空间。
- 说明了词对的方向orientation的重要性。
[2009] T. Mikolov, J. Kopecky´, L. Burget, O. Glembek and J. Cˇ ernocky´. Neural network based language models for higly inflective languages, In: Proc. ICASSP 2009.
word vectors第一次利用单层隐藏层的神经网络学习,word vector被用于训练出NNLM(neural network language model),相对于statistical language modeling有所不同。
[2013]Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. ICLR Workshop
主旨:研究新的模型架构,使得词之间的线性规律(关系)保留。作者为此设计了一个综合的测试集,去挖掘语法规律和语义关系,通过结果的准确率指标评价。在追求最大的准确率的同时,希望计算复杂度最小。
在文中,介绍了前向反馈神经网络语言模型NNLM、循环神经网络语言模型RNNLM、新型的两个log-linear对数线性模型(CBOW和Skip-gram)。这些语言模型都是通过“随机梯度下降”和“反向传播backpropagation”去训练得出的。文章里分别列出了模型的计算复杂度公式。实验1基于类比数据库和类比task,通过计算语义关系和语法关系的预测准确率,比较这些不同模型。实验2 在CBOW模型下,设置不同的词向量维度和训练预料大小,比较语义-语法关系的总准确率。实验3在DistBelief distributed framework分布式框架下,利用并行技术(mini-batch asynchronous gradient descent 和 adaptive learning rate procedure called Adagrad)比较各个模型在计算速度都提高的情况下,准确率和训练时间的大小。实验4基于Microsoft sentence completion challenge大赛任务,比较各个模型框架所得准确率。
一些笔记
- 作者通过实验,发现训练时间和准确率与词向量的维度、训练数据的数量规模都有关。
- 这个文章的实验不考虑multi-word实体,也就是短语。
- 实验中的学习速率是线性减小的,而不是保持不变。
- 作者说词向量明显可以在选择“不合群词”的等任务里能够得到高准确率。
- 在第四个实验中发现架构的组合是个好办法,比如skip-gram+RNNLMs。
- 作者提出基于词向量的神经网络已经应用于很多NLP任务,比如情感分析sentiment analysis和释义检测paraphrase detection。未来他们要做的是将本文所提技术与Latent Relational Analysis技术或其他技术去比较,从而帮助研究团体去改进已有的有关于评估词向量的技术。
[2013]Tomas Mikolov,Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean.Distributed Representations of Words and Phrases and their Compositionality.2013.
主旨:总结了word2vec 工具所有的技术(word2vec是下述技术的合集),重点在Skip-gram model下,而CBOW model没有提。该文章是“Efficient Estimation of Word Representations in Vector Space”的延伸。
1、提出在Skip-gram model下的输出层的两种不同计算方式(取代传统的softmax函数),即hierarchical softmax-Huffman层级softmax霍夫曼编码和Negative Sampling负采样。2、对原始的(original)Skip-gram model进行了扩展:欠采样(目的是提高训练速度和结果准确率)。
3、结合两个方法或者说特性,将词向量扩展产生短语向量。分别是:词向量可线性相加;在学习短语向量表示的时候,简单地将一个短语看成一个token。
4、描述了Skip-gram模型的有趣特性,即得到的向量有数学关系,可加、减。
实验后所得结论:
1、在训练预料库越大,结果越准的默认原则下,本文作者的结果无论从训练时间还是准确率(因为用的预料库规模大于其他以前文献几个数量级)上,都优于前人的工作。
2、不仅能得到词向量,还能得到短语向量,而且不影响线性特性。
3、Skip-gram架构和HS-Huffman算法对于低频的罕见词尤其有效。
4、对于训练算法和超参数的选择要依据具体的task,具体问题具体分析。
欠采样:在神经网络模型中,如”the”、”a”等频繁词会降低训练的速度以及损害训练结果准确性,为了解决这个问题,引入了欠采样技术。原理:以某个随机的概率舍弃词典中的词,越频繁的词被舍弃的概率越大,因此,在不改变词频排列顺序的前提下,大大减小了频繁词与非频繁词的比例,从而突出了非频繁词,训练结果更加准确,训练的速度也更快。
一些笔记
- 从实验结果Table1可知,在HS-Huffman方法下,使用了10-5的欠采样技术虽然提高了训练速度,但是减低了总准确率。(我认为是可以改进的地方)
- skip-gram的线性.特性使得它训练出的词向量更加适用于做”线性类比推理“这一类的任务或者说应用。
ICLR 2013. Efficient Estimation of Word Representations in Vector Space[转]
在NLP中,每一个词语都表示称实数向量的形式(称为word embedding or word representation)。通常词语的实数向量用神经网络进行训练得到,如Bengio在2003年的工作,以及在此基础上的改进,如:用递归的神经网络进行训练。不过这些方法计算复杂度较高,对词表大小、训练语料规模都有限制。本文的方法提供了一种log-bilinear模型,去除了神经网络的隐含层,仅用线性表示能力,计算词语的实数表示向量。
1. Model Architectures
1.1 Feedforward Neural Net Language Model (NNLM)
回顾Bengio在2003年的工作。神经网络分为输入层(词语id)、投影层(projection,由id转为词向量)、隐含层和输出层。整个网络的参数为:
Q = N*D + N*D*H + H*V
其中N*D为输入层到投影层的权重,N是ngram中的n,表示上下文长度,D是每个词的实数表示维度;N*D*H 为投影层到隐含层的权重个数,H是隐含层节点个数;H*V是隐含层到输出层的权重个数,V是输出层节点个数。
为了提速,作者对输出层进行改造,用huffman树代替线性结构,从而使得参数降低为 H * log(V)
1.2 Recurrent Neural Net Language Model (RNNLM)
RNNLM的参数个数为
Q = H*H + H*V
1.3 Parallel Training of Neural Networks
google有一个工具叫DistBelief,可以让节点机与中心服务器同步神经网络中的梯度值,从而同步神经网络的各个权重。不过再后来看作者的源代码的时候,作者似乎只是用了linux多线程,来进行并行训练。
2. New Log-linear Models
这是作者着重介绍的模型。
作者发现,大量的计算都消耗在神经网络的非线性隐含层(The main observation from the previous section was that most of the complexity is caused by the non-linear hidden layer in the model),所以作者去除隐含层,以加快计算。另外,作者从前的研究成果,将词语实数向量的计算和神经网络对Ngram的训练相分开,相比同时训练,能大大提高效率(neural network language model can be successfully trained in two steps: first, continuous word vectors are learned using simple model, and then the N-gram NNLM is trained on top of these distributed representations of words.)
2.1 Continuous Bag-of-Words Model
去除了隐含层,所有N个上线问词语都投影到一个D维实属向量上(加和平均)。网络结构如下:

看样子是纯的线性结构;不过看作者的源代码(利用梯度那一部分),似乎是exp指数节点。
2.2 Continuous Skip-gram Model
上面是根据上下文来输出当前词语。另一种结构,是根据当前词语来输出网络上下文。如下:

3. 实验结果
3.1 Task Description
作者设计这样的任务:D(河北)-D(石家庄)+D(哈尔滨)=D(黑龙江)。D是词语的实属向量。上面公式解释为:河北的省会是石家庄,经过运算,哈尔滨是黑龙江的省会。其时写成D(河北)-D(石家庄)=D(黑龙江)-D(哈尔滨)更容易理解。作者先找出“河北--石家庄”这样的词语对儿,训练出来词语实属向量之后,用上面的计算来验证是否正确,计算出准确率。用准确率来衡量得出的词语实数向量的好坏。
3.2 Maximization of Accuracy
扩大两倍的向量维度,和扩大两倍的训练集,都能提升准确率,且增加的训练时间相同,不过提升的准确率幅度可不相同。在某些时候,提升向量维度的作法使得性能提升更大;某些时候,增加训练语料更好些。向量维度一般300维之后,再增加向量维度的作用就不大了。作者的学习速率设定为0.0025(很小啊)。
3.3 Comparison of Model Architectures
模型之间的相互比较,CBOW效果最好,然后是CSGM,Bengio2003的模型效果反而不好。还有可以看到,作者迭代了三次和迭代了一次,效果差别不大。所以对整个训练集来讲,迭代一次就够了。(个人观点哈)
3.4 Large Scale Parallel Training of Models
3.5 Microsoft Research Sentence Completion Challenge
微软的测试集合,就是有1k个句子,去掉其中一个词,然后给出五个词作为候选,任务是找到最合适的那个词使句子完整。作者把这个任务转成了计算句子概率的任务(对五个词都拼成句子,计算概率,选择概率最大的那个)。
[2014] Distributed Representations of Sentences and Documents. Quoc Le, Tomas Mikilov. ICML, 2014.
Word Embedding learning 类文章,针对段落和文档的词向量学习
Mikilov继词向量模型CBOW和Skip-gram之后, 在2014年的ICML上又发了一篇论文, 提出了两种把文章表示成向量的方法。
1. PV-DM(Distributed Memory Model of Paragraph Vectors)
如上图所示,在之前的NNLM中,我们是根据前$n-1$个词的拼接或者加和来预测下一个词(第n个词),而在PV-DM模型中,我们只需要再加上一个文章向量(和之前的词向量做拼接或者加和)。注意文章向量只有在训练该文章的上下文时(亦即连续的$n$个词)时才会用到, 在训练别的文章的上下文时不会用到,也就是文章向量不能跨paragraph,是个局部向量。而词向量,则是在所有的文章之间共享的。
在训练时, 只需要使用后向传播算法, 并且同时把softmax的权重和输入看做待训练的参数即可(就像所有的Neural Language Model一样). 在预测一个新的文章的向量时, 固定softmax的权重和词向量, 然后只把新文章的词向量(亦即输入)看做参数进行训练, 最后得到的向量就是新文章的向量.
2. PV-DBOW(Distributed Bag of Words version of Paragraph Vector)
该模型的参数比较少,只有softmax权重,而PV-DM则有softmax权重和词向量两种参数, 该模型很类似于Skip-gram模型。
一些笔记
- 两种算法都是无监督的,有大量的数据集可以用, 训练比较充分。
- PV-DM考虑了词的顺序,而同样考虑了词的顺序的n-gram模型的特征太多,很难有好的性能。
- PV-DM的性能一般比PV-DBOW好。
- 在PV-DM中, 使用拼接比加和要好。
- 窗口的大小最好是经过交叉验证,作者推荐5-12。
一些总结性笔记:
架构:skip-gram(慢、对罕见字有利)vs CBOW(快)
训练算法:分层softmax(对罕见字有利)vs 负采样(对常见词和低纬向量有利)
欠采样频繁词:可以提高结果的准确性和速度(适用范围1e-3到1e-5即10的-5次方)
文本(window)大小:skip-gram通常在10附近,CBOW通常在5附近
——————————————————————————————————————————————————————————————————————————