Python多线程爬虫,小米应用商城app信息爬虫程序,多线程和多进程两种实现思路
目录
小米应用商城app信息爬虫程序
1.需求分析
2.url分析
3.程序设计思路
4.程序代码
5.程序优化与升级
小米应用商城app信息爬虫程序
1.需求分析
看到小米应用的首页:http://app.mi.com/,我们的目的是将游戏、使用工具、影音视听等应用分类下的所有app信息(主要是名字和链接地址)爬取下来。爬取量还是很大的,游戏应用有2000个左右,其他像实用工具,聊天软件讲道理要少很多,没想到这些app的数量都在2000个左右。

最大页码数在67页,没有超过这个页数的,小米这个应用商店属实做的不咋地呀。不过页数对我们的需求没有影响,我们的目的就是要爬取所有app的名字和url链接地址。

2.url分析
点击游戏分类,url变为:http://app.mi.com/category/15
点击实用工具分类,url变为:http://app.mi.com/category/5
点击应用试听分类,url变为:http://app.mi.com/category/27
可以确信http://app.mi.com/category/是固定的,区别在与分类的id号,但是目前似乎看不出什么规则
来到游戏分类首页,点击第一页,此时url变为:http://app.mi.com/category/15#page=0,可以看出page代表页数,而游戏应用分类一共67页,每页30个app。
进入控制台,查看元素节点的格式,可以很明显的看出其结构,xpath的思路为://ul[@class="applist"]/li/h5/a/text()。但是这里我们不用xpath,这里提供另一种方式来获取信息。

进入控制台Network界面,点击XHR,查看Ajax异步交换数据的页面

点击Preview预览,可以看到一页的app信息就这么获取到了,而且还是json格式的,所以只要我们拿到了这个ajax的请求页面,也就拿到了信息,比用xpath来做解析效率要高的多。
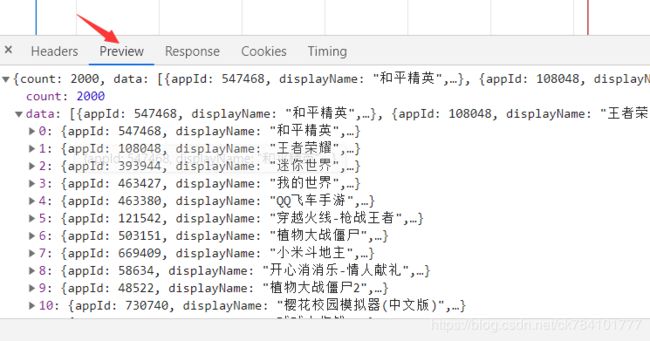
再来看看如何获取整个请求的URL ,http://app.mi.com/categotyAllListApi?,这部分是固定的,page=0&categoryId=15&pageSize=30,page是变动的,页码数,categoryId是应用的id号,游戏应用id号为15,pageSize=30也是固定的,一页为30个。那么我们要做的就是写一个循环,将page设置一个区间来更新URL,比如67页,就可以写一个1-67的循环。在来看categoryId,这个id的话就要我们去首页提取爬取了。

总结:到目前为止,我们要做的有3步:
1.在首页获取所有应用商店的categoryId号
2.获取每个应用的页码数,生成对应的url
3.根据url返回的json数据来获取app信息
3.程序设计思路
1)在首页获取所有应用商店的categoryId号
根据这个需求,设计一个函数:get_allId(),要求获得所有应用的categoryId号。这个函数要实现还得去首页爬,这里我们可以用xpath来做,也可以用正则来匹配。
xpath为://ul[@class=category-list]/li/a/@href
正则为:li>(.*?)

2.获取每个应用的页码数,生成对应的url
写一个函数get_total()来获取单个应用程序的页码数,思路是这样的,根据http://app.mi.com/categotyAllListApi?page=0&categoryId=15&pageSize=30这个URL,我们可以直接拿到app的总数count,根据这个总数,再除以每页出现的个数(这里统一为30),就可以得到页码数。但是2000除30是无法整除的,所以要写一个判断,判断整数是否可以整除30,不可以的取总数除30向下取整的结果再加1。

3.根据url返回的json数据来获取app信息
有了id号,页码数,我们就可以用requests模块来请求数据了,写一个函数来发请求即可。
4.加入多个线程
如果单进程加单线程的模式去跑这个程序,可能会花较多的时间,所以我们可以启多个线程去做爬虫。思路是这样:创建并启动5个线程并将他们加入线程队列,要求线程是全局的。创建线程的时候,target指向执行的函数。
既然加入了多个线程,相应的也要创建一个队列,这个队列为url队列,线程执行操作的时候向队列里取结果并执行。
4.程序代码
import requests
import time
import json
import re
from threading import Thread
from UserAgent import get_UserAgent
from queue import Queue
from lxml import html
class MiAPPSpider(object):
def __init__(self):
self.url="http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30"
self.q=Queue()
# 功能函数:获取应用id号
def get_allId(self):
url="http://app.mi.com/"
rep = html = requests.get(url=url, headers={"User-Agent": get_UserAgent()}).text
regex = '(.*?) '
pattern = re.compile(regex,re.S)
id_lists = pattern.findall(rep)
for i in id_lists:
# 调用入队函数,把id号的结果交给这个函数处理
self.URL_inQueue(i[0])
# 注意这里一定让线程休眠,访问太频繁会被封
time.sleep(1)
# 功能函数:获取某个应用的页码数
def get_total(self,id):
# 获取json页面,json页面包含了总数
url=self.url.format(0,id)
html=html=requests.get(url=url,headers={"User-Agent":get_UserAgent()}).text
# 将结果转换为json格式
html=json.loads(html)
# 获取json中的count值
count=html['count']
total=0
if count % 30 == 0:
# //代表向下取整
total=count // 30
else:
total=count // 30 + 1
return total
# 功能函数:将url加入队列
def URL_inQueue(self,id):
# 调用get_total()方法获取单个app的页码数
total=self.get_total(id)
for i in range(total):
# 把id和页码数塞到url中,形成完整的url
url=self.url.format(i,id)
# 把URL加入队列
self.q.put(url)
# 核心函数:用于向小米商店请求结果
def parse_html(self):
# 设置一个死循环,不设循环的话线程只会执行一遍
while True:
# 循环退出的结果是队列为空
if not self.q.empty():
# 在队列里取一条url
url=self.q.get()
html=requests.get(url=url,headers={"User-Agent":get_UserAgent()}).text
# json化
html=json.loads(html)
items={}
for i in html['data']:
items["name"]=i['displayName']
# 输出结果
print(items)
else:
break
# 执行函数,为程序入口
def run(self):
# 首先调用get_allId获取所有id,这get_allId这个函数又会调用URL_inQueue函数
# 此时所有的url就已经拿到了
self.get_allId()
t_lists=[]
# 创建并启动线程
for i in range(5):
# 线程的模板函数为parse_html()
t=Thread(target=self.parse_html)
t_lists.append(t)
t.start()
# 结束线程
for t in t_lists:
t.join()
if __name__=='__main__':
start_time=time.time()
spider=MiAPPSpider()
spider.run()
end_time=time.time()
print("执行时间:%.2f" % (end_time-start_time))
执行效果:

注意:
from UserAgent import get_UserAgent : 这是我的一个反爬策略(通过交替User-Agent),代码如下
import random
agentPools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0"
]
def get_UserAgent():
return agentPools[random.randint(0,2)]
5.程序优化与升级
1.将数据结果保存到文件或数据库
将提取到的数据不仅仅是打印出来,而是以json或scv的格式保存。也可以存到数据库,这里说下存json文件的思路,因为爬虫程序是多线程的,所以在写文件时一定要加写锁。以下是部分代码,首先在初始化函数中打开一个文件,创建一个锁,在调用写文件操作时加锁,写完后释放锁。在程序结束的地方关闭文件。
from threading import Lockdef __init__(self): self.f=open("C:\\Users\\Administrator\\Desktop\\xiaomi.json",'a') self.lock=Lock()def parse_html(self):.....................
self.lock.acquire() json.dump(items,self.f,ensure_ascii=False) self.lock.release().....................
def run(self):.....................
self.f.close()
2.多进程版本
其实将多线程版本改成多进程版本对程序的执行效率并没有什么影响,相反还会增大开销。首先需要理解一下什么是多线程,考虑单个线程在进行页面请求时陷入等待,此时整个程序都是等待的,如果这个瞬间有两个线程,那么另一个线程就会继续执行请求,整体上可以缩短进一半的时间。多线程在网络爬虫上的使用效果和兼容性是非常好的。
相反再看多进程,同样的请求,同样的处理方式,但就是会比多线程消费多的时间,这部分时间的就是切换进程时消耗的。由于进程拥有独立地址空间,每当启动一个进程,系统都会为其分配地址空间,这对于内存又是一部分消耗。
在做网络爬虫时一般不考虑多进程,但是也可以写,下面是思路:
引入multiprocessing模块的两个方法,Process和Queue,再将创建线程的语句改为创建进程即可,Queue在这里非常重要,我们之前使用的Queue来自queue模块(from queue import Queue),queue模块是不共享进程的,我们知道创建进程是会创建独立的地址空间,对于每一份对象都会给自己来一份,如果queue也做n份,那么得到的结果也会乘n变,因为不共享队列,所以多进程会做重复的事。所以这里要引入multiprocessing模块的Queue,这个Queue是多进程的共享队列。
from multiprocessing import Process,Queuet=Process(target=self.parse_html)