“宇宙最强”GPU —— NVIDIA Tesla V100 面向开发者开放试用!
加速科学发现、可视化大数据以供获取见解,以及为消费者提供基于 AI 的智能服务,这些都是研究人员和工程师们的日常挑战。解决这些挑战需要更为复杂且精准的模拟、对于大数据的强大处理能力、或是训练和运行复杂精妙的深度学习网络。这些工作负载还要求提升数据中心速度,以满足对指数级计算能力的需求。
对于开发者来说,这也是一个机遇与挑战并存的时代。如何才能高效分析大量数据并且得到自己想要的结果?NVIDIA 基于最新 Volta™ 架构的 Tesla® V100 是当今市场上为加速人工智能、高性能计算、数据中心应用推出的顶级 GPU,或许可以帮助开发者和企业在 AI 和 HPC 创新中占得先机。
NVIDIA® Tesla® V100 -当今数据中心 GPU 的精尖之作
NVIDIA Tesla V100 是当今市场上为加速人工智能、高性能计算和图形的数据中心 GPU 中的精尖之作。NVIDIA Tesla V100 加速器基于全新 Volta GV100 GPU,Volta 是全球功能强大无比的 GPU 架构,而 GV100 是第一种突破 100 TFLOPS 深度学习性能极限的处理器。GV100 将 CUDA 核心和 Tensor 核心相结合,在 GPU 中提供 AI 超级计算机的出色性能。现在,借助 Tesla V100 加速的系统,过去需要消耗数周计算资源的 AI 模型只需几天即可完成训练。随着训练时间的大幅缩短,在 NVIDIA Tesla V100 加速器的助力下,AI 现在可以解决各类新型问题。

Tesla V100 突破性创新性能解读
基于 NVIDIA Volta 架构的 GV100 GPU
Tesla V100 采用与 Tesla P100 相同的 SXM2 主板外形,大小为 140×78 毫米,主要区别在于 GPU 由 GV100 代替了 GP100。SXM2 主板支持 NVLink 和 PCIe 3.0 连接功能,包含可为 GPU 供应各种所需电压的高效电压调节器,额定为 300 瓦热设计功耗(TDP)。工作站、服务器和大型计算系统中可应用一个或多个 Tesla V100 加速器。

NVIDIA Tesla V100 加速器配备 Volta GV100 GPU,是世界领先的高性能并行处理器。包含 211 亿个晶体管,采用台积电 12nm FFN 专属工艺打造的它芯片面积达到了前所未有的 815 平方毫米(Tesla GP100 为 610 平方毫米)。
与上一代 Pascal GP100 GPU 一样,GV100 GPU 由 6 个 GPU 处理集群(GPC)和 8 个 512 位内存控制器组成,每个 GPC 拥有 7 个纹理处理集群(TPC),每个 TPC 含 2 个流多处理器(SM)。
含 84 个 SM 的完整 GV100 GPU,总共拥有 5376 个 FP32 核心,5376 个 INT32 核心、2688 个 FP64 核心、672 个 Tensor 核心以及 336 个纹理单元。每个 HBM2 DRAM 堆栈由一对内存控制器控制。完整的 GV100 GPU 总共包含 6144KB 的 L2 缓存。

更为重要的是,与其前身 GP100 GPU 及其他 Pascal 架构的显卡相比,GV100 在人工智能方面有非常出色的表现。

以 ResNet-50 深度神经网络为例,Tesla V100 的深度神经网络训练任务中的速度比 Tesla P100 快 2.4 倍。如果每张图像的目标延迟是 7ms,那么 Tesla V100 使用 ResNet-50 深度神经网络进行推理的速度比 P100 快 3.7 倍。
强大的硬件规格也让 Tesla V100 具备了业界领先的浮点和整数性能。计算速率峰值在不同条件下,分别可以实现(基于 GPU Boost 时钟频率):
双精度浮点(FP64)运算性能:7.8 TFLOP/s 的双精度浮点
15.7 TFLOP/s 的单精度(FP32)性能
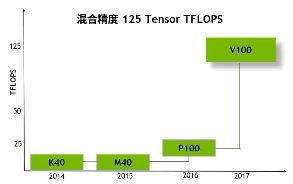
125 Tensor TFLOP/s
Tensor Core:处理神经网络的最佳选择

新的 Tensor Core 是 Volta GV100 最重要的特征,是其提供大型神经网络训练所需性能的关键。
Tesla V100 GPU 包含 640 个 Tensor 核心:每个 SM 有 8 个核心,SM 内的每个处理块(分区)有 2 个核心。在 Volta GV100 中,每个 Tensor 核心每时钟执行 64 次浮点 FMA 运算,一个 SM 中的 8 个 Tensor 核心每时钟总共执行 512 次 FMA 运算(或 1024 次单个浮点运算)。
Tesla V100 的 Tensor Core 能够为训练、推理的应用提供高达 125 Tensor TFLOPS。相比于在 P100 FP 32 上,在 Tesla V100 上进行深度学习训练有 12 倍的峰值 TFLOPS 提升。而在深度学习推理能力上,相比于 P100 FP16 运算,有了 6 倍的提升。
以上出色的表现实际上源于 Tensor Core 的基础架构,它针对人工智能关联的数据通道进行了精心的定制,从而极大地提升了极小区域和能量成本下浮点计算的吞吐量。

除 CUDA C++接口可直接编程 Tensor Core 外,CUDA 9 cuBLAS 和 cuDNN 库还包含了使用 Tensor Core 开发深度学习应用和框架的新库接口。NVIDIA 已经和许多流行的深度学习框架(如 Caffe2 和 MXNet)合作以使用 Tensor Core 在 Volta 架构的 GPU 系统上进行深度学习研究。NVIDIA 也致力于在其他框架中添加对 Tensor Core 的支持。
新一代 NVLINK
Tesla V100 中采用的 NVIDIA NVLink 可提供 2 倍于上一代的吞吐量。8 块 Tesla V100 加速器能以高达 300 GB/s 的速度互联,从而发挥出单个服务器所能提供的最高应用性能。
除了速度大幅提升之外,第二代 NVLink 还允许 CPU 对每个 GPU 的 HBM2 内存进行直接加载/存储/原子访问。NVLink 还支持一致性运算,允许读取自图形内存的数据存储在 CPU 的缓存层次结构中,进一步释放 CPU 性能。

HBM2 内存架构
相比上一代 Tesla P100,Tesla V100 采用了更快、更高效的 HBM2 架构。四个 HBM 芯片(堆栈)总共可以提供 900 GB/s 峰值内存带宽(上一代为 732GB/s)。同时 Volta 还采用了全新的内容控制器,也让内存带宽方面的优势进一步放大。在 STREAM 上测量时可提供高于 Pascal GPU 1.5 倍的显存带宽。

最大节能模式
全新的最大节能模式可允许数据中心在现有功耗预算内,每个机架最高提升 40% 的计算能力。在此模式下,Tesla V100 以最大处理效率运行时,可提供高达 80% 的性能,而只需一半的功耗。
可编程性
Tesla V100 的架构设计初衷即为了实现更高的可编程度,让用户能够在更复杂多样的应用程序中高效工作。Volta 是首款支持独立线程调度的 GPU,可在程序中的并行线程之间实现更精细的同步与写作。提高线程写作的灵活性,最终实现更高效、更精细的并行算法。
申请试用 Tesla V100,提前体验 AI 革新的未来
截至目前,Telsa V100 已经用于 NVIDIA 首款深度学习和分析专用工作站 DGX Station;阿里云、百度和腾讯等企业均已在其云服务中部署 Tesla V100;华为、浪潮和联想等原始设备制造商也已采用 Tesla V100 来构建新一代加速数据中心。目前在深度学习方面与 NVIDIA 合作的组织机构已有 19439 家,覆盖金融、汽车、教育、互联网等各类领域。
为了让开发者们体验到 Tesla V100 给 AI 、HPC 应用带来的革新,目前 NVIDIA 推出 Tesla V100 试用活动。点击「阅读原文」报名申请,报名后,将由专人安排试用细节。即刻申请,体验 AI 革新的未来!

感谢您抽出 · 来阅读此文
点击【阅读原文】即刻申请
↓↓↓