网络爬虫--python抓取豆瓣同城北京地区活动信息
感谢主赐予我们时光。
本内容只涉及技术探讨,不作为商业用途。
背景
作为入门级的爬虫,其实不需要了解复杂的正则表达式匹配,高深的网络协议。只需要了解一些基本的python语法和html请求/响应原理就能遨游在网络中抓取你想要的内容。今天就和大家分享一个用python实现爬虫的demo。
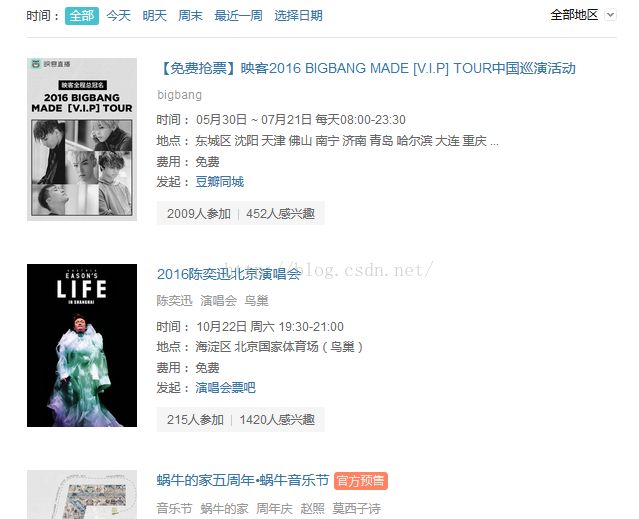
这里将豆瓣同城北京地区近期音乐活动作为目标,尝试抓取音乐活动列表29页的演出信息。
https://beijing.douban.com/events/future-music?
当然,这里python版本使用的是3.x,对于2.x的童鞋只需把代码稍作修改便可使用。编辑器使用的是pyCharm,一款优秀的IDE。
在继续往下读之前,你应该知道:1 python的基本语法 2 python类的定义与使用 3 python对网络,文件的基本操作。
为什么说是入门级的?
1 单线程:这里只是使用单线程,相比多线程来说简单好多。
2 静态页面:服务器没有使用Ajax技术动态加载数据,不涉及Ajax请求接口获取json等格式数据。
3 get方式:使用get方式直接获取数据,没用涉及post向服务器发送数据,只是传递了一个pageNum参数。
4 免登陆:部分web页面初始并没有数据可用,需要在用户登录后才会用javascript动态加载。
5 文本格式保存:在获取结果数据后没有做复杂的可视化展示,只是将提取内容写入到了一个普通的txt文件。
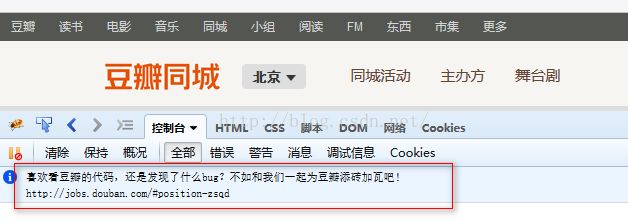
花絮:一个友好的提示
起初用firebug在控制台下看到了douban的友好提醒。。。攻城狮们还是很友好的。
分析
虽然是入门级的爬虫,但实现起来还是有几个方面值得注意:
获取当前文件所在的系统路径
路径问题在程序开发过程中虽然不算难点,但有时候足以让人头疼。
路径分为相对路径和绝对路径。相对路径以一个目录作为参考,表示相对这个目录地址的文件所在位置。绝对路径表示特定操作系统下文件的绝对地址,比如windows系统下通常以盘符开始。这里就不展开说明了。
项目中一般使用两者结合的方式。在pyCharm编辑器环境中,使用python内置函数获取当前文件所在的根目录,再拼接上所要创建的文本文件名。
path = os.path.abspath(os.path.dirname(sys.argv[0]))
f = open(path+'/douban_events.txt','a',encoding='utf-8')对抓取的内容设置字符编码集
字符编码集的处理在本例中有两处使用。
由于使用requests的get()方法爬取的内容在解析为文本的时候会首先根据页面上的编码集来解析文本,页面上一般都为utf-8格式,也不排除使用unicode格式的,所以为了保险起见,在获取页面内容后首先设置一下它的编码集。这里我将它设置为utf-8格式。
另外一处是在向文件写入内容的时候,如果不设定编码集,程序运行过程中会报错。为了与抓取内容的编码集保持一致,这里我也将它设置为utf-8格式
#抓取内容后设置编码集
html = requests.get(url)
html.encoding = 'utf-8'
#文件写入时设置编码
f = open(path+'/douban_events.txt','a',encoding='utf-8')正则表达式换行符的匹配
由于网页格式的不确定,在利用正则表达式匹配所需要内容时有时会遇到空格和换行。
匹配换行符使用regex=(' \r\n ')(回车换行),regex=(' \n ')(换行)
空格使用regex=(' \s ')(一个空格)
由于\s的匹配既包含了空格又包含了换行,所以在遇到
将抓取内容写入到txt
将每一项活动信息保存在变量entity字典里面,对应的key键值有title,time,position,fee
再将这样的每一条活动记录(以字典格式存储)追加到变量eventInfo的列表中:eventInfo.append(entity)
至此,数据结构有基础的童鞋应该能刻画出数据存储的格式。对,就是这样的数据格式在saveEntity()函数中再通过遍历列表的每一项,将数据持久化。
这里持久化仅仅是通过写入到txt文本文件来实现。
f = open(path+'/douban_events.txt','a',encoding='utf-8')
for event in eventInfo:
f.writelines('title:' + event['title'] + '\n')
f.writelines('time:' + event['time'] + '\n')
f.writelines('position:' + event['position'] + '\n')
f.writelines('fee:' + event['fee'] + '\n')
f.writelines('\n')
f.close()部分结果

最后,贴下源码。
import re
import requests
import os
import sys
#url = 'https://beijing.douban.com/events/future-music?start=0'
#header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0'}
#定义一个全局目录路径
path = os.path.abspath(os.path.dirname(sys.argv[0]))
class douban_local_activity(object):
def __init__(self):
print('开始爬取内容')
#获取单个连接html文本
def getSource(self,url):
html = requests.get(url)
html.encoding = 'utf-8'
return html.text
#根据页数获取所有的链接
def changePage(self,url,totalPage):
startPageNum = int(re.search('start=(\d+)',url,re.S).group(1))
pageGroup = []
for i in range(startPageNum,totalPage+1):
perLink = re.sub('start=\d+','start=%s' % (i*10),url,re.S)
pageGroup.append(perLink)
return pageGroup
#抓取单页所有的活动信息
def getAllEvents(self,source):
biggerHtml = re.search('', source, re.S).group(1)
events = re.findall('(- \s+