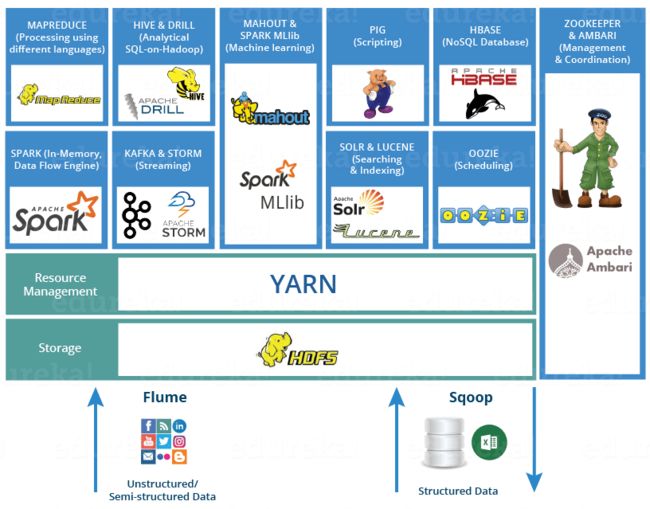
Hadoop生态系统:用于处理大数据的Hadoop工具
HADOOP生态系统
在上一个Hadoop Tutorial上的博客中,我们讨论了Hadoop,其功能和核心组件。现在,下一步是了解Hadoop生态系统。在开始使用Hadoop之前,这是一个必不可少的主题。 这个Hadoop生态系统博客将使您熟悉Hadoop认证所需的行业广泛使用的大数据框架。
Hadoop生态系统既不是编程语言也不是服务,它是解决大数据问题的平台或框架。您可以将其视为一个套件,其中包含许多服务(嵌套,存储,分析和维护)。让我们讨论并简要了解服务如何单独和协同工作。
以下是Hadoop组件,它们共同构成了Hadoop生态系统,我将在此博客中介绍每个组件:
- HDFS- > Hadoop分布式文件系统
- 纱 -> 另一位资源谈判员
- MapReduce- >使用编程进行数据处理
- Spark- >内存中数据处理
- PIG,HIVE- >使用查询的数据处理服务(类似于SQL)
- HBase- > NoSQL数据库
- Mahout,Spark MLlib- >机器学习
- Apache Drill- > Hadoop上的SQL
- Zookeeper- >管理集群
- Oozie- >作业计划
- Flume,Sqoop- >数据提取服务
- Solr&Lucene- >搜索和索引
- Ambari- >供应,监视和维护集群
HDFS
- Hadoop分布式文件系统是Hadoop生态系统的核心组件,或者可以说是其核心。
- HDFS就是其中之一,它可以存储不同类型的大型数据集(即结构化,非结构化和半结构化数据)。
- HDFS在资源上创建了一个抽象级别,从那里我们可以将整个HDFS视为一个单元。
- 它有助于我们在各个节点上存储数据并维护有关存储数据(元数据)的日志文件。
- HDFS具有两个核心组件,即NameNode和DataNode。
- 在NameNode的是主节点,并没有存储的实际数据。它包含元数据,就像日志文件一样,或者您可以说是目录。因此,它需要较少的存储空间和较高的计算资源。
- 另一方面,所有数据都存储在DataNode上,因此需要更多的存储资源。这些DataNode是分布式环境中的商品硬件(例如笔记本电脑和台式机)。这就是为什么Hadoop解决方案非常具有成本效益的原因。
- 在写入数据时,您始终与NameNode通信。然后,它在内部向客户端发送一个请求,以在各种DataNode上存储和复制数据。

纱
将YARN视为Hadoop生态系统的大脑。它通过分配资源和安排任务来执行您的所有处理活动。
- 它具有两个主要组件,即ResourceManager和NodeManager。
- ResourceManager还是处理部门中的主要节点。
- 它接收处理请求,然后将请求的各个部分相应地传递到发生实际处理的相应NodeManager。
- NodeManager安装在每个DataNode上。它负责在每个单个DataNode上执行任务。
- 调度程序:调度程序根据您的应用程序资源需求,执行调度算法并分配资源。
- ApplicationsManager: ApplicationsManager接受作业提交时,与容器(即进程执行所在的数据节点环境)进行协商,以执行特定于应用程序的ApplicationMaster并监视进度。ApplicationMaster是驻留在DataNode上的恶魔,并与容器通信以在每个DataNode上执行任务。ResourceManager具有两个组件,即Scheduler和ApplicationsManager。
映射还原
 它提供了处理逻辑,是Hadoop生态系统中处理的核心组件。 换句话说,MapReduce是一个软件框架,可帮助编写使用Hadoop环境中使用分布式和并行算法处理大型数据集的应用程序。
它提供了处理逻辑,是Hadoop生态系统中处理的核心组件。 换句话说,MapReduce是一个软件框架,可帮助编写使用Hadoop环境中使用分布式和并行算法处理大型数据集的应用程序。
- 在MapReduce程序中,Map()和Reduce()是两个函数。
- 该地图功能进行操作,如过滤,分组和排序。
- 而Reduce函数将汇总并总结map函数产生的结果。
- 映射功能生成的结果是一个键值对(K,V),用作“减少”功能的输入。

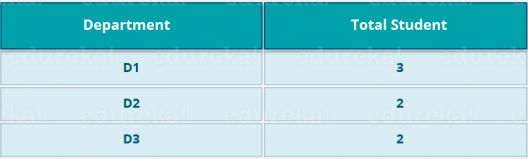
让我们以上述示例为例,以更好地理解MapReduce程序。
我们有一个学生及其所属部门的样本案例。我们要计算每个部门的学生人数。 最初,Map程序将执行并计算出现在每个系中的学生,从而产生如上所述的键值对。 该键值对是Reduce函数的输入。 然后,Reduce函数将汇总每个系的总和,并计算每个系中的学生总数并得出给定的结果。
阿帕奇猪

- PIG包含两个部分:Pig Latin,语言和Pig 运行时,用于执行环境。您可以更好地将其理解为Java和JVM。
- 它支持猪拉丁语语言,该语言具有类似于SQL的命令结构。
由于每个人都不属于编程背景。因此,Apache PIG减轻了他们的负担。 您可能想知道如何?
好吧,我会告诉你一个有趣的事实:
猪拉丁10行=大约 200行Map-Reduce Java代码
但是当我说在Pig作业的后端执行map-reduce作业时,请不要感到震惊。
- 编译器在内部将猪拉丁语转换为MapReduce。它产生了一组MapReduce作业,这是一个抽象(类似于黑匣子)。
- PIG最初由Yahoo开发。
- 它为您提供了一个构建ETL(提取,转换和加载)数据流,处理和分析庞大数据集的平台。
猪如何工作?
在PIG中,首先使用load命令加载数据。 然后,我们对其执行各种功能,例如分组,过滤,联接,排序等 。最后,您可以将数据转储到屏幕上,也可以将结果存储回HDFS中。
APACHE HIVE

- Facebook为精通SQL的人创建了HIVE。因此,HIVE使他们在Hadoop生态系统中工作时感到宾至如归。
- 基本上,HIVE是一个数据仓库组件,它使用类似于SQL的界面在分布式环境中执行读取,写入和管理大型数据集。
HIVE + SQL = HQL
- Hive的查询语言称为Hive查询语言(HQL),与SQL非常相似。
- 它具有2个基本组件:Hive命令行和JDBC / ODBC驱动程序。
- 的蜂房命令行接口用于执行HQL命令。
- 同时,使用Java数据库连接(JDBC)和对象数据库连接(ODBC)建立与数据存储的连接。
- 其次,Hive具有高度可扩展性。这样,它既可以满足大数据集处理(即批处理查询处理)又可以进行实时处理(即交互式查询处理)这两个目的。
- 它支持SQL的所有原始数据类型。
- 您可以使用预定义功能,也可以编写定制的用户定义功能(UDF)来满足您的特定需求。
或者,您可以转到此综合视频教程,其中讨论了Hadoop生态系统中存在的每个工具:
Hadoop生态系统| 埃杜雷卡
APACHE MAHOUT

现在,让我们谈谈以机器学习而闻名的Mahout。Mahout提供了一个用于创建可扩展的机器学习应用程序的环境。
那么,什么是机器学习?

大数据Hadoop认证培训
- 讲师指导的课程
- 现实生活中的案例研究
- 评估
- 终身访问
机器学习算法使我们能够构建自行学习的机器,而无需明确编程即可自行发展。 根据用户的行为,数据模式和过去的经验,它可以制定重要的未来决策。 您可以称其为人工智能(AI)的后代。
Mahout做什么?
它执行协作过滤,聚类和分类。 有些人还认为缺少频繁项集是Mahout的功能。让我们分别了解它们:
- 协作过滤: Mahout挖掘用户的行为,其模式和特征,并以此为基础进行预测并向用户提出建议。典型的用例是电子商务网站。
- 聚类:它将类似的数据组织在一起,例如文章可以包含博客,新闻,研究论文等。
- 分类:这意味着将数据分类和归类为各个子部门,例如文章可以归类为博客,新闻,文章,研究论文和其他类别。
- 缺少频繁的项目集:此处Mahout会检查哪些对象可能同时出现并提出建议(如果缺少)。例如,通常将手机和保护套放在一起。因此,如果您搜索手机,它也会为您推荐外壳和保护套。
Mahout提供了一个命令行来调用各种算法。 它具有一组预定义的库,其中已经包含针对不同用例的不同内置算法。
APACHE SPARK

- Apache Spark是用于分布式计算环境中的实时数据分析的框架。
- Spark是用Scala编写的,最初是在加利福尼亚大学伯克利分校开发的。
- 它执行内存中计算,以提高Map-Reduce上的数据处理速度。
- 通过利用内存计算和其他优化,对于大规模数据处理,它的速度比Hadoop快100倍。 因此,它比Map-Reduce需要更高的处理能力。
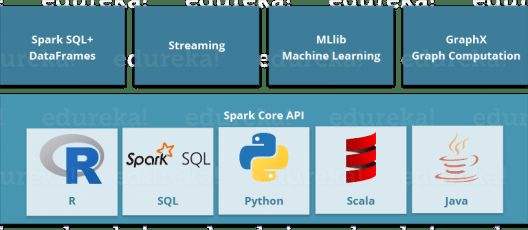
如您所见,Spark附带了高级库,包括对R,SQL,Python,Scala,Java等的支持。这些标准库增加了复杂工作流程中的无缝集成。除此之外,它还允许各种服务集与其集成,例如MLlib,GraphX,SQL +数据框架,流服务等,以增强其功能。
这是每个人心中很普遍的问题:
“ Apache Spark:Apache Hadoop的杀手还是救星?” – O'Reily
答案–这不是苹果与苹果的比较。Apache Spark最适合实时处理,而Hadoop旨在存储非结构化数据并对其执行批处理。当我们结合使用Apache Spark的能力(即高处理速度,高级分析和多重集成支持)与Hadoop在商品硬件上的低成本操作时,它可以提供最佳结果。
牛逼帽子就是为什么,星火和Hadoop一起被许多公司进行处理和分析他们的大数据存储在HDFS中使用的原因。
APACHE HBASE

- HBase是一个开源的非关系分布式数据库。换句话说,它是一个NoSQL数据库。
- 它支持所有类型的数据,这就是为什么它能够处理Hadoop生态系统中的任何事物。
- 它以Google的BigTable建模为基础,BigTable是旨在应对大型数据集的分布式存储系统。
- HBase设计为在HDFS之上运行,并提供类似BigTable的功能。
- 它为我们提供了一种容错的方式来存储稀疏数据,这在大多数大数据用例中都很常见。
- HBase用Java编写,而HBase应用程序可以用REST,Avro和Thrift API编写。
为了更好地理解,让我们举个例子。 您有数十亿客户的电子邮件,您需要找出在他们的电子邮件中使用投诉一词的客户数量。 该请求需要快速处理(即实时)。 因此,这里我们在处理大量数据的同时检索少量数据。 为了解决这类问题,设计了HBase。
APACHE钻头

顾名思义,Apache Drill用于钻取任何类型的数据。这是一个开放源代码应用程序,可与分布式环境一起使用,以分析大型数据集。
- 它是Google Dremel的副本。
- 它支持各种NoSQL数据库和文件系统,这是Drill的强大功能。例如:Azure Blob存储,Google Cloud Storage,HBase,MongoDB,MapR-DB HDFS,MapR-FS,Amazon S3,Swift,NAS和本地文件。
因此,基本上,Apache Drill的主要目的是提供可伸缩性,以便我们可以高效地处理PB和EB的数据(或者您可以在几分钟之内完成)。
- Apache Drill的主要功能在于仅使用一个查询就可以组合各种数据存储。
- Apache Drill基本上遵循ANSI SQL。
- 它具有强大的可伸缩性因素,可支持数百万个用户并在大规模数据上满足他们的查询请求。
阿帕奇动物园

- Apache Zookeeper是任何Hadoop作业的协调者,该作业包括Hadoop生态系统中各种服务的组合。
- Apache Zookeeper在分布式环境中与各种服务进行协调。
在使用Zookeeper之前,在Hadoop生态系统中的不同服务之间进行协调非常困难且耗时。 先前的服务在同步数据时在交互方面存在很多问题,例如通用配置。 即使配置了服务,服务配置的更改也会使其变得复杂且难以处理。 分组和命名也是一个耗时的因素。
由于上述问题,引入了Zookeeper。通过执行同步,配置维护,分组和命名,可以节省大量时间 。
尽管它是一项简单的服务,但可用于构建功能强大的解决方案。
大数据培训
大数据HADOOP认证培训
大数据Hadoop认证培训
评论使用PYSPARK进行PYTHON SPARK认证培训
使用PySpark进行Python Spark认证培训
评论APACHE SPARK和SCALA认证培训
Apache Spark和Scala认证培训
评论SPLUNK培训和认证-高级用户和管理员
Splunk培训和认证-高级用户和管理员
评论APACHE KAFKA认证培训
Apache Kafka认证培训
评论HADOOP管理认证培训
Hadoop管理认证培训
评论ELK STACK培训和认证
ELK Stack培训和认证
评论全面的HIVE认证培训
全面的Hive认证培训
评论APACHE STORM认证培训
Apache Storm认证培训
评论Rackspace,Yahoo,eBay等大公司在许多用例中都使用此服务,因此,您可以对Zookeeper的重要性有所了解。
APACHE OOZIE

将Apache Oozie视为Hadoop生态系统中的时钟和警报服务。对于Apache作业,Oozie就像调度程序一样。它调度Hadoop作业并将其绑定为一项逻辑工作。
Oozie工作有两种:
- Oozie工作流程:这些是要执行的顺序动作集。您可以将其视为接力赛。每个运动员都在等待最后一个运动员完成比赛的地方。
- Oozie协调器:这些是Oozie作业,这些作业在数据可用时触发。认为这是我们体内的反应刺激系统。Oozie协调员以与我们对外部刺激做出响应的方式相同,对数据的可用性做出响应,其他情况则取决于其他情况。
锦缎

摄取数据是我们Hadoop生态系统的重要组成部分。
- Flume是一项服务,可帮助将非结构化和半结构化数据提取到HDFS中。
- 它为我们提供了可靠且分布式的解决方案,可帮助我们收集,汇总和移动大量数据集。
- 它可以帮助我们从HDFS中从网络流量,社交媒体,电子邮件,日志文件等各种来源中获取在线流数据。
现在,让我们从下图了解Flume的体系结构:
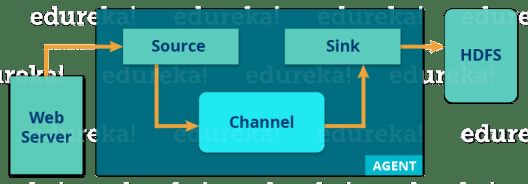
有一个Flume代理,可将流数据从各种数据源提取到HDFS。从图中可以很容易地理解Web服务器指示数据源。Twitter是流数据的著名来源之一。
槽剂具有3个成分:源,接收器和通道。
- 源:它从传入的流线中接收数据并将数据存储在通道中。
- 通道: 充当本地存储或主存储。通道是HDFS中数据源和永久数据之间的临时存储。
- 接收器:然后,我们的最后一个组件(即接收器)从通道收集数据,并将数据永久提交或写入HDFS中。
APACHE SQOOP

现在,让我们谈谈另一个数据摄取服务,即Sqoop。Flume和Sqoop之间的主要区别在于:
- Flume仅将非结构化数据或半结构化数据摄取到HDFS中。
- 而Sqoop可以从RDBMS或企业数据仓库向HDFS导入和导出结构化数据,反之亦然。
让我们使用下图了解Sqoop的工作方式:

当我们提交Sqoop命令时,我们的主要任务被分为子任务,这些子任务由内部的各个Map Task处理。Map Task是子任务,它将部分数据导入Hadoop生态系统。总的来说,所有Map任务都会导入整个数据。

导出也以类似的方式工作。
当我们提交作业时,它被映射到Map Tasks中,该任务从HDFS中获取数据块。这些块被导出到结构化数据目的地。结合所有这些导出的数据块,我们将在目的地接收整个数据,在大多数情况下,该数据是RDBMS(MYSQL / Oracle / SQL Server)。
APACHE太阳能和润滑油


Apache Solr和Apache Lucene是用于在Hadoop生态系统中进行搜索和索引的两个服务。
- Apache Lucene基于Java,它也有助于拼写检查。
- 如果说Apache Lucene是引擎,那么Apache Solr就是围绕它建造的汽车。Solr是围绕Lucene构建的完整应用程序。
- 它使用Lucene Java搜索库作为搜索和完整索引的核心。
阿帕切·安巴里(APACHE AMBARI)

Ambari是一个Apache软件基金会项目,旨在使Hadoop生态系统更易于管理。

大数据Hadoop认证培训
平日/周末批次查看批次详细信息它包括用于置备,管理和监视 Apache Hadoop集群的软件。
Ambari提供:
- Hadoop集群配置:
- 它为我们提供了在多个主机上安装Hadoop服务的分步过程。
- 它还处理集群上Hadoop服务的配置。
- Hadoop集群管理:
- 它提供了用于在整个集群中启动,停止和重新配置Hadoop服务的中央管理服务。
- Hadoop集群监控:
- 为了监视健康和状态,Ambari为我们提供了一个仪表板。
- 该黄色预警框架是一个提醒服务,通知用户,只要需要注意。例如,如果节点出现故障或节点上的磁盘空间不足等。
最后,我想提醒您重要的三件事:
- Hadoop生态系统的成功归功于整个开发人员社区,Facebook,Google,Yahoo,加利福尼亚大学(伯克利)等许多大公司都为提高Hadoop的功能做出了自己的贡献。
- 在Hadoop生态系统内部,有关一个或两个工具(Hadoop组件)的知识将无助于构建解决方案。您需要学习一组Hadoop组件,这些组件可以一起构建一个解决方案。
- 根据用例,我们可以从Hadoop生态系统中选择一组服务,并为组织创建量身定制的解决方案。
我希望这个博客能为您提供更多信息并为您增值。如果您有兴趣了解更多信息,可以阅读此案例研究,该案例告诉您 医疗保健中如何使用大数据以及Hadoop如何革新医疗保健分析。
在我们的Hadoop教程系列的下一个博客中,我们介绍了HDFS (Hadoop分布式文件系统),这是我在此Hadoop Ecosystem博客中讨论的第一个组件。
现在您已经了解了Hadoop生态系统,请查看Edureka 的 Hadoop培训 ,Edureka是一家受信任的在线学习公司,其网络遍布全球,共有250,000多名满意的学习者。Edureka大数据Hadoop认证培训课程使用零售,社交媒体,航空,旅游,金融领域的实时用例,帮助学习者成为HDFS,Yarn,MapReduce,Pig,Hive,HBase,Oozie,Flume和Sqoop的专家。
有问题要问我们吗?请在评论部分中提及它,我们将尽快与您联系。