哔哩哔哩用户数据采集及数据分析
就简单的采集几万个练一下手,代码大家看着改吧
先上代码
import requests
import time
from pymongo import MongoClient
import random
import json
import urllib3
from multiprocessing.dummy import Pool
ua = ['Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10',
'Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13',
'Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+',
'Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0',
'Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)',
'UCWEB7.0.2.37/28/999',
'NOKIA5700/ UCWEB7.0.2.37/28/999',
'Openwave/ UCWEB7.0.2.37/28/999',
'Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Androdi; Linux armv7l; rv:5.0) Gecko/ Firefox/5.0 fennec/5.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Android 2.3.4; Linux; Opera mobi/adr-1107051709; U; zh-cn) Presto/2.8.149 Version/11.10',
'UCWEB7.0.2.37/28/999',
'NOKIA5700/ UCWEB7.0.2.37/28/999',
'Openwave/ UCWEB7.0.2.37/28/999',
'Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999', ]
start = time.clock()
urls = []
with open(r'D:/password.txt', 'r') as f:
for i in f.readlines():
num = i.strip()
url = 'https://api.bilibili.com/x/space/acc/info?mid={}&jsonp=jsonp'.format(num)
urls.append(url)
random.shuffle(urls)
def get_info(url):
remeber = requests.session()
get_seesion = remeber.get('https://space.bilibili.com/215079380?spm_id_from=333.788.b_636f6d6d656e74.43')
try:
HEADERS = {'User-Agent': random.choice(ua)}
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
info = remeber.get(url, headers=HEADERS, verify=False).content.decode()
source = json.loads(info)
data = source["data"]
dic = {'name': data['name'], 'sex': data['sex'], 'birthday': data['birthday']}
print(dic)
print('此用户信息打印完毕')
collenction.insert_one(dic)
time.sleep(5)
except:
print("此链接无信息"+url)
time.sleep(2)
client = MongoClient()
database = client['bilibili']
collenction = database['spider']
pool = Pool(20)
result = pool.map(get_info, urls)
end = time.clock()
print('完成所用的时间为: {}'.format(end-start))
代码讲解
主要的思路是:
1:先进入到信息所在的页面,在页面中通过network 来查看该页面的requests 形式,已经返回的信息。在这个查看中,意外的返现信息业的requests url 是一个比较有规矩的网址,可以通过拼接完成的。(本来是想用selenium 来操作的,但是效率太低,而且xpath 一直有问题 找不到对应的元素)
2:确定了requests 之后 发现可以通过get 信息得到,那么就更加简单的,直接requests.get 来实现,并且返回的是一个json 内容,因此对返回的内容需要json.loads 编程python 方便处理的字典
3:我这里的password.txt 是通过第三方库生成,7位数数字,用来拼接requests_url , 哔哩哔哩上面应该有6,7,8位的id 都有
start = time.clock()
words = '123456789'
r = its.product(words, repeat=7)
dict = open(r'D:/password.txt', 'a')
for i in r:
dict.write(''.join(i))
dict.write(''.join('\n'))
print(i)
dict.close()
print('密码已经生成完毕')
end = time.clock()
print('所用时间为:{}'.format(end-start))
这个代码本来是用来暴力破解wifi 用的 现在被我拿来干这个。简单的意思是 its.product (参数1,参数2),参数2 是需要生成的位数,这里是7位数,参数1 是基础对象,这个方法就是针对这个1-9位数,穷尽其所有7位数组合,那就是9的7次方个数字。
4:生成好之后,就简单了,对只写拼接的数字进行遍历,每一个都请求过去,就可以了。需要注意的是,因为访问量大,所以一定要更换UA ,我把更换UA 部分放在了 循环里面,这样每次请求的时候 都可以更换。至于要不要用到requests.session 这个方法, 我个人觉得要用,这样的话 就能保持在同一个会话,但是同一个cookies 和不同的UA 会怎么样,百度没有查到,到至少这次 我没有被这个网站封IP 这样的操作应该是好用的。
5:最后记得导入到数据库就行了, 我用的mongodb ,挺方便的。
6:我用了多进程的方式进行,其实这里进程池设置为4就可以了,我的电脑就是4核的而已, 20没有意义,这个也是后面差了资料,了解了进程的运行原理之后才知道的。所有学代码,计算机的硬件知识,底层运行知识还是多学学的好。
7:最后找到了2。5W 的数据, 处理了一下, 做了饼图
import csv
import matplotlib.pyplot as plt
column_new = []
with open(r'D:\bilibli.csv', 'r', errors='ignore') as f:
reader = csv.reader(f)
column = [row[2] for row in reader]
del column[0]
#b = ['1月1日', '']
#for i in column:
#if i not in b:
#column_new.append(i)
#month = []
#for i in column_new:
#month.append(i.split('月')[0])
#label = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
#sizes = [month.count('1'), month.count('2'), month.count('3'), month.count('4'), month.count('5'), month.count('6'), month.count('7'),
#month.count('8'), month.count('9'), month.count('10'), month.count('11'), month.count('12')]
#plt.axes(aspect='1')
#plt.pie(sizes, labels=label, shadow=True, autopct='%.0f%%')
#plt.show()
print(column)
b = ['保密', '']
sex_column = []
for i in column:
if i not in b:
sex_column.append(i)
print(sex_column)
label = ['Boy', 'Girl']
sizes = [sex_column.count('男'), sex_column.count('女')]
colors = ['lightblue', 'lightyellow']
explode = [0.1, 0.0]
plt.axis(aspect='1')
plt.pie(sizes, labels=label, explode=explode, colors=colors, shadow=True, autopct='%1.1f%%')
plt.show()
前面先剔除掉 数据中 一些空,设置为保密的,出厂设置为1月1日的内容,然后再做饼图,很简单。就不讲解了。
最后图为

这个是采集到数据用户生日月份图,title 都懒的加了,因为图有点丑
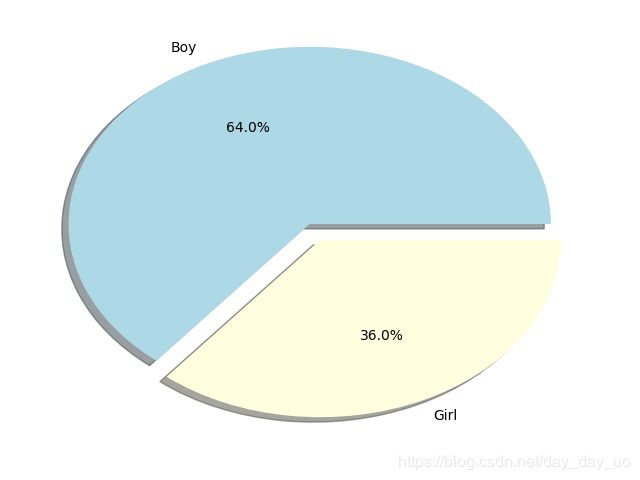
这个是男女比例图,竟然男的多。 当然这个数据量样本太少了。没有参考意义。
有时间的同学,可以把5,6,7,8位的所有用户都采集一下,然后再做数据分析,比较好。