Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就绪,挂起,运行) ,***协程概念,yield模拟并发(有缺陷),Greenlet模块(手动切换),Gevent(协程并发)
一丶同步,异步
同步:
所谓同步就是一个任务需要依赖另一个任务时,只有被依赖任务执行完毕之后,依赖的任务才会完成.这是可靠的任务序列.要么都成功,要么失败,两个任务的状态可以保持一致.
异步:
所谓异步不需要等待被依赖的任务完成,只是通知依赖的任务要完成什么工作.依赖的任务也立即执行,只要自己完成了整个任务就算完成了. 至于被依赖的任务是否完成,依赖它的任务无法确定,是不可靠的任务序列
### 同步和异步
## 比如我去银行办理业务,可能会有两种方式:
# 第一种 :选择排队等候;
# 第二种 :选择取一个小纸条上面有我的号码,等到排到我这一号时由柜台的人通知我轮到我去办理业务了;
# 第一种:前者(排队等候)就是同步等待消息通知,也就是我要一直在等待银行办理业务情况;
# 第二种:后者(等待别人通知)就是异步等待消息通知。在异步消息处理中,等待消息通知者(在这个例子中就是等待办理业务的人)往往注册一个回调机制,在所等待的事件被触发时由触发机制(在这里是柜台的人)通过某种机制(在这里是写在小纸条上的号码,喊号)找到等待该事件的人。二丶阻塞,非阻塞,
阻塞和非阻塞两个概念与程序(也就是执行程序的'线程')等待消息通知时的状态相关
阻塞:
在程序中,阻塞代表程序'卡'在某处,必须等待这处执行完毕才能继续执行.通常的阻塞大多数是IO阻塞
比如:银行排队取钱是一条流水线,现在负责取钱的服务人员饿了,他必须吃饭(阻塞). 只有吃完饭才能继续回来服务你.此时你就必须等待他,否则你将无法取钱.对于程序而言,就卡在了此处.
非阻塞:
非阻塞就是没有IO阻塞,线程在执行任务时没有遇到IO阻塞.
比如:你去银行取钱,在排队'等候'时什么事情都没有发生. 强调在执行的过程
同步阻塞:
效率最低.你排着队取钱,服务人员吃饭去了(阻塞了),此时你只能等待,否则不能取钱.这就是同步+阻塞
异步阻塞:
在银行等待办理业务的人,采用异步方式. 但是他不能离开银行
异步操作是可以被阻塞住的,只不过它不是在处理消息时阻塞,而是在等待消息通知时被阻塞。
同步非阻塞:
实际上是效率低下的。
想象一下你一边打着电话一边还需要抬头看到底队伍排到你了没有,如果把打电话和观察排队的位置看成是程序的两个操作的话,这个程序需要在这两种不同的行为之间来回的切换,效率可想而知是低下的。
异步非阻塞:
效率更高
因为打电话是你(等待者)的事情,而通知你则是柜台(消息触发机制)的事情,程序没有在两种不同的操作中来回切换。
比如说,这个人突然发觉自己烟瘾犯了,需要出去抽根烟,于是他告诉大堂经理说,排到我这个号码的时候麻烦到外面通知我一下,那么他就没有被阻塞在这个等待的操作上面,自然这个就是异步+非阻塞的方式了。
很多人会把同步和阻塞混淆,是因为很多时候同步操作会以阻塞的形式表现出来,同样的,很多人也会把异步和非阻塞混淆,因为异步操作一般都不会在真正的IO操作处被阻塞。
三丶异步+回调机制
提高效率版:
####### 并发爬取 , 并发处理爬取结果
# 缺点: 1.增强了耦合性,
# 2.开启进程耗费资源
# 优点: 1. 提高处理效率
from concurrent.futures import ProcessPoolExecutor
import time
import random
import os
import requests
def get_html(url):
response=requests.get(url)
print(f'{os.getpid()} 正在爬取网页~~~')
if response.status_code==200:
parser_html(response.text)
def parser_html(obj):
print(f'总字符长度:{len(obj.result()) }')
if __name__ == '__main__':
url_list = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
pool=ProcessPoolExecutor(4) # 开启了一个进程池 有4个进程资源
for url in url_list:
obj=pool.submit(get_html,url) # 异步的开启了 10个任务,4个进程并行(并发)执行.
pool.shutdown(wait=True) # 必须等待所有的子进程任务执行完毕降低耦合版本:
# 并发爬取, 串行解析结果
########### 回调函数 + 异步
# 1. 降低了耦合性, 由回调函数 去通知执行下一个任务(造成这个任务会经历串行)
# 2. 处理爬取结果时是串行处理,影响效率
import requests
from concurrent.futures import ProcessPoolExecutor
from multiprocessing import Process
import time
import random
import os
def get(url):
response = requests.get(url)
print(f'{os.getpid()} 正在爬取:{url}')
# time.sleep(random.randint(1,3))
if response.status_code == 200:
return response.text
def parse(obj):
'''
对爬取回来的字符串的分析
简单用len模拟一下.
:param text:
:return:
'''
time.sleep(1)
### obj.result() 取得结果
print(f'{os.getpid()} 分析结果:{len(obj.result())}')
if __name__ == '__main__':
url_list = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
start_time = time.time()
pool = ProcessPoolExecutor(4)
for url in url_list:
obj = pool.submit(get, url)
obj.add_done_callback(parse) # 增加一个回调函数
# 现在的进程完成的还是网络爬取的任务,拿到了返回值之后,结果丢给回调函数add_done_callback,
# 回调函数帮助你分析结果
# 进程继续完成下一个任务.
pool.shutdown(wait=True)
print(f'主: {time.time() - start_time}')四丶线程队列
使用 queue 模块
先进先出:FIFO
Queue
# -*-coding:utf-8-*-
# Author:Ds
import queue
q = queue.Queue(3) # 先进先出队列
q.put(1)
q.put(2)
q.put('123')
# q.put(666) # 阻塞 卡住了
# q.put(timeout=1) # 超时1秒报错 queue.Full
# q.put(1,block=False) # 非阻塞,直接报错 queue.Full
print(q.get())
print(q.get())
print(q.get())
# print(q.get()) #阻塞 卡住
# print(q.get(timeout=1)) #超时1秒报错 queue.Empty
print(q.get(block=False)) #非阻塞,直接报错queue.Empty先进后出(后进先出):LIFO
LifoQueue
# -*-coding:utf-8-*-
# Author:Ds
import queue
q = queue.LifoQueue(3) #后进先出队列 (栈)
q.put(1)
q.put(2)
q.put('123')
# q.put(666) # 阻塞 卡住了
## q.put(timeout=1) # 超时1秒报错 queue.Full
### q.put(1,block=False) # 非阻塞,直接报错 queue.Full
print(q.get())
print(q.get())
print(q.get())
# print(q.get()) #阻塞 卡住
## print(q.get(timeout=1)) #超时1秒报错 queue.Empty
### print(q.get(block=False)) #非阻塞,直接报错queue.Empty
# 使用列表数据结构模拟栈
li=[]
li.append(1) # 后进 添加元素到列表末尾
li.pop() # 先出 移除列表末尾元素优先级队列:
PriorityQueue
# -*-coding:utf-8-*-
# Author:Ds
import queue
q = queue.PriorityQueue(3) # 优先级队列
# 放入元组类型()数据, 第一个参数表示优先级别,第二个参数是真实数据
# 数字越低表示优先级越高
q.put((10, '垃圾消息'))
q.put((-9, '紧急消息'))
q.put((3, '一般消息'))
# q.put((3, '我被卡主了 ')) # 卡主了
# q.put((3, '我被卡主了 '),timeout=1) # 超时报错: queue.Full
q.put((3, '我被卡主了 '),block=False) # 不阻塞: queue.Full
print(q.get())
print(q.get())
print(q.get())
print(q.get()) #阻塞 卡住
print(q.get(timeout=1)) #超时1秒报错 queue.Empty
print(q.get(block=False)) #非阻塞,直接报错queue.Empty五丶事件Event
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
方法:
event.isSet():返回event的状态值;
event.wait():如果 event.isSet()==False将阻塞线程;
event.set():设置event的状态值为True,所有阻塞池的线程激活进入就绪状态,等待操作系统调度;
event.clear():恢复event的状态值为False
import time
from threading import Thread
from threading import current_thread
from threading import Event
event = Event() # 默认是False
def task():
print(f'{current_thread().name} 检测服务器是否正常开启....')
time.sleep(3)
event.set() # 改成了True
def task1():
print(f'{current_thread().name} 正在尝试连接服务器')
# event.wait() # 轮询检测event是否为True,当其为True,继续下一行代码. 阻塞.
event.wait(1)
# 设置超时时间,如果1s中以内,event改成True,代码继续执行.
# 设置超时时间,如果超过1s中,event没做改变,代码继续执行.
print(f'{current_thread().name} 连接成功')
if __name__ == '__main__':
t1 = Thread(target=task1,)
t2 = Thread(target=task1,)
t3 = Thread(target=task1,)
t = Thread(target=task)
t.start()
t1.start()
t2.start()
t3.start()红绿灯Event事件模型:
# _*_coding:utf-8_*_
# Author :Ds
# CreateTime 2019/5/30 17:54
import threading ,time
event=threading.Event() # 声明一个event全局变量
def lighter():
count=0 #计数
event.set() #设置有标志
while True: #循环
if count > 5 and count<10:# 红灯5秒
event.clear()# 清空标志位
print("\033[41;1mred light is on...\033[0m")
elif count>10: # 绿灯5秒
event.set()#变绿灯
count=0 #清空count
else:
print('\033[42;1mgreen light is on...\033[0m')
time.sleep(1)
count+=1
def car(name):
while True:
if event.is_set(): #is_set 判断设置了标志位没有
print('[%s] running ...'%name)
time.sleep(1)
else:
print(' [%s] see red light waiting '%name)
event.wait()
print('\033[43;lm [%s] green light is on ,start going ..\033[0m'%name)
light=threading.Thread(target=lighter,)
car1=threading.Thread(target=car,args=('特斯拉',))
car2=threading.Thread(target=car,args=('奔驰',))
light.start()
car1.start()
car2.start()六丶协程
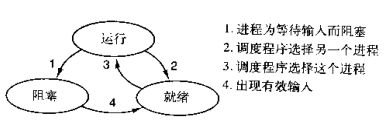
进程是资源分配的最小单位,线程是CPU调度的最小单
并发的本质:切换+保存状态
线程也具有三个状态:
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长
ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态
yield模拟并发:
1. yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级
2. send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换
一:其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。为此我们可以基于yield来验证。yield本身就是一种在单线程下可以保存任务运行状态的方法,我们来简单复习一下:
'''
1、协程:
单线程实现并发
在应用程序里控制多个任务的切换+保存状态
优点:
应用程序级别速度要远远高于操作系统的切换
缺点:
多个任务一旦有一个阻塞没有切,整个线程都阻塞在原地
该线程内的其他的任务都不能执行了
一旦引入协程,就需要检测单线程下所有的IO行为,
实现遇到IO就切换,少一个都不行,以为一旦一个任务阻塞了,整个线程就阻塞了,
其他的任务即便是可以计算,但是也无法运行了
2、协程序的目的:
想要在单线程下实现并发
并发指的是多个任务看起来是同时运行的
并发=切换+保存状态
'''
#串行执行
import time
def func1():
for i in range(10000000):
i+1
def func2():
for i in range(10000000):
i+1
start = time.time()
func1()
func2()
stop = time.time()
print(stop - start)
#基于yield并发执行
import time
def func1():
while True:
yield
def func2():
g=func1()
for i in range(10000000):
i+1
next(g)
start=time.time()
func2()
stop=time.time()
print(stop-start)
# 单纯地切换反而会降低运行效率二:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
import time
def func1():
while True:
print('func1')
yield
def func2():
g=func1()
for i in range(10000000):
i+1
next(g)
time.sleep(3)
print('func2')
start=time.time()
func2()
stop=time.time()
print(stop-start)
yield不能检测IO,实现遇到IO自动切换协程介绍:
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。
一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
需要强调的是:
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
#2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)优点如下:
1.协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
2.单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
1.协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
2.协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
总结协程特点:
1.必须在只有一个单线程里实现并发
2.修改共享数据不需加锁
3.用户程序里自己保存多个控制流的上下文栈
4.附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
Greenlet模块:手动模拟切换
安装 :pip3 install greenlet
手动实现切换
from greenlet import greenlet
def eat(name):
print('%s eat 1' %name)
g2.switch('egon')
print('%s eat 2' %name)
g2.switch()
def play(name):
print('%s play 1' %name)
g1.switch()
print('%s play 2' %name)
g1=greenlet(eat)
g2=greenlet(play)
g1.switch('egon') #可以在第一次switch时传入参数,以后都不需要效率对比:
greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。
### 串行执行计算密集型~~ 11.37856674194336
import time
def f1():
res=1
for i in range(100000000):
res+=i
def f2():
res=1
for i in range(100000000):
res*=i
start_time=time.time()
f1()
f2()
print(f'runing time {time.time()-start_time}') # runing time 11.37856674194336
### 切换执行计算密集型~~ runing time 60.24287223815918
from greenlet import greenlet
import time
def f1():
res=1
for i in range(100000000):
res+=i
g2.switch()
def f2():
res=1
for i in range(100000000):
res*=i
g1.switch()
start_time=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
print(f'runing time {time.time()-start_time}') # runing time 60.24287223815918Gevent模块:
安装:pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度
### 用法
g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的
g2=gevent.spawn(func2)
g1.join() #等待g1结束
g2.join() #等待g2结束
#或者上述两步合作一步:gevent.joinall([g1,g2])
g1.value#拿到func1的返回值 遇到IO阻塞时会自动切换任务
import gevent
def eat(name):
print('%s eat 1' %name)
gevent.sleep(2)
print('%s eat 2' %name)
def play(name):
print('%s play 1' %name)
gevent.sleep(1)
print('%s play 2' %name)
g1=gevent.spawn(eat,'egon')
g2=gevent.spawn(play,name='egon')
g1.join()
g2.join()
#或者gevent.joinall([g1,g2])
print('主')'打补丁:monkey'
# from gevent import monkey
# monkey.patch_all() 必须放到被打补丁者的前面,
import threading
from gevent import monkey
monkey.patch_all() # 打补丁,自动切换
import gevent
import time
def eat():
print(threading.current_thread().getName()) # 虚拟线程 DummyThread-n
print('eat food 1')
time.sleep(2)
print('eat food 2')
def play():
print(threading.current_thread().getName()) # 虚拟线程 DummyThread-n
print('play 1')
time.sleep(1)
print('play 2')
g1=gevent.spawn(eat)
g2=gevent.spawn(play)
gevent.joinall([g1,g2]) # 执行g1 g2
print(threading.current_thread().getName()) # MainThread 主线程
print('主')协程应用:爬虫:
from gevent import monkey;monkey.patch_all()
import gevent
import requests
import time
def get_page(url):
print('GET: %s' %url)
response=requests.get(url)
if response.status_code == 200:
print('%d bytes received from %s' %(len(response.text),url))
start_time=time.time()
gevent.joinall([
gevent.spawn(get_page,'https://www.python.org/'),
gevent.spawn(get_page,'https://www.yahoo.com/'),
gevent.spawn(get_page,'https://github.com/'),
])
stop_time=time.time()
print('run time is %s' %(stop_time-start_time)) # 使用协程爬取,计算爬取的时间