最具潜力的编程语言GO有新书啦!
互联网时代的来临,改变甚至颠覆了很多东西。从前,一台主机就能搞定一切;而在互联网时代,后台由大量分布式系统构成,任何单个后台服务器节点的故障都不会影响整个系统的正常运行。以七牛云、阿里云和腾讯云为代表的云厂商的出现和崛起,标志着云时代的到来。在云时代,掌握分布式编程已经成为软件工程师的基本技能,而基于Go语言构建的Docker、Kubernetes等系统正是将云时代推向顶峰的关键力量。
今天,Go语言已历经十年,最初的追随者也已经逐渐成长为Go语言资深用户。随着资深用户的不断积累,Go语言相关教程随之增加,在内容层面主要涵盖Go语言基础编程、Web编程、并发编程和内部源码剖析等诸多领域。
七月,新书《GO语言高级编程》推荐给小伙伴们!!
《GO语言高级编程》

作者:柴树杉 曹春晖
- 一本能满足Gopher好奇心的Go语言进阶读物
- 汇集了作者多年来学习和使用Go语言的经验
- 更倾向于描述实现细节,极大地满足开发者的探索欲望
本书作者是国内第一批Go语言实践者和Go语言代码贡献者,创建了Go语言中国讨论组,并组织了早期Go语言相关中文文档的翻译工作。
作者从2011年开始分享Go语言和C/C++语言混合编程技术。本书汇集了作者多年来学习和使用Go语言的经验,内容涵盖CGO特性、Go汇编语言、RPC实现、Protobuf插件实现、Web框架实现、分布式系统等高阶主题。其中,CGO特性实现了Go语言对C语言和C++语言混合编程的支持,使Go语言可以无缝继承C/C++世界数十年来积累的巨大软件资产。Go汇编语言更是提供了直接调用底层机器指令的方法,让我们可以最大限度地提升程序中热点代码的性能。
本书适合有一定Go语言经验,并想深入了解Go语言各种高级用法的开发人员。对于Go语言新手,建议在阅读本书前先阅读一些基础Go语言编程图书。
目录
- 内容提要
- 序一
- 序二
- 前言
- 致谢
- 资源与支持
- 第1章 语言基础
- 第2章 CGO编程
- 第3章 Go汇编语言
- 第4章 RPC和Protobuf
- 第5章 Go和Web
- 第6章 分布式系统
- 附录A 使用Go语言常遇到的问题
- 附录B 有趣的代码片段
样章试读:第1章 语言基础(截选)
我不知道,你过去10年为什么不快乐。但相信我,抛掉过去的沉重,使用Go语言,体会最初的快乐!
——469856321
搬砖民工也会建成自己的“罗马帝国”。
——小张
本章首先简要介绍Go语言的发展历史,并较详细地分析“Hello, World”程序在各个祖先语言中的演化过程。然后,对以数组、字符串和切片为代表的基础结构,以函数、方法和接口体现的面向过程和鸭子对象的编程,以及Go语言特有的并发编程模型和错误处理哲学做简单介绍。最后,针对macOS、Windows、Linux几个主流的开发平台,推荐几种较友好的Go语言编辑器和集成开发环境,因为好的工具可以极大地提高我们的效率。
1.1 Go语言创世纪
Go语言最初由谷歌公司的Robert Griesemer、Ken Thompson和Rob Pike这3位技术大咖于2007年开始设计发明,设计新语言的最初动力来自对超级复杂的C++11特性的吹捧报告的鄙视,最终的目标是设计网络和多核时代的C语言。到2008年中期,在语言的大部分特性设计已经完成并开始着手实现编译器和运行时,Russ Cox作为主力开发者加入。到2010年,Go语言已经逐步趋于稳定,并在9月正式发布并开源了代码。
Go语言很多时候被描述为“类C语言”,或者“21世纪的C语言”。从各种角度看,Go语言确实是从C语言继承了相似的表达式语法、控制流结构、基础数据类型、调用参数传值、指针等诸多编程思想,并彻底继承和发扬了C语言简单直接的暴力编程哲学等。图1-1给出的是The Go Programming Language中给出的Go语言的基因图谱,我们可以从中看到有哪些编程语言对Go语言产生了影响。
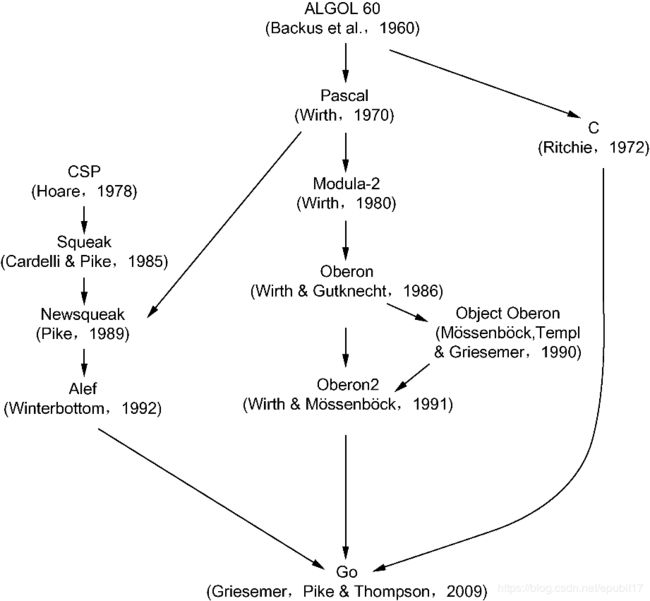
图1-1 Go语言基因图谱
首先看基因图谱的左边一支。可以明确看出Go语言的并发特性是由贝尔实验室的Hoare于1978年发布的CSP理论演化而来。其后,CSP并发模型在Squeak/Newsqueak和Alef等编程语言中逐步完善并走向实际应用,最终这些设计经验被消化并吸收到了Go语言中。业界比较熟悉的Erlang编程语言的并发编程模型也是CSP理论的另一种实现。
再看基因图谱的中间一支。中间一支主要包含了Go语言中面向对象和包特性的演化历程。Go语言中包和接口以及面向对象等特性则继承自Niklaus Wirth所设计的Pascal语言以及其后衍生的相关编程语言。其中包的概念、包的导入和声明等语法主要来自Modula-2编程语言,面向对象特性所提供的方法的声明语法等则来自Oberon编程语言。最终Go语言演化出了自己特有的支持鸭子面向对象模型的隐式接口等诸多特性。
最后是基因图谱的右边一支,这是对C语言的致敬。Go语言是对C语言最彻底的一次扬弃,不仅在语法上和C语言有着很多差异,最重要的是舍弃了C语言中灵活但是危险的指针运算。而且,Go语言还重新设计了C语言中部分不太合理运算符的优先级,并在很多细微的地方都做了必要的打磨和改变。当然,C语言中少即是多、简单直接的暴力编程哲学则被Go语言更彻底地发扬光大了(Go语言居然只有25个关键字,语言规范还不到50页)。
Go语言的其他特性零散地来自其他一些编程语言,例如,iota语法是从APL语言借鉴的,词法作用域与嵌套函数等特性来自Scheme语言(和其他很多编程语言)。Go语言中也有很多自己发明创新的设计。例如Go语言的切片为轻量级动态数组提供了有效的随机存取的性能,这可能会让人联想到链表的底层的共享机制。还有Go语言新发明的defer语句(Ken发明)也是神来之笔。
1.1.1 来自贝尔实验室特有基因
作为Go语言标志性的并发编程特性则来自贝尔实验室的Tony Hoare于1978年发表的鲜为外界所知的关于并发研究的基础文献:顺序通信进程(Communicating Sequential Processes,CSP)。在最初的CSP论文中,程序只是一组没有中间共享状态的并发运行的处理过程,它们之间使用通道进行通信和控制同步。Tony Hoare的CSP并发模型只是一个用于描述并发性基本概念的描述语言,它并不是一个可以编写可执行程序的通用编程语言。
CSP并发模型最经典的实际应用是来自爱立信公司发明的Erlang编程语言。不过在Erlang将CSP理论作为并发编程模型的同时,同样来自贝尔实验室的Rob Pike以及其同事也在不断尝试将CSP并发模型引入当时的新发明的编程语言中。他们第一次尝试引入CSP并发特性的编程语言叫Squeak(老鼠的叫声),是一个用于提供鼠标和键盘事件处理的编程语言,在这个语言中通道是静态创建的。然后是改进版的Newsqueak语言(新版老鼠的叫声),新提供了类似C语言语句和表达式的语法,还有类似Pascal语言的推导语法。Newsqueak是一个带垃圾回收机制的纯函数式语言,它再次针对键盘、鼠标和窗口事件管理。但是在Newsqueak语言中通道已经是动态创建的,通道属于第一类值,可以保存到变量中。然后是Alef编程语言(Alef也是C语言之父Ritchie比较喜爱的编程语言),Alef语言试图将Newsqueak语言改造为系统编程语言,但是因为缺少垃圾回收机制而导致并发编程很痛苦(这也是继承C语言手工管理内存的代价)。在Alef语言之后还有一个名为Limbo的编程语言(地狱的意思),这是一个运行在虚拟机中的脚本语言。Limbo语言是与Go语言最接近的祖先,它和Go语言有着最接近的语法。到设计Go语言时,Rob Pike在CSP并发编程模型的实践道路上已经积累了几十年的经验,关于Go语言并发编程的特性完全是信手拈来,新编程语言的到来也是水到渠成了。
图1-2展示了Go语言库早期代码库日志,可以看出最直接的演化历程(在Git中用git log --before={2008-03-03} --reverse命令查看)。
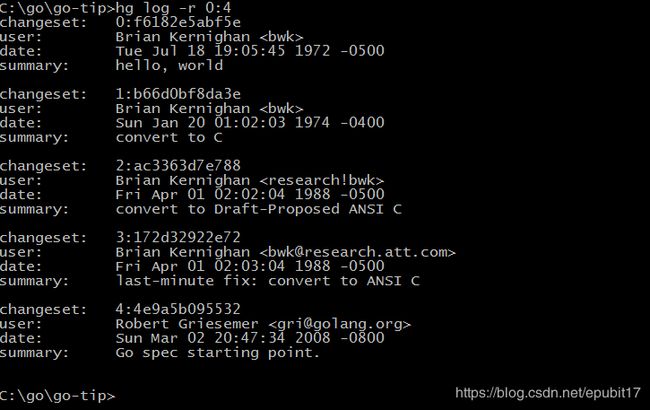
图1-2 Go语言开发日志
从早期提交日志中也可以看出,Go语言是从Ken Thompson发明的B语言、Dennis M. Ritchie发明的C语言逐步演化过来的,它首先是C语言家族的成员,因此很多人将Go语言称为21世纪的C语言。
图1-3给出的是Go语言中来自贝尔实验室特有并发编程基因的演化过程。

图1-3 Go语言并发演化历史
纵观整个贝尔实验室的编程语言的发展进程,从B语言、C语言、Newsqueak、Alef、Limbo语言一路走来,Go语言继承了来自贝尔实验室的半个世纪的软件设计基因,终于完成了C语言革新的使命。纵观这几年来的发展趋势,Go语言已经成为云计算、云存储时代最重要的基础编程语言。
1.1.2 你好,世界
按照惯例,介绍所有编程语言的第一个程序都是“Hello, World!”。虽然本书假设读者已经了解了Go语言,但是我们还是不想打破这个惯例(因为这个传统正是从Go语言的前辈C语言传承而来的)。下面的代码展示的Go语言程序输出的是中文“你好,世界!”。
package main
import "fmt"
func main() {
fmt.Println("你好, 世界!")
}
将以上代码保存到hello.go文件中。因为代码中有非ASCII的中文字符,我们需要将文件的编码显式指定为无BOM的UTF8编码格式(源文件采用UTF8编码是Go语言规范所要求的)。然后进入命令行并切换到hello.go文件所在的目录。目前我们可以将Go语言当作脚本语言,在命令行中直接输入go run hello.go来运行程序。如果一切正常的话,应该可以在命令行看到输出“你好, 世界!”的结果。
现在,让我们简单介绍一下程序。所有的Go程序都由最基本的函数和变量构成,函数和变量被组织到一个个单独的Go源文件中,这些源文件再按照作者的意图组织成合适的package,最终这些package有机地组成一个完整的Go语言程序。其中,函数用于包含一系列的语句(指明要执行的操作序列),以及执行操作时存放数据的变量。我们这个程序中函数的名字是main。虽然Go语言对函数的名字没有太多的限制,但是main包中的main()函数默认是每一个可执行程序的入口。而package则用于包装和组织相关的函数、变量和常量。在使用一个package之前,我们需要使用import语句导入包。例如,我们这个程序中导入了fmt包(fmt是format的缩写,表示格式化相关的包),然后我们才可以使用fmt包中的Println()函数。
而双引号包含的“你好, 世界!”则是Go语言的字符串面值常量。和C语言中的字符串不同,Go语言中的字符串内容是不可变更的。在以字符串作为参数传递给fmt.Println()函数时,字符串的内容并没有被复制——传递的仅是字符串的地址和长度(字符串的结构在reflect.StringHeader中定义)。在Go语言中,函数参数都是以复制的方式(不支持以引用的方式)传递(比较特殊的是,Go语言闭包函数对外部变量是以引用的方式使用的)。
1.2 “Hello, World”的革命
1.1节中简单介绍了Go语言的演化基因图谱,对其中来自贝尔实验室的特有并发编程基因做了重点介绍,最后引出了Go语言版的“Hello, World”程序。其实“Hello, World”程序是展示各种语言特性的最好的例子,是通向该语言的一个窗口。本节将沿着各个编程语言演化的时间轴(如图1-3所示),简单回顾一下“Hello, World”程序是如何逐步演化到目前的Go语言形式并最终完成它的使命的。
1.2.1 B语言——Ken Thompson, 1969
首先是B语言,B语言是“Go语言之父”——贝尔实验室的Ken Thompson早年间开发的一种通用的程序设计语言,设计目的是为了用于辅助UNIX系统的开发。但是由于B语言缺乏灵活的类型系统导致使用比较困难。后来,Ken Thompson的同事Dennis Ritchie以B语言为基础开发出了C语言,C语言提供了丰富的类型,极大地增强了语言的表达能力。到目前为止,C语言依然是世界上最常用的程序语言之一。而B语言自从被它取代之后,就只存在于各种文献之中,成为了历史。
目前见到的B语言版本的“Hello, World”,一般认为是来自Brian W. Kernighan编写的B语言入门教程(Go核心代码库中第一个提交者的名字正是Brian W. Kernighan),程序如下:
main() {
extrn a, b, c;
putchar(a); putchar(b); putchar(c);
putchar('!*n');
}
a 'hell';
b 'o, w';
c 'orld';
由于B语言缺乏灵活的数据类型,只能分别以全局变量a/b/c来定义要输出的内容,并且每个变量的长度必须对齐到4字节(有一种写汇编语言的感觉)。然后通过多次调用putchar()函数输出字符,最后的'!*n'表示输出一个换行的意思。
总体来说,B语言简单,功能也比较有限。
1.2.2 C语言——Dennis Ritchie,1972—1989
C语言是由Dennis Ritchie在B语言的基础上改进而来,它增加了丰富的数据类型,并最终实现了用它重写UNIX的伟大目标。C语言可以说是现代IT行业最重要的软件基石,目前主流的操作系统几乎全部是由C语言开发的,许多基础系统软件也是C语言开发的。C系家族的编程语言占据统治地位达几十年之久,半个多世纪以来依然充满活力。
在Brian W. Kernighan于1974年左右编写的C语言入门教程中,出现了第一个C语言版本的“Hello, World”程序。这给后来大部分编程语言教程都以“Hello, World”为第一个程序提供了惯例。第一个C语言版本的“Hello, World”程序如下:
main()
{
printf("hello, world");
}
关于这个程序,有几点需要说明:首先是main()函数因为没有明确返回值类型,所以默认返回int类型;其次printf()函数默认不需要导入函数声明即可以使用;最后main ()没有明确返回语句,但默认返回0。在这个程序出现时,C语言还远未标准化,我们看到的是早先的C语言语法:函数不用写返回值,函数参数也可以忽略,使用printf ()时不需要包含头文件等。
这个例子同样出现在了1978年出版的《C程序设计语言(第1版)》中,作者正是Brian W. Kernighan和Dennis M. Ritchie(简称K&R)。书中的“Hello, World”末尾增加了一个换行输出:
main()
{
printf("hello, world\n");
}
这个例子在字符串末尾增加了一个换行,C语言的换行\n比B语言的换行'!*n'看起来要简洁了一些。
在K&R的教程面世10年之后的1988年,《C程序设计语言(第2版)》终于出版了。此时ANSI C语言的标准化草案已经初步完成,但正式版本的文档尚未发布。不过书中的“Hello, World”程序根据新的规范增加了#include 头文件包含语句,用于包含printf()函数的声明(新的C89标准中,仅是针对printf()函数而言,依然可以不用声明函数而直接使用)。
#include
main()
{
printf("hello, world\n");
}
然后到了1989年,ANSI C语言第一个国际标准发布,一般被称为C89。C89是流行最广泛的一个C语言标准,目前依然被大量使用。《C程序设计语言》也出版了新版本,并针对新发布的C89规范建议,给main()函数的参数增加了void输入参数说明,表示没有输入参数的意思。
#include
main(void)
{
printf("hello, world\n");
}
至此,C语言本身的进化基本完成。后面的C92/C99/C11都只是针对一些语言细节做了完善。因为各种历史因素,C89依然是使用最广泛的标准。
1.2.3 Newsqueak——Rob Pike, 1989
Newsqueak是Rob Pike发明的老鼠语言的第二代,是他用于实践CSP并发编程模型的战场。Newsqueak是新的Squeak语言的意思,其中squeak是老鼠“吱吱吱”的叫声,也可以看作是类似鼠标点击的声音。Squeak是一个提供鼠标和键盘事件处理的编程语言,Squeak语言的通道是静态创建的。改进版的Newsqueak语言则提供了类似C语言语句和表达式的语法和类似Pascal语言的推导语法。Newsqueak是一个带自动垃圾回收机制的纯函数式语言,它再次针对键盘、鼠标和窗口事件管理。但是在Newsqueak语言中通道是动态创建的,属于第一类值,因此可以保存到变量中。
Newsqueak类似脚本语言,内置了一个print()函数,它的“Hello, World”程序看不出什么特色:
print("Hello,", "World", "\n");
从上面的程序中,除了猜测print()函数可以支持多个参数,我们很难看到Newsqueak语言相关的特性。由于Newsqueak语言和Go语言相关的特性主要是并发和通道,因此,我们这里通过一个并发版本的“素数筛”算法来略窥Newsqueak语言的特性。“素数筛”的原理如图1-4所示。

图1-4 素数筛
Newsqueak语言并发版本的“素数筛”程序如下:
// 向通道输出从2开始的自然数序列
counter := prog(c:chan of int) {
i := 2;
for(;;) {
c <-= i++;
}
};
// 针对listen通道获取的数列,过滤掉是prime倍数的数
// 新的序列输出到send通道
filter := prog(prime:int, listen, send:chan of int) {
i:int;
for(;;) {
if((i = <-listen)%prime) {
send <-= i;
}
}
};
// 主函数
// 每个通道第一个流出的数必然是素数
// 然后基于这个新的素数构建新的素数过滤器
sieve := prog() of chan of int {
c := mk(chan of int);
begin counter(c);
prime := mk(chan of int);
begin prog(){
p:int;
newc:chan of int;
for(;;){
prime <-= p =<- c;
newc = mk();
begin filter(p, c, newc);
c = newc;
}
}();
become prime;
};
// 启动素数筛
prime := sieve();
其中counter()函数用于向通道输出原始的自然数序列,每个filter()函数对象则对应每一个新的素数过滤通道,这些素数过滤通道根据当前的素数筛将输入通道流入的数列筛选后重新输出到输出通道。mk(chan of int)用于创建通道,类似Go语言的make(chan int)语句;begin filter(p, c, newc)关键字启动素数筛的并发体,类似Go语言的go filter(p, c, newc)语句;become用于返回函数结果,类似return语句。
Newsqueak语言中并发体和通道的语法与Go语言已经比较接近了,后置的类型声明和Go语言的语法也很相似。
1.2.4 Alef——Phil Winterbottom, 1993
在Go语言出现之前,Alef语言是作者心中比较完美的并发语言,Alef语法和运行时基本是无缝兼容C语言。Alef语言中对线程和进程的并发体都提供了支持,其中proc receive(c)用于启动一个进程,task receive(c)用于启动一个线程,它们之间通过通道c进行通信。不过由于Alef缺乏内存自动回收机制,导致并发体的内存资源管理异常复杂。而且Alef语言只在Plan9系统中提供过短暂的支持,其他操作系统并没有实际可以运行的Alef开发环境。而且Alef语言只有《Alef语言规范》和《Alef编程向导》两个公开的文档,因此在贝尔实验室之外关于Alef语言的讨论并不多。
由于Alef语言同时支持进程和线程并发体,而且在并发体中可以再次启动更多的并发体,导致Alef的并发状态异常复杂。同时Alef没有自动垃圾回收机制(Alef保留的C语言灵活的指针特性,也导致自动垃圾回收机制实现比较困难),各种资源充斥于不同的线程和进程之间,导致并发体的内存资源管理异常复杂。Alef语言全部继承了C语言的语法,可以认为是增强了并发语法的C语言。图1-5给出的是Alef语言文档中展示的一个可能的并发体状态。

图1-5 Alef并发模型
Alef语言并发版本的“Hello, World”程序如下:
#include
void receive(chan(byte*) c) {
byte *s;
s = <- c;
print("%s\n", s);
terminate(nil);
}
void main(void) {
chan(byte*) c;
alloc c;
proc receive(c);
task receive(c);
c <- = "hello proc or task";
c <- = "hello proc or task";
print("done\n");
terminate(nil);
}
程序开头的#include 语句用于包含Alef语言的运行时库。Receive ()是一个普通函数,用作程序中每个并发体的入口函数;main()函数中的alloc c语句先创建一个chan(byte*)类型的通道,类似Go语言的make(chan []byte)语句;然后分别以进程和线程的方式启动receive()函数;启动并发体之后,main()函数向c通道发送了两个字符串数据;而进程和线程状态运行的receive()函数会以不确定的顺序先后从通道收到数据后,分别打印字符串;最后每个并发体都通过调用terminate(nil)来结束自己。
Alef的语法和C语言基本保持一致,可以认为它是在C语言的语法基础上增加了并发编程相关的特性,可以看作是另一个维度的C++语言。
1.2.5 Limbo——Sean Dorward, Phil Winterbottom, Rob Pike, 1995
Limbo(地狱)是用于开发运行在小型计算机上的分布式应用的编程语言,它支持模块化编程、编译期和运行时的强类型检查、进程内基于具有类型的通信通道、原子性垃圾收集和简单的抽象数据类型。Limbo被设计为:即便是在没有硬件内存保护的小型设备上,也能安全运行。Limbo语言主要运行在Inferno系统之上。
Limbo语言版本的“Hello, World”程序如下:
implement Hello;
include "sys.m"; sys: Sys;
include "draw.m";
Hello: module
{
init: fn(ctxt: ref Draw->Context, args: list of string);
};
init(ctxt: ref Draw->Context, args: list of string)
{
sys = load Sys Sys->PATH;
sys->print("hello, world\n");
}
从这个版本的“Hello, World”程序中,已经可以发现很多Go语言特性的雏形。第一句implement Hello;基本对应Go语言的包声明语句package Hello。然后是include "sys.m"; sys: Sys;和include "draw.m";语句用于导入其他模块,类似Go语言的import "sys"和import "draw"语句。Hello包模块还提供了模块初始化函数init(),并且函数的参数的类型也是后置的,不过Go语言的初始化函数是没有参数的。
1.2.6 Go语言——2007—2009
贝尔实验室后来经历了多次动荡,包括Ken Thompson在内的Plan9项目原班人马最终加入了谷歌公司。在Limbo等前辈语言诞生10多年之后,在2007年底,Go语言3个最初的作者因为偶然的因素聚集到一起批斗C++(传说是C++语言的布道师在谷歌公司到处鼓吹C++11各种强大的特性彻底惹恼了他们),他们终于抽出了20%的自由时间创造了Go语言。最初的Go语言规范从2008年3月开始编写,最初的Go程序也是直接编译为C语言,然后再二次编译为机器码。到2008年5月,谷歌公司的领导们终于发现了Go语言的巨大潜力,从而开始全力支持这个项目(谷歌的创始人甚至还贡献了func关键字),让他们可以将全部工作时间投入到Go语言的设计和开发中。在Go语言规范初版完成之后,Go语言的编译器终于可以直接生成机器码了。
1.hello.go——2008年6月
下面是初期Go语言程序正式开始测试的版本:
package main
func main() int {
print "hello, world\n";
return 0;
}
其中内置的用于调试的print语句已经存在,不过是以命令的方式使用的。入口main()函数还和C语言中的main()函数一样返回int类型的值,而且需要return显式地返回值。每个语句末尾的分号也还存在。
2.hello.go——2008年6月27日
下面是2008年6月的Go代码:
package main
func main() {
print "hello, world\n";
}
入口函数main()已经去掉了返回值,程序默认通过隐式调用exit(0)来返回。Go语言朝着简单的方向逐步进化。
3.hello.go——2008年8月11日
下面是2008年8月的代码:
package main
func main() {
print("hello, world\n");
}
用于调试的内置的print由开始的命令改为普通的内置函数,使语法更加简单一致。
4.hello.go——2008年10月24日
下面是2008年10月的代码:
package main
import "fmt"
func main() {
fmt.printf("hello, world\n");
}
作为C语言中招牌的printf ()格式化函数已经移植到了Go语言中,函数放在fmt包中(fmt是格式化单词format的缩写)。不过printf()函数名的开头字母依然是小写字母,采用大写字母表示导出的特性还没有出现。
5.hello.go——2009年1月15日
下面是2009年1月的代码:
package main
import "fmt"
func main() {
fmt.Printf("hello, world\n");
}
Go语言开始采用是否大小写首字母来区分符号是否可以导出。大写字母开头表示导出的公共符号,小写字母开头表示包内部的私有符号。但需要注意的是,汉字中没有大小写字母的概念,因此以汉字开头的符号目前是无法导出的(针对该问题,中国用户已经给出相关建议,等Go 2之后或许会调整对汉字的导出规则)。
6.hello.go——2009年12月11日
下面是2009年12月的代码:
package main
import "fmt"
func main() {
fmt.Printf("hello, world\n")
}
Go语言终于移除了语句末尾的分号。这是Go语言在2009年11月10日正式开源之后第一个比较重要的语法改进。从1978年C语言教程第一版引入的分号分隔的规则到现在,Go语言的作者们花了整整32年终于移除了语句末尾的分号。在这32年的演化过程中必然充满了各种八卦故事,我想这一定是Go语言设计者深思熟虑的结果(现在Swift等新的语言也是默认忽略分号的,可见分号确实并不是那么重要)。
1.2.7 你好,世界!——V2.0
在经过半个世纪的涅槃重生之后,Go语言不仅打印出了Unicode版本的“Hello, World”,而且可以方便地向全球用户提供打印服务。下面版本通过http服务向每个访问的客户端打印中文的“你好, 世界!”和当前的时间信息。
package main
import (
"fmt"
"log"
"net/http"
"time"
)
func main() {
fmt.Println("Please visit http://127.0.0.1:12345/")
http.HandleFunc("/", func(w http.ResponseWriter, req *http.Request) {
s := fmt.Sprintf("你好, 世界! -- Time: %s", time.Now().String())
fmt.Fprintf(w, "%v\n", s)
log.Printf("%v\n", s)
})
if err := http.ListenAndServe(":12345", nil); err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
这里我们通过Go语言标准库自带的net/http包,构造了一个独立运行的HTTP服务。其中http.HandleFunc("/", ...)针对根路径/请求注册了响应处理函数。在响应处理函数中,我们依然使用fmt.Fprintf ()格式化输出函数实现了通过HTTP协议向请求的客户端打印格式化的字符串,同时通过标准库的日志包在服务器端也打印相关字符串。最后通过http.ListenAndServe()函数调用来启动HTTP服务。
至此,Go语言终于完成了从单机单核时代的C语言到21世纪互联网时代多核环境的通用编程语言的蜕变。
1.3 数组、字符串和切片
在主流的编程语言中数组及其相关的数据结构是使用得最为频繁的,只有在它(们)不能满足时才会考虑链表、散列表(散列表可以看作是数组和链表的混合体)和更复杂的自定义数据结构。
Go语言中数组、字符串和切片三者是密切相关的数据结构。这3种数据类型,在底层原始数据有着相同的内存结构,在上层,因为语法的限制而有着不同的行为表现。首先,Go语言的数组是一种值类型,虽然数组的元素可以被修改,但是数组本身的赋值和函数传参都是以整体复制的方式处理的。Go语言字符串底层数据也是对应的字节数组,但是字符串的只读属性禁止了在程序中对底层字节数组的元素的修改。字符串赋值只是复制了数据地址和对应的长度,而不会导致底层数据的复制。切片的行为更为灵活,切片的结构和字符串结构类似,但是解除了只读限制。切片的底层数据虽然也是对应数据类型的数组,但是每个切片还有独立的长度和容量信息,切片赋值和函数传参时也是将切片头信息部分按传值方式处理。因为切片头含有底层数据的指针,所以它的赋值也不会导致底层数据的复制。其实Go语言的赋值和函数传参规则很简单,除闭包函数以引用的方式对外部变量访问之外,其他赋值和函数传参都是以传值的方式处理。要理解数组、字符串和切片这3种不同的处理方式的原因,需要详细了解它们的底层数据结构。
1.3.1 数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。数组的长度是数组类型的组成部分。因为数组的长度是数组类型的一部分,不同长度或不同类型的数据组成的数组都是不同的类型,所以在Go语言中很少直接使用数组(不同长度的数组因为类型不同无法直接赋值)。和数组对应的类型是切片,切片是可以动态增长和收缩的序列,切片的功能也更加灵活,但是要理解切片的工作原理还是要先理解数组。
我们先看看数组有哪些定义方式:
var a [3]int // 定义长度为3的int型数组,元素全部为0
var b = [...]int{1, 2, 3} // 定义长度为3的int型数组,元素为1, 2, 3
var c = [...]int{2: 3, 1: 2} // 定义长度为3的int型数组,元素为0, 2, 3
var d = [...]int{1, 2, 4: 5, 6} // 定义长度为6的int型数组,元素为1, 2, 0, 0, 5, 6
第一种方式是定义一个数组变量的最基本的方式,数组的长度明确指定,数组中的每个元素都以零值初始化。
第二种方式是定义数组,可以在定义的时候顺序指定全部元素的初始化值,数组的长度根据初始化元素的数目自动计算。
第三种方式是以索引的方式来初始化数组的元素,因此元素的初始化值出现顺序比较随意。这种初始化方式和map[int]Type类型的初始化语法类似。数组的长度以出现的最大的索引为准,没有明确初始化的元素依然用零值初始化。
第四种方式是混合了第二种和第三种的初始化方式,前面两个元素采用顺序初始化,第三个和第四个元素采用零值初始化,第五个元素通过索引初始化,最后一个元素跟在前面的第五个元素之后采用顺序初始化。
数组的内存结构比较简单。例如,图1-6给出的是一个[4]int{2,3,5,7}数组值对应的内存结构。
![[外链图片转存(img-kzF9x4NQ-1562633186299)(/api/storage/getbykey/original?key=1906f78e18b487087e24)(/api/storage/getbykey/original?key=1906f78e18b487087e24)]](http://img.e-com-net.com/image/info8/cad9d31ea586455d93b065d52a5006c0.png)
图1-6 数组布局
Go语言中数组是值语义。一个数组变量即表示整个数组,它并不是隐式地指向第一个元素的指针(例如C语言的数组),而是一个完整的值。当一个数组变量被赋值或者被传递的时候,实际上会复制整个数组。如果数组较大的话,数组的赋值也会有较大的开销。为了避免复制数组带来的开销,可以传递一个指向数组的指针,但是数组指针并不是数组。
var a = [...]int{1, 2, 3} // a是一个数组
var b = &a // b是指向数组的指针
fmt.Println(a[0], a[1]) // 打印数组的前两个元素
fmt.Println(b[0], b[1]) // 通过数组指针访问数组元素的方式和通过数组类似
for i, v := range b { // 通过数组指针迭代数组的元素
fmt.Println(i, v)
}
其中b是指向数组a的指针,但是通过b访问数组中元素的写法和a是类似的。还可以通过for range来迭代数组指针指向的数组元素。其实数组指针类型除类型和数组不同之外,通过数组指针操作数组的方式和通过数组本身的操作类似,而且数组指针赋值时只会复制一个指针。但是数组指针类型依然不够灵活,因为数组的长度是数组类型的组成部分,指向不同长度数组的数组指针类型也是完全不同的。
可以将数组看作一个特殊的结构体,结构的字段名对应数组的索引,同时结构体成员的数目是固定的。内置函数len()可以用于计算数组的长度,cap()函数可以用于计算数组的容量。不过对数组类型来说,len()和cap()函数返回的结果始终是一样的,都是对应数组类型的长度。
我们可以用for循环来迭代数组。下面常见的几种方式都可以用来遍历数组:
for i := range a {
fmt.Printf("a[%d]: %d\n", i, a[i])
}
for i, v := range b {
fmt.Printf("b[%d]: %d\n", i, v)
}
for i := 0; i < len(c); i++ {
fmt.Printf("c[%d]: %d\n", i, c[i])
}
用for range方式迭代的性能可能会更好一些,因为这种迭代可以保证不会出现数组越界的情形,每轮迭代对数组元素的访问时可以省去对下标越界的判断。
用for range方式迭代,还可以忽略迭代时的下标:
var times [5][0]int
for range times {
fmt.Println("hello")
}
其中times对应一个[5][0]int类型的数组,虽然第一维数组有长度,但是数组的元素[0]int大小是0,因此整个数组占用的内存大小依然是0。不用付出额外的内存代价,我们就通过for range方式实现times次快速迭代。
数组不仅可以定义数值数组,还可以定义字符串数组、结构体数组、函数数组、接口数组、通道数组等:
// 字符串数组
var s1 = [2]string{"hello", "world"}
var s2 = [...]string{"你好", "世界"}
var s3 = [...]string{1: "世界", 0: "你好", }
// 结构体数组
var line1 [2]image.Point
var line2 = [...]image.Point{image.Point{X: 0, Y: 0}, image.Point{X: 1, Y: 1}}
var line3 = [...]image.Point{{0, 0}, {1, 1}}
// 函数数组
var decoder1 [2]func(io.Reader) (image.Image, error)
var decoder2 = [...]func(io.Reader) (image.Image, error){
png.Decode,
jpeg.Decode,
}
// 接口数组
var unknown1 [2]interface{}
var unknown2 = [...]interface{}{123, "你好"}
// 通道数组
var chanList = [2]chan int{}
我们还可以定义一个空的数组:
var d [0]int // 定义一个长度为0的数组
var e = [0]int{} // 定义一个长度为0的数组
var f = [...]int{} // 定义一个长度为0的数组
长度为0的数组(空数组)在内存中并不占用空间。空数组虽然很少直接使用,但是可以用于强调某种特有类型的操作时避免分配额外的内存空间,例如用于通道的同步操作:
c1 := make(chan [0]int)
go func() {
fmt.Println("c1")
c1 <- [0]int{}
}()
<-c1
在这里,我们并不关心通道中传输数据的真实类型,其中通道接收和发送操作只是用于消息的同步。对于这种场景,我们用空数组作为通道类型可以减少通道元素赋值时的开销。当然,一般更倾向于用无类型的匿名结构体代替空数组:
c2 := make(chan struct{})
go func() {
fmt.Println("c2")
c2 <- struct{}{} // struct{}部分是类型,{}表示对应的结构体值
}()
<-c2
我们可以用fmt.Printf()函数提供的%T或%#v谓词语法来打印数组的类型和详细信息:
fmt.Printf("b: %T\n", b) // b: [3]int
fmt.Printf("b: %#v\n", b) // b: [3]int{1, 2, 3}
在Go语言中,数组类型是切片和字符串等结构的基础。以上对于数组的很多操作都可以直接用于字符串或切片中。
1.3.2 字符串
一个字符串是一个不可改变的字节序列,字符串通常是用来包含人类可读的文本数据。和数组不同的是,字符串的元素不可修改,是一个只读的字节数组。每个字符串的长度虽然也是固定的,但是字符串的长度并不是字符串类型的一部分。由于Go语言的源代码要求是UTF8编码,导致Go源代码中出现的字符串面值常量一般也是UTF8编码的。源代码中的文本字符串通常被解释为采用UTF8编码的Unicode码点(rune)序列。因为字节序列对应的是只读的字节序列,所以字符串可以包含任意的数据,包括字节值0。我们也可以用字符串表示GBK等非UTF8编码的数据,不过这时候将字符串看作是一个只读的二进制数组更准确,因为for range等语法并不能支持非UTF8编码的字符串的遍历。
Go语言字符串的底层结构在reflect.StringHeader中定义:
type StringHeader struct {
Data uintptr
Len int
}
字符串结构由两个信息组成:第一个是字符串指向的底层字节数组;第二个是字符串的字节的长度。字符串其实是一个结构体,因此字符串的赋值操作也就是reflect.StringHeader结构体的复制过程,并不会涉及底层字节数组的复制。1.3.1节中提到的[2]string字符串数组对应的底层结构和[2]reflect.StringHeader对应的底层结构是一样的,可以将字符串数组看作一个结构体数组。
我们可以看看字符串"hello, world"本身对应的内存结构,如图1-7所示。

图1-7 字符串布局
分析可以发现,"hello, world"字符串底层数据和以下数组是完全一致的:
var data = [...]byte{
'h', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd',
}
字符串虽然不是切片,但是支持切片操作,不同位置的切片底层访问的是同一块内存数据(因为字符串是只读的,所以相同的字符串面值常量通常对应同一个字符串常量):
s := "hello, world"
hello := s[:5]
world := s[7:]
s1 := "hello, world"[:5]
s2 := "hello, world"[7:]
字符串和数组类似,内置的len()函数返回字符串的长度。也可以通过reflect.StringHeader结构访问字符串的长度(这里只是为了演示字符串的结构,并不是推荐的做法):
fmt.Println("len(s):", (*reflect.StringHeader)(unsafe.Pointer(&s)).Len) // 12
fmt.Println("len(s1):", (*reflect.StringHeader)(unsafe.Pointer(&s1)).Len) // 5
fmt.Println("len(s2):", (*reflect.StringHeader)(unsafe.Pointer(&s2)).Len) // 5
根据Go语言规范,Go语言的源文件都采用UTF8编码。因此,Go源文件中出现的字符串面值常量一般也是UTF8编码的(对于转义字符,则没有这个限制)。提到Go字符串时,一般都会假设字符串对应的是一个合法的UTF8编码的字符序列。可以用内置的print调试函数或fmt.Print()函数直接打印,也可以用for range循环直接遍历UTF8解码后的Unicode码点值。
下面的"hello,世界"字符串中包含了中文字符,可以通过打印转型为字节类型来查看字符底层对应的数据:
fmt.Printf("%#v\n", []byte("hello, 世界"))
输出的结果是:
[]byte{0x48, 0x65, 0x6c, 0x6c, 0x6f, 0x2c, 0x20, 0xe4, 0xb8, 0x96, 0xe7, \
0x95, 0x8c}
分析可以发现,0xe4, 0xb8, 0x96对应中文“世”,0xe7, 0x95, 0x8c对应中文“界”。我们也可以在字符串面值中直接指定UTF8编码后的值(源文件中全部是ASCII码,可以避免出现多字节的字符)。
fmt.Println("\xe4\xb8\x96") // 打印“世”
fmt.Println("\xe7\x95\x8c") // “界”
图1-8展示了“hello, 世界”字符串的内存结构布局。
[外链图片转存失败(img-tA8buqi7-1562633513316)(/api/storage/getbykey/original?key=19068fa0307aab28b265)]![]()
图1-8 字符串布局
Go语言的字符串中可以存放任意的二进制字节序列,而且即使是UTF8字符序列也可能会遇到错误的编码。如果遇到一个错误的UTF8编码输入,将生成一个特别的Unicode字符'\uFFFD',这个字符在不同的软件中的显示效果可能不太一样,在印刷中这个符号通常是一个黑色六角形或钻石形状,里面包含一个白色的问号“�”。
下面的字符串中,我们故意损坏了第一字符的第二和第三字节,因此第一字符将会打印为“�”,第二和第三字节则被忽略,后面的“abc”依然可以正常解码打印(错误编码不会向后扩散是UTF8编码的优秀特性之一)。
fmt.Println("\xe4\x00\x00\xe7\x95\x8cabc") // �界abc
不过在for range迭代这个含有损坏的UTF8字符串时,第一字符的第二和第三字节依然会被单独迭代到,不过此时迭代的值是损坏后的0:
for i, c := range "\xe4\x00\x00\xe7\x95\x8cabc" {
fmt.Println(i, c)
}
// 0 65533 // \uFFF,对应�
// 1 0 // 空字符
// 2 0 // 空字符
// 3 30028 // 界
// 6 97 // a
// 7 98 // b
// 8 99 // c
如果不想解码UTF8字符串,想直接遍历原始的字节码,可以将字符串强制转为[]byte字节序列后再进行遍历(这里的转换一般不会产生运行时开销):
for i, c := range []byte("世界abc") {
fmt.Println(i, c)
}
或者是采用传统的下标方式遍历字符串的字节数组:
const s = "\xe4\x00\x00\xe7\x95\x8cabc"
for i := 0; i < len(s); i++ {
fmt.Printf("%d %x\n", i, s[i])
}
Go语言除了for range语法对UTF8字符串提供了特殊支持外,还对字符串和[]rune类型的相互转换提供了特殊的支持。
fmt.Printf("%#v\n", []rune("世界")) // []int32{19990, 30028}
fmt.Printf("%#v\n", string([]rune{'世', '界'})) // 世界
从上面代码的输出结果可以发现[]rune其实是[]int32类型,这里的rune只是int32类型的别名,并不是重新定义的类型。rune用于表示每个Unicode码点,目前只使用了21个位。
字符串相关的强制类型转换主要涉及[]byte和[]rune两种类型。每个转换都可能隐含重新分配内存的代价,最坏的情况下它们运算的时间复杂度都是O(n)。不过字符串和[]rune的转换要更为特殊一些,因为一般这种强制类型转换要求两个类型的底层内存结构要尽量一致,显然它们底层对应的[]byte和[]int32类型是完全不同的内存结构,因此这种转换可能隐含重新分配内存的 操作。
下面分别用伪代码简单模拟Go语言对字符串内置的一些操作,这样对每个操作的处理的时间复杂度和空间复杂度都会有较明确的认识。
for range对字符串的迭代模拟实现如下:
func forOnString(s string, forBody func(i int, r rune)) {
for i := 0; len(s) > 0; {
r, size := utf8.DecodeRuneInString(s)
forBody(i, r)
s = s[size:]
i += size
}
}
for range迭代字符串时,每次解码一个Unicode字符,然后进入for循环体,遇到崩溃的编码并不会导致迭代停止。
[]byte(s)转换模拟实现如下:
func str2bytes(s string) []byte {
p := make([]byte, len(s))
for i := 0; i < len(s); i++ {
c := s[i]
p[i] = c
}
return p
}
模拟实现中新创建了一个切片,然后将字符串的数组逐一复制到切片中,这是为了保证字符串只读的语义。当然,在将字符串转换为[]byte时,如果转换后的变量没有被修改,编译器可能会直接返回原始的字符串对应的底层数据。
string(bytes)转换模拟实现如下:
func bytes2str(s []byte) (p string) {
data := make([]byte, len(s))
for i, c := range s {
data[i] = c
}
hdr := (*reflect.StringHeader)(unsafe.Pointer(&p))
hdr.Data = uintptr(unsafe.Pointer(&data[0]))
hdr.Len = len(s)
return p
}
因为Go语言的字符串是只读的,无法以直接构造底层字节数组的方式生成字符串。在模拟实现中通过unsafe包获取字符串的底层数据结构,然后将切片的数据逐一复制到字符串中,这同样是为了保证字符串只读的语义不受切片的影响。如果转换后的字符串在生命周期中原始的[]byte的变量不发生变化,编译器可能会直接基于[]byte底层的数据构建字符串。
[]rune(s)转换模拟实现如下:
func str2runes(s []byte) []rune {
var p []int32
for len(s) > 0 {
r, size := utf8.DecodeRune(s)
p = append(p, int32(r))
s = s[size:]
retur []rune(p)
}
因为底层内存结构的差异,所以字符串到[]rune的转换必然会导致重新分配[]rune内存空间,然后依次解码并复制对应的Unicode码点值。这种强制转换并不存在前面提到的字符串和字节切片转换时的优化情况。
string(runes)转换模拟实现如下:
func runes2string(s []int32) string {
var p []byte
buf := make([]byte, 3)
for _, r := range s {
n := utf8.EncodeRune(buf, r)
p = append(p, buf[:n]...)
}
return string(p)
}
同样因为底层内存结构的差异,[]rune到字符串的转换也必然会导致重新构造字符串。这种强制转换并不存在前面提到的优化情况。
没看过瘾,可以移步这里购买
