自编码AutoEncoder 及PyTorch 实现
自编码AutoEncoder是一种无监督学习的算法,他利用反向传播算法,让目标值等于输入值。什么意思呢,下面举个例子:
有一个神经网络,它在做的事情是,输入一张图片,通过一个Encoder神经网络,输出一个比较"浓缩的"feature map。之后将这个feature map通过一个Decoder网络,结果又将这张图片还原回去了
你也可以这么理解,整个Encoder+Decoder是一个神经网络,中间的code只是暂存的数据

感觉就像是,现在有一锅红糖水,你不停的煮它,最终水都被煮干了,只剩下红糖,这个红糖就是上图的"Code"。然后你再向红糖里面注水、加热,结果又还原回了一锅红糖水
假设上面的神经网络展开如下图所示,可以看出,图片经过了一个压缩,再解压的工序。当压缩的时候,原有的图片质量被缩减。解压时,用信息量少却包含所有关键信息的文件恢复出了原本的图片。为什么要这样做呢?

因为有时候神经网络要接受大量的输入信息,比如说输入信息是高清图片时,信息量可能高达上千万,让神经网络直接从上千万个信息中进行学习是很吃力的。所以,为何不压缩一下,提取出原图片中最具代表性的信息,缩减输入信息量,再把缩减后的信息带入进行网络学习。这样学习起来就轻松多了
How to Train?
下图是一个AutoEncoder的三层模型,其中 , 没有什么含义,仅仅是个变量名字而已,用来区分 ,你也可以管 叫

Vincent在2010年的论文(http://jmlr.org/papers/volume11/vincent10a/vincent10a.pdf)中做了研究,发现只要单组 就可以了,即 。 和 称为Tied Weights(绑定的权重),实验证明, 真的只是在打酱油,完全没有必要去训练
如果是实数作为输入,Loss function就是

如果输入是binary的,即01值,那么就是

PCA V.S. AutoEncoder
同样都是降维,PCA和AutoEncoder谁的效果更好呢?
首先从直觉上分析,PCA本质上是线性的变换,所以它是有局限性的。而AutoEncoder是基于DNN的,由于有activation function的存在,所以可以进行非线性变换,使用范围更广
下图展示了MNIST数据集分别经过PCA和AutoEncoder降维再还原后的效果。第二行是是使用AutoEncoder的方法,可以看到几乎没什么太大变化;而第四行的图片很多都变得非常模糊了。说明PCA的效果是不如AutoEncoder的

Denoising AutoEncoders
Vincent在2008的论文(http://www.iro.umontreal.ca/~lisa/publications2/index.php/publications/show/217)中提出了AutoEncoder的改良版——dA,论文标题叫"Extracting and Composing Robust Features",译成中文就是"提取、编码出具有鲁棒性的特征"
首先我们考虑,为什么会产生这样的变种AutoEncoder。如果我们仅仅只是在像素级别对一张图片进行Encode,然后再重建,这样就无法发现更深层次的信息,很有可能会导致网络记住了一些特征。为了防止这种情况产生,我们可以给输入图片加一些噪声,比方说生成和图片同样大小的高斯分布的数据,然后和图像的像素值相加(见下图)。如果这样都能重建原来的图片,意味着这个网络能从这些混乱的信息中发现真正有用的特征,此时的Code才能代表输入图片的"精华"
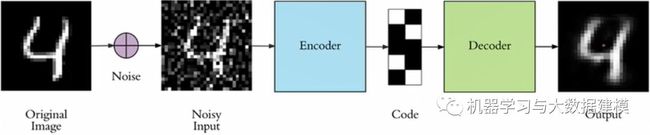
关键是,这样胡乱给原始图片加噪声真的科学吗?Vincent从大脑认知角度给了解释。Paper中说到:
人类具有认识被阻挡的破损图像的能力,源于我们高等的联想记忆感受机能
就是说,我们能以多种形式去记忆(比如图像、声音),所以即便是数据破损丢失,我们也能回想起来
Dropout AutoEncoders
其实这个没什么特别的,平时我们不论是CNN还是RNN几乎都会用到Dropout。据说Dropout是当时Hilton在给学生上课的时候提到的,用来帮助提升神经网路训练效果的小Trick。具体关于Dropout的讲解可以看我的这篇文章(https://wmathor.com/index.php/archives/1377/)

Adversarial AutoEncoders
在AutoEncoder中可能存在这样一个问题,图片经过Encode之后的vector并不符合我们希望的分布(例如高斯分布),他的分布很有可能如下图所示。这其实是令我们不太满意的(虽然我并不知道Code满足分布到底有重要,但是既然别人认为很重要那就重要吧),那么有什么解决办法呢?

由University of Toronto、Google Brain和OpenAI合作的文章Adversarial Autoencoders(AAE)(https://arxiv.org/pdf/1511.05644.pdf)提出了一个使用Autoencoder进行对抗学习的idea,某种程度上对上述问题提供了一些新思路
AAE的核心其实就是利用GAN的思想,利用一个生成器G和一个判别器D进行对抗学习,以区分Real data和Fake data。具体思路是这样的,我现在需要一个满足 概率分布的 向量,但是 实际上满足 分布。那么我就首先生成一个满足 分布的 向量,打上Real data的标签,然后将 向量打上Fake data的标签,将它们俩送入判别器D。判别器D通过不断学习,预测输入input是来自于Real data(服从预定义的 分布)还是Fake data(服从 分布)。由于这里的 可以是我们定义的任何一个概率分布,因此整个对抗学习的过程实际上可以认为是通过调整Encoder不断让其产生数据的概率分布 接近我们预定义的

基本上AAE的原理就讲完了,还剩最后一个问题,AAE的Loss function是什么?

其中

如果 和 分布非常接近,那么 。回过头看上面的Loss function就很好理解了,因为我们需要minimize loss,而且要求 分布趋近于 分布,而KL散度的作用正好是计算两个分布的相似程度
下面简述KL散度的公式推导。假设 和 均是服从 和 的随机变量的概率密度函数,则

更加详细的推导过程可以看这篇文章(https://hsinjhao.github.io/2019/05/22/KL-DivergenceIntroduction/)
Variational AutoEncoders
前面的各种AutoEncoder都是将输入数据转换为vector,其中每个维度代表学习到的数据。而Variational AutoEncoders(VAE)提供了一种概率分布的描述形式,VAE中Encoder描述的是每个潜在属性的概率分布,而不是直接输出一个值
举例来说,假设我们已经在一个AutoEncoder上训练了一个6维的vector,这个6维的vector将学习面部的一些属性,例如肤色、是否戴眼镜等
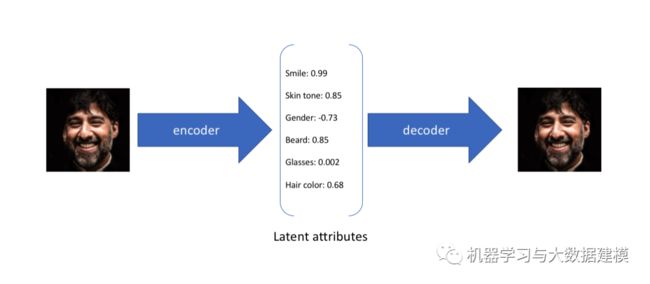
在上面的示例中,我们使用单个值来描述输入图像的潜在属性。但是,我们可能更喜欢将每个潜在属性表示为一个范围。VAE就可以实现这个功能,如下图所示
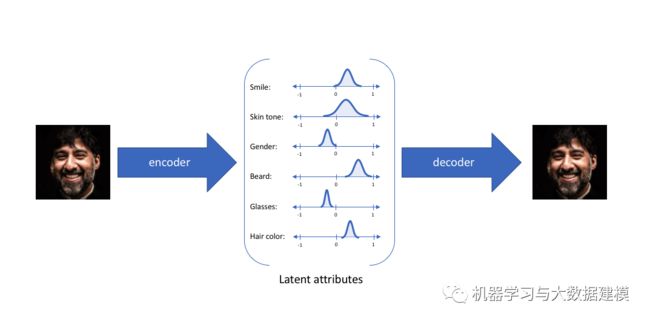
通过这种方法,我们现在将给定输入的每个潜在属性表示为概率分布。从状态解码(Decode)时,我们将从每个潜在状态分布中随机采样以生成向量来作为解码器的输入

现在问题来了,sample()是不能求导的,那我们如何反向传播?幸运的是,我们可以利用一个聪明的办法——"reparameterization trick"。这个办法的具体思想如下图,假设我们要让 服从正态分布,我们可以生成一个标准正态 ,对这个标准正态进行平移以及伸缩变换,生成均值为 ,方差为 的正态分布

通过reparameterization,we can now optimize the parameters of the distribution, while still maintaing 。就是说,我们保持 不变,因为 不需要学习修正,我们更新的只有 和

AutoEncoder的PyTorch实现
其实AutoEncoder就是非常简单的DNN。在encoder中神经元随着层数的增加逐渐变少,也就是降维的过程。而在decoder中神经元随着层数的增加逐渐变多,也就是升维的过程
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
self.encoder = nn.Sequential(
# [b, 784] => [b, 256]
nn.Linear(784, 256),
nn.ReLU(),
# [b, 256] => [b, 64]
nn.Linear(256, 64),
nn.ReLU(),
# [b, 64] => [b, 20]
nn.Linear(64, 20),
nn.ReLU()
)
self.decoder = nn.Sequential(
# [b, 20] => [b, 64]
nn.Linear(20, 64),
nn.ReLU(),
# [b, 64] => [b, 256]
nn.Linear(64, 256),
nn.ReLU(),
# [b, 256] => [b, 784]
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param [b, 1, 28, 28]:
:return [b, 1, 28, 28]:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, -1)
# encode
x = self.encoder(x)
# decode
x = self.decoder(x)
# reshape
x = x.view(batchsz, 1, 28, 28)
return x
上面代码都是基本操作,有一个地方需要特别注意,在decoder网络中,最后跟的不是ReLU而是Sigmoid函数,因为我们想要将图片打印出来看一下,而使用的数据集是MNIST,所以要将tensor里面的值最终都压缩到0-1之间
然后定义训练集和测试集,将它们分别带入到DataLoader中
mnist_train = datasets.MNIST('mnist', train=True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST('mnist', train=False, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test, batch_size=32)
由于input是0-1之间的实数,所以Loss function选择MSE
epochs = 1000
lr = 1e-3
model = AE()
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
print(model)
在通常(监督学习)情况下,我们需要将网络的输出output和训练集的label进行对比,计算loss。但AutoEncoder是无监督学习,不需要label,我们只需要将网络的输出output和网络的输入input进行对比,计算loss即可
viz = visdom.Visdom()
for epoch in range(epochs):
# 不需要label,所以用一个占位符"_"代替
for batchidx, (x, _) in enumerate(mnist_train):
x_hat = model(x)
loss = criteon(x_hat, x)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(epoch, 'loss:', loss.item())
x, _ = iter(mnist_test).next()
with torch.no_grad():
x_hat = model(x)
viz.images(x, nrow=8, win='x', opts=dict(title='x'))
viz.images(x_hat, nrow=8, win='x_hat', opts=dict(title='x_hat'))
到这里,最简单的AutoEncoder代码已经写完了,完整代码如下:
import torch
import visdom
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from torch import nn, optim
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
self.encoder = nn.Sequential(
# [b, 784] => [b, 256]
nn.Linear(784, 256),
nn.ReLU(),
# [b, 256] => [b, 64]
nn.Linear(256, 64),
nn.ReLU(),
# [b, 64] => [b, 20]
nn.Linear(64, 20),
nn.ReLU()
)
self.decoder = nn.Sequential(
# [b, 20] => [b, 64]
nn.Linear(20, 64),
nn.ReLU(),
# [b, 64] => [b, 256]
nn.Linear(64, 256),
nn.ReLU(),
# [b, 256] => [b, 784]
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param [b, 1, 28, 28]:
:return [b, 1, 28, 28]:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, -1)
# encoder
x = self.encoder(x)
# decoder
x = self.decoder(x)
# reshape
x = x.view(batchsz, 1, 28, 28)
return x
def main():
mnist_train = datasets.MNIST('mnist', train=True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST('mnist', train=False, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test, batch_size=32)
epochs = 1000
lr = 1e-3
model = AE()
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
print(model)
viz = visdom.Visdom()
for epoch in range(epochs):
# 不需要label,所以用一个占位符"_"代替
for batchidx, (x, _) in enumerate(mnist_train):
x_hat = model(x)
loss = criteon(x_hat, x)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(epoch, 'loss:', loss.item())
x, _ = iter(mnist_test).next()
with torch.no_grad():
x_hat = model(x)
viz.images(x, nrow=8, win='x', opts=dict(title='x'))
viz.images(x_hat, nrow=8, win='x_hat', opts=dict(title='x_hat'))
if __name__ == '__main__':
main()
得到的效果如下图所示,普通的AutoEncoder还是差了一点,可以看到很多图片已经看不清具体代表的数字了

Variational AutoEncoders
AutoEncoder的shape变化是[b, 784] => [b, 20] => [b, 784],虽然VAE也是这样,但其中的20并不一样,对于VAE来说,[b, 20]要分成两个[b, 10],分别是 和 ,具体形式见下图

最主要先关注一下定义网络的部分
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# [b, 784] => [b, 20]
# u: [b, 10]
# sigma: [b, 10]
self.encoder = nn.Sequential(
# [b, 784] => [b, 256]
nn.Linear(784, 256),
nn.ReLU(),
# [b, 256] => [b, 64]
nn.Linear(256, 64),
nn.ReLU(),
# [b, 64] => [b, 20]
nn.Linear(64, 20),
nn.ReLU()
)
self.decoder = nn.Sequential(
# [b, 10] => [b, 64]
nn.Linear(10, 64),
nn.ReLU(),
# [b, 64] => [b, 256]
nn.Linear(64, 256),
nn.ReLU(),
# [b, 256] => [b, 784]
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param [b, 1, 28, 28]:
:return [b, 1, 28, 28]:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, -1)
# encoder
# [b, 20] including mean and sigma
q = self.encoder(x)
# [b, 20] => [b, 10] and [b, 10]
mu, sigma = q.chunk(2, dim=1)
# reparameterize trick, epsilon~N(0, 1)
q = mu + sigma * torch.randn_like(sigma)
# decoder
x_hat = self.decoder(q)
# reshape
x_hat = x_hat.view(batchsz, 1, 28, 28)
# KL
kld = 0.5 * torch.sum(
torch.pow(mu, 2) +
torch.pow(sigma, 2) -
torch.log(1e-8 + torch.pow(sigma, 2)) - 1
) / (batchsz*28*28)
return x_hat, kld
Encode以后的变量 要分成两半儿,利用h.chunk(num, dim)实现,num表示要分成几块,dim值表示在什么维度上进行。然后随机采样出标准正态分布的数据,用 和 对其进行变换。这里的kld指的是KL Divergence,它是Loss的一部分,其计算过程如下:

import torch
import visdom
import numpy as np
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# [b, 784] => [b, 20]
# u: [b, 10]
# sigma: [b, 10]
self.encoder = nn.Sequential(
# [b, 784] => [b, 256]
nn.Linear(784, 256),
nn.ReLU(),
# [b, 256] => [b, 64]
nn.Linear(256, 64),
nn.ReLU(),
# [b, 64] => [b, 20]
nn.Linear(64, 20),
nn.ReLU()
)
self.decoder = nn.Sequential(
# [b, 10] => [b, 64]
nn.Linear(10, 64),
nn.ReLU(),
# [b, 64] => [b, 256]
nn.Linear(64, 256),
nn.ReLU(),
# [b, 256] => [b, 784]
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param [b, 1, 28, 28]:
:return [b, 1, 28, 28]:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, -1)
# encoder
# [b, 20] including mean and sigma
q = self.encoder(x)
# [b, 20] => [b, 10] and [b, 10]
mu, sigma = q.chunk(2, dim=1)
# reparameterize trick, epsilon~N(0, 1)
q = mu + sigma * torch.randn_like(sigma)
# decoder
x_hat = self.decoder(q)
# reshape
x_hat = x_hat.view(batchsz, 1, 28, 28)
# KL
kld = 0.5 * torch.sum(
torch.pow(mu, 2) +
torch.pow(sigma, 2) -
torch.log(1e-8 + torch.pow(sigma, 2)) - 1
) / (batchsz*28*28)
return x_hat, kld
def main():
mnist_train = datasets.MNIST('mnist', train=True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST('mnist', train=False, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test, batch_size=32)
epochs = 1000
lr = 1e-3
model = VAE()
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
print(model)
viz = visdom.Visdom()
for epoch in range(epochs):
# 不需要label,所以用一个占位符"_"代替
for batchidx, (x, _) in enumerate(mnist_train):
x_hat, kld = model(x)
loss = criteon(x_hat, x)
if kld is not None:
elbo = loss + 1.0 * kld
loss = elbo
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(epoch, 'loss:', loss.item(), 'kld', kld.item())
x, _ = iter(mnist_test).next()
with torch.no_grad():
x_hat, kld = model(x)
viz.images(x, nrow=8, win='x', opts=dict(title='x'))
viz.images(x_hat, nrow=8, win='x_hat', opts=dict(title='x_hat'))
if __name__ == '__main__':
main()

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)备注:加入本站微信群或者qq群,请回复“加群”获取一折本站知识星球优惠券,请回复“知识星球”喜欢文章,点个在看
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)备注:加入本站微信群或者qq群,请回复“加群”获取一折本站知识星球优惠券,请回复“知识星球”喜欢文章,点个在看