Scrapy+ChromeDriver+Selenium爬取动态html页面
原文:https://blog.csdn.net/qq_30242609/article/details/70859891
Headless组件ChromeDriver
selenium3.x已经不支持PhantomJS,所以可以使用firifox或者chrome的headless方案
Selenium
Selenium是一个自动化的测试工具,这里主要用到了它的Webdriver操作浏览器。python下载selenium库即可,建议使用conda工具下载
说明
scrapy通过selenium使用ChromeDriver进行headless操作,爬取已经加载js的页面(即动态生成html的页面)
scrapy下载器中间件介绍
Scrapy - Downloader Middleware
Scrapy不再详细介绍,这里主要会用到Downloader Middleware, 下载器中间件。
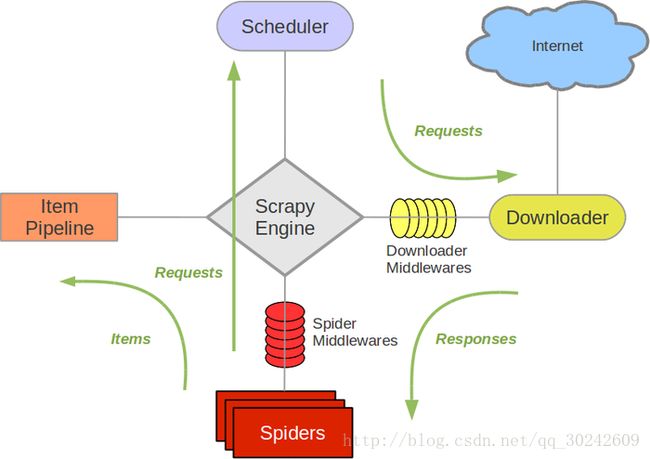
下载器中间件在下载器和Scrapy引擎之间,每一个request和response都会通过中间件进行处理。在中间件中,对request进行处理的函数是process_request(request, spider)
process_request中调用selenium来访问页面,获取js加载后的完整页面,代码如下
# 进程请求方法改成用selenium请求
def process_request(self, request, spider):
content = self.selenium_request(request.url);
if content.strip() != '':
return HtmlResponse(request.url, encoding='utf-8', body=content, request=request)
return None
# return None
return HtmlResponse(request.url, encoding='utf-8', body=content, request=request)里面调用selenium_request请求页面,代码如下
# selenium获取页面浏览器内容
def selenium_request(self, url):
# js控制浏览器滚动到底部js
js = """
function scrollToBottom() {
var Height = document.body.clientHeight, //文本高度
screenHeight = window.innerHeight, //屏幕高度
INTERVAL = 100, // 滚动动作之间的间隔时间
delta = 500, //每次滚动距离
curScrollTop = 0; //当前window.scrollTop 值
console.info(Height)
var scroll = function () {
//curScrollTop = document.body.scrollTop;
curScrollTop = curScrollTop + delta;
window.scrollTo(0,curScrollTop);
console.info("偏移量:"+delta)
console.info("当前位置:"+curScrollTop)
};
var timer = setInterval(function () {
var curHeight = curScrollTop + screenHeight;
if (curHeight >= Height){ //滚动到页面底部时,结束滚动
clearInterval(timer);
}
scroll();
}, INTERVAL)
};
scrollToBottom()
"""
chrome_options = webdriver.ChromeOptions()
# headless无界面模式
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
driver = webdriver.Chrome(chrome_options=chrome_options,executable_path="D:\\开发\chromedriver_win32\\chromedriver")
driver.get(url)
# driver.maximize_window();# 窗口最大化
# 执行js滚动浏览器窗口到底部
driver.execute_script(js)
# time.sleep(5) # 不加载图片的话,这个时间可以不要,等待JS执行
# driver.get_screenshot_as_file("C:\\Users\\Administrator\\Desktop\\test.png")
content = driver.page_source.encode('utf-8')
# driver.quit()
driver.close()
# return None
return content其中的js是用于滚动浏览器到底部,因为一些网页的图片是滚动到某个地方才会加载图片。如果需要爬取图片url的,就需要调用这个js滚动浏览器。作者的js试过有点问题,后面我稍微调整了下
测试时发现,如果等待JS执行的时间过短,会导致爬取的页面靠近底部的图片没能加载,因为滚动函数还未执行到此处。所以需要预留一个稍微长一点的等待时间
# time.sleep(5) # 不加载图片的话,这个时间可以不要,等待JS执行最后开启下载中间件,在settings.py文件中
DOWNLOADER_MIDDLEWARES = {
'mytest.middlewares.MytestDownloaderMiddleware': 543,
}