Pytorch学习笔记之语言模型(四)
语言模型的目标是计算一句话出现的概率有多高?最好的应用即生成类模型,根据一个主题完成一篇描述性文章。最近精彩的项目狗屁不通文章生成器就是典型代表。在线版本请尝试.
理论
一句话出现的概率:
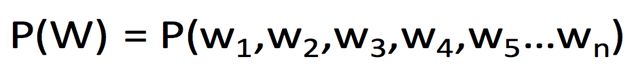
根据条件概率定义,可以推导出
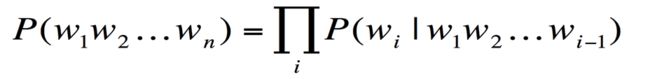
因此Markov提出假设:每个单词只跟它之前的n个单词有关。进而推广二元模型(每个单词由它前面一个单词决定)、N元模型(每个单词由它前面N-1个单词决定)。
评价语义模型的标准
困惑度(Perplexity),一句话的困惑度越高证明生成效果越差。公式如下:

实战
本次训练方式采用二元模型理论。
学习目标
- 学习语言模型,以及如何训练一个语言模型
- 学习torchtext的基本使用方法
- 构建 vocabulary
- word to index 和 index to word
- 学习torch.nn的一些基本模型
- Linear
- RNN
- LSTM
- GRU
- RNN的训练技巧
- Gradient Clipping
- 如何保存和读取模型
1. 构建训练语料
我们会使用 torchtext 来创建vocabulary, 然后把数据读成batch的格式。请大家自行阅读README来学习torchtext。
import torchtext
from torchtext.vocab import Vectors
import torch
import numpy as np
import random
USE_CUDA = torch.cuda.is_available()
# 固定随机数
sed = 53113
random.seed(sed)
np.random.seed(sed)
torch.manual_seed(sed)
if USE_CUDA:
torch.cuda.manual_seed(sed)
device = torch.device('cuda')
BATCH_SIZE = 32
EMBEDDING_SIZE = 100
# 循环网络中隐藏层单元
HIDDEN_SIZE = 100
MAX_VOCAB_SIZE = 50000
- 我们会继续使用上次的text8作为我们的训练,验证和测试数据
- torchtext提供了LanguageModelingDataset这个class来帮助我们处理语言模型数据集
- TEXT = torchtext.data.Field(lower=True) 定义一个Field类型的对象,包含Vocab对象
- torchtext.datasets.LanguageModelingDataset.splits() 为同一个数据集下的训练集、验证集和测试集创建数据对象。splits() 是父类的方法
- TEXT.build_vocab() 构建词表,Construct the Vocab object for this field from one or more datasets.
- 构建完成之后通过TEXT.vocab 查看Vocab对象
- Vocab下有三个属性,分别是~Vocab.freqs -A collections.Counter object holding the frequencies of tokens in the data used to build the Vocab.
- ~Vocab.stoi-A collections.defaultdict instance mapping token strings to numerical identifiers.
- ~Vocab.itos-A list of token strings indexed by their numerical identifiers.
- BPTTIterator可以连续地得到连贯的句子
- 访问网页TORCHTEXT.VOCAB了解更多
(vocab.jpg)]

# https://pytorch.org/text/data.html?highlight=field#torchtext.data.Field
# 定义一个Field类型的对象,包含Vocab对象
TEXT = torchtext.data.Field(lower=True)
# 为同一个数据集下的训练集、验证集和测试集创建数据对象
train, val, test = torchtext.datasets.LanguageModelingDataset.splits(text_field=TEXT,path=r"[换成自己的路径]text8\text8", train="text8.train.txt", validation="text8.dev.txt", test="text8.test.txt")
# 构建词表,Construct the Vocab object for this field from one or more datasets.
# 从一个或多个数据集中,构建Field对象下的Vocab对象
# Vocab下有三个属性,分别是~Vocab.freqs -A collections.Counter object holding the frequencies of tokens in the data used to build the Vocab.
# ~Vocab.stoi-A collections.defaultdict instance mapping token strings to numerical identifiers.
# ~Vocab.itos-A list of token strings indexed by their numerical identifiers.
TEXT.build_vocab(train, max_size=MAX_VOCAB_SIZE)
print(f"vocabulary size:{len(TEXT.vocab)}")
VOCAB_SIZE = len(TEXT.vocab)
# backpropagation through time (BPTT)
train_iter, val_iter, test_iter = torchtext.data.BPTTIterator.splits((train, val, test), batch_size=BATCH_SIZE, device=device, bptt_len=50, repeat=False, shuffle=True)
1.1查看模型的输入和输出
模型的输入是一串文字,模型的输出也是一串文字,他们之间相差一个位置,因为语言模型的目标是根据之前的单词预测下一个单词。
it = iter(train_iter)
for i in range(5):
batch = next(it)
print(f"{i} text")
print(" ".join([TEXT.vocab.itos[i] for i in batch.text[:,0].data]))
print(f"{i} target")
print(" ".join([TEXT.vocab.itos[i] for i in batch.target[:,0].data]))
# 结果
0 text
anarchism originated as a term of abuse first used against early working class radicals including the diggers of the english revolution and the sans <unk> of the french revolution whilst the term is still used in a pejorative way to describe any act that used violent means to destroy the
0 target
originated as a term of abuse first used against early working class radicals including the diggers of the english revolution and the sans <unk> of the french revolution whilst the term is still used in a pejorative way to describe any act that used violent means to destroy the organization
1 text
organization of society it has also been taken up as a positive label by self defined anarchists the word anarchism is derived from the greek without archons ruler chief king anarchism as a political philosophy is the belief that rulers are unnecessary and should be abolished although there are differing
1 target
of society it has also been taken up as a positive label by self defined anarchists the word anarchism is derived from the greek without archons ruler chief king anarchism as a political philosophy is the belief that rulers are unnecessary and should be abolished although there are differing interpretations
2 text
interpretations of what this means anarchism also refers to related social movements that advocate the elimination of authoritarian institutions particularly the state the word anarchy as most anarchists use it does not imply chaos nihilism or <unk> but rather a harmonious anti authoritarian society in place of what are regarded
2 target
of what this means anarchism also refers to related social movements that advocate the elimination of authoritarian institutions particularly the state the word anarchy as most anarchists use it does not imply chaos nihilism or <unk> but rather a harmonious anti authoritarian society in place of what are regarded as
3 text
as authoritarian political structures and coercive economic institutions anarchists advocate social relations based upon voluntary association of autonomous individuals mutual aid and self governance while anarchism is most easily defined by what it is against anarchists also offer positive visions of what they believe to be a truly free society
3 target
authoritarian political structures and coercive economic institutions anarchists advocate social relations based upon voluntary association of autonomous individuals mutual aid and self governance while anarchism is most easily defined by what it is against anarchists also offer positive visions of what they believe to be a truly free society however
4 text
however ideas about how an anarchist society might work vary considerably especially with respect to economics there is also disagreement about how a free society might be brought about origins and predecessors kropotkin and others argue that before recorded history human society was organized on anarchist principles most anthropologists follow
4 target
ideas about how an anarchist society might work vary considerably especially with respect to economics there is also disagreement about how a free society might be brought about origins and predecessors kropotkin and others argue that before recorded history human society was organized on anarchist principles most anthropologists follow kropotkin
2. 定义模型
- 继承nn.Module
- 初始化函数
- forward函数
- 其余可以根据模型需要定义相关的函数
import torch
import torch.nn as nn
class RNNModel(nn.Module):
# 模型类型, 单词表长度,词向量长度,隐藏层单元数,循环层数目(一层还是多层),dropout
def __init__(self, rnn_type, ntoken, ninp, nhid, nlayers, dropout=0.5):
''' 模型参数
- rnn_type 模型类型,LSTM、GRU、RNN_TANH、RNN_RELU
- ntoken 单词表长度,本例为5002
- ninp 词向量长度(Embedding size)100
- nhid 隐藏层单元数
- nlayers 循环层数目
- dropout dropout率
该模型包含以下几层:
- 词嵌入层
- 一个循环神经网络层(RNN, LSTM, GRU)
- 一个线性层,从hidden state到输出单词表
- 一个dropout层,用来做regularization
'''
super(RNNModel, self).__init__()
self.drop = nn.Dropout(dropout)
# 编码层
self.encoder = nn.Embedding(ntoken, ninp) # [VOCAB_SIZE, EMBEDDING_SIZE]
if rnn_type in ['LSTM', 'GRU']: # 创建 LSTM 或 GRU 模型 对象
self.rnn = getattr(nn, rnn_type)(ninp, nhid, nlayers, dropout=dropout)
else:
# 选择基础RNN模型的激活函数
try:
nonlinearity = {'RNN_TANH': 'tanh', 'RNN_RELU': 'relu'}[rnn_type]
except KeyError:
raise ValueError( """An invalid option for `--model` was supplied,
options are ['LSTM', 'GRU', 'RNN_TANH' or 'RNN_RELU']""")
# 基础的RNN模型
self.rnn = nn.RNN(ninp, nhid, nlayers, nonlinearity=nonlinearity, dropout=dropout)
# 解码层
self.decoder = nn.Linear(nhid, ntoken)
self.init_weights()
self.rnn_type = rnn_type
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, input_text, hidden):
# emb [seq_len, batch, ninp]
emb = self.drop(self.encoder(input_text))
# output [seq_len, batch, num_directions * hidden_size]
# hidden ([nlayers, batch, nhid], [nlayers, batch, nhid]) (h_t, c_t) (隐藏层状态, 细胞状态)
output, hidden = self.rnn(emb, hidden)
output = self.drop(output)
# deocded [seq_len*batch, ntoken]
decoded = self.decoder(output.view(output.size(0)*output.size(1), output.size(2)))
# [seq_len, batch, ntoken]
return decoded.view(output.size(0), output.size(1), decoded.size(1)), hidden
def init_hidden(self, batch_size, requires_grad=True):
weight = next(self.parameters())
if self.rnn_type == 'LSTM':
return (weight.new_zeros((self.nlayers, batch_size, self.nhid), requires_grad=requires_grad),
weight.new_zeros((self.nlayers, batch_size, self.nhid), requires_grad=requires_grad))
else:
return weight.new_zeros((self.nlayers, batch_size, self.nhid), requires_grad=requires_grad)
2.1声明模型对象
model = RNNModel("LSTM", VOCAB_SIZE, EMBEDDING_SIZE, HIDDEN_SIZE, 2, dropout=0.5)
if USE_CUDA:
model = model.to(device)
查看模型结构
model
# 结果
RNNModel(
(drop): Dropout(p=0.5, inplace=False)
(encoder): Embedding(50002, 100)
(rnn): LSTM(100, 100, num_layers=2, dropout=0.5)
(decoder): Linear(in_features=100, out_features=50002, bias=True)
)
3.训练与评估
3.1 模型评估代码
- 我们首先定义评估模型的代码。
- 模型的评估和模型的训练逻辑基本相同,唯一的区别是我们只需要forward pass,不需要backward pass
def evaluate(model, data):
model.eval()
total_loss = 0
it = iter(data)
total_count = 0
with torch.no_grad():
hidden = model.init_hidden(BATCH_SIZE, requires_grad=False)
for i, batch in enumerate(it):
data, target = batch.text, batch.target
if USE_CUDA:
data, target = data.to(device), target.to(device)
output, hidden = model(data, hidden)
loss = loss_fn(output.view(-1, VOCAB_SIZE), target.view(-1))
total_count += np.multiply(*data.size())
total_loss += loss.item()*np.multiply(*data.size())
loss = total_loss/total_count
model.train()
return loss
定义下面的一个function,把一个hidden state和计算图之前的历史分离。
def repackage_hidden(h):
"""Wraps hidden states in new Tensors, to detach them from their history."""
if isinstance(h, torch.Tensor):
return h.detach()
else:
return tuple(repackage_hidden(v) for v in h)
3.2 定义loss function和optimizer
loss_fn = nn.CrossEntropyLoss()
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, 0.5)
3.3 训练模型:
- 模型一般需要训练若干个epoch
- 每个epoch我们都把所有的数据分成若干个batch
- 把每个batch的输入和输出都包装成cuda tensor
- forward pass,通过输入的句子预测每个单词的下一个单词
- 用模型的预测和正确的下一个单词计算cross entropy loss
- 清空模型当前gradient
- backward pass
- gradient clipping,防止梯度爆炸
- 更新模型参数
- 每隔一定的iteration输出模型在当前iteration的loss,以及在验证集上做模型的评估
import copy
GRAD_CLIP = 1.
NUM_EPOCHS = 2
val_losses = []
for epoch in range(NUM_EPOCHS):
model.train()
it = iter(train_iter)
hidden = model.init_hidden(BATCH_SIZE)
for i, batch in enumerate(it):
text, target = batch.text, batch.target
hidden = repackage_hidden(hidden)
#
optimizer.zero_grad()
output, hidden = model(text, hidden)
loss = loss_fn(output.view(-1, VOCAB_SIZE), target.view(-1))
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), GRAD_CLIP)
optimizer.step()
#
if i % 3 ==0:
print(f"epoch {epoch} batch {i} loss: {loss.item()}")
if i%5==0:
val_loss = evaluate(model, val_iter)
if len(val_losses)==0 or val_loss < min(val_losses):
print(f'save best model, val loss is {val_loss}')
torch.save(model.state_dict(), 'lm_best.pth')
else:
print(f"parameters decay")
scheduler.step()
val_losses.append(val_loss)
训练结果展示
epoch 0 batch 0 loss: 10.822463035583496
save best model, val loss is 10.815159148365922
epoch 0 batch 3 loss: 10.799246788024902
save best model, val loss is 10.769979389708967
epoch 0 batch 6 loss: 10.769998550415039
epoch 0 batch 9 loss: 10.713444709777832
save best model, val loss is 10.637265799769702
epoch 0 batch 12 loss: 10.571533203125
epoch 0 batch 15 loss: 10.1561279296875
save best model, val loss is 9.966347007765822
epoch 0 batch 18 loss: 9.652090072631836
....
4. 加载模型参数
在训练时,保存了最优的模型参数,在使用时通过下面代码加载
model.load_state_dict(torch.load('lm_best.pth'))
4.1 评估valid数据
使用最好的模型在valid数据上计算perplexity
val_loss = evaluate(best_model, val_iter)
print("perplexity: ", np.exp(val_loss))
4.2 评估test数据
test_loss = evaluate(best_model, test_iter)
print("perplexity: ", np.exp(test_loss))
4.3 生成模型测试
hidden = best_model.init_hidden(1)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
input = torch.randint(VOCAB_SIZE, (1, 1), dtype=torch.long).to(device)
words = []
for i in range(100):
output, hidden = best_model(input, hidden)
word_weights = output.squeeze().exp().cpu()
word_idx = torch.multinomial(word_weights, 1)[0]
input.fill_(word_idx)
word = TEXT.vocab.itos[word_idx]
words.append(word)
print(" ".join(words))
# 结果 训练效果足够好的话,可以生成很棒的结果
models and windward <unk> and labor listed significant monuments some generation from the ship process in two zero zero zero recommend in history of lorenz one six zero zero two malicious than varieties including <unk> and tea language <unk> of animals or printers in chr <unk> s minor and gods preferred order for vector parallel the twelfth gibbon bar is g the gr follows pv to fund it worshipped to store ceilings in europe the german <unk> greek bond hosea was only uncertain to warmed publicly severe rolfe up u s often a tissue from the peters divisions the bengals