消费者行为分析(Python+numpy+matplot+pandas)
1. 数据和需求
数据来源CDNow网站的用户购买明细,
主要包括以下几个字段:
- user_id 用户ID
- order_date 购买日期
- order_products 购买产品数
- order_amount 购买金额
消费者行为分析需求如下:
-
用户消费趋势分析
- 每月的消费总金额
- 每月的消费次数
- 每月的产品购买量
- 每月的消费人数
-
用户个体消费行为分析
- 用户消费金额和消费总数的描述统计
- 用户消费金额和消费总数的散点图
- 用户消费金额和消费总数的分布图
- 用户累计消费金额的占比
-
用户消费行为分析
- 用户第一次消费时间(用户首次购买产品的时间)
- 用户最后一次消费时间
- 新老客消费占比
- 用户分层(RFM模型)
2. 工具
jupyter notebook + python + numpy + pandas + matplotlib
3. 数据预处理
3.1 读取数据
import pandas as pd
columns = ['user_id','order_date','order_products','order_amount']
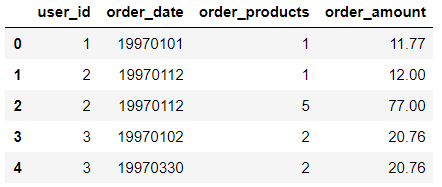
df = pd.read_csv('CDNOW_master.txt',names=columns,sep='\s+') # 分隔符用\s+表示匹配任意空白符。
df.head()
3.2 数据预处理
3.2.1 检查是否有空值,如果有需要清洗。
(代码检查没有空值)
df.isnull().any()
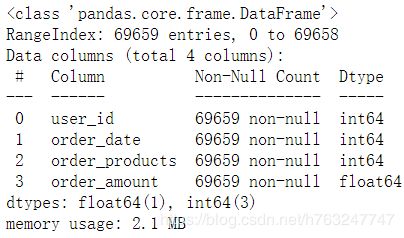
3.2.2 检查数据类型是否需要处理
df.info()
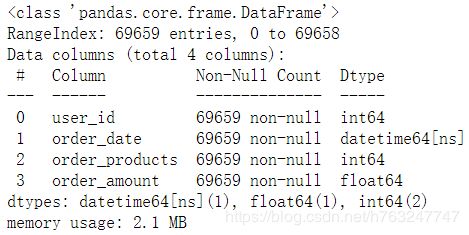
order_date 数据类型为int, 需要转成日期类型
df['order_date'] = pd.to_datetime(df['order_date'],format='%Y%m%d')
df.info()
3.2.3 查看数据的统计描述
df.describe()
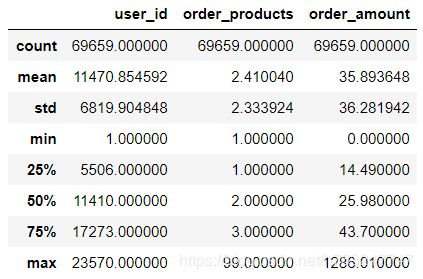
从用户购买的商品数来看,平均每位用户购买2.4个商品,标准差在2.3左右,最少买1个,最多买99个,中位数为2,3/4分位数为3,说明了大多数的订单量都不多。中位数<均值,结合众数可以发现,用户购买的商品数分布是属于右偏分布的。
从用户购买的金额来看,每个用户贡献的平均金额为36,而最大值达到了1286。
3.2.4 添加列
为了处理方便,在数据中添加一列,月份
df['month']=df['order_date'].values.astype('datetime64[M]')
df.head()
4. 数据分析
4.1 用户消费的趋势分析
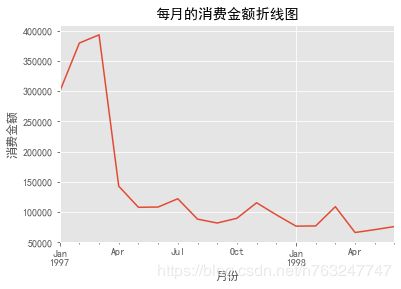
4.1.1 每月的消费总金额随时间变化
横坐标为月份,纵坐标为每月的消费总金额之和
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
% matplotlib inline
plt.style.use('ggplot')
group_month_amount.plot()
plt.xlabel('月份')
plt.ylabel('消费金额')
plt.title('每月的消费金额折线图')
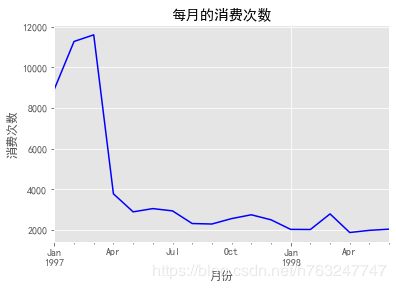
4.1.2 每月的消费次数随时间变化
按月分组后,对消费次数进行求和
group_month_count = group_month['order_products'].count()
group_month_count.plot(color='blue')
plt.xlabel('月份')
plt.ylabel('消费次数')
plt.title('每月的消费次数')
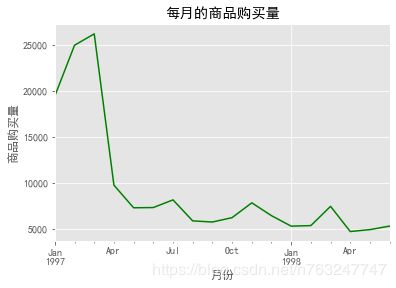
4.1.3 每月购买的商品数量随时间变化
group_month_product = group_month['order_products'].sum()
group_month_product.plot(color='green')
plt.xlabel('月份')
plt.ylabel('商品购买量')
plt.title('每月的商品购买量')
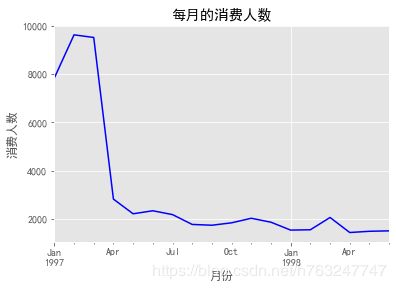
4.1.4 每月的消费人数随时间变化
df.groupby('month').user_id.nunique().plot(color='blue')
plt.xlabel('月份')
plt.ylabel('消费人数')
plt.title('每月的消费人数')
4.2 用户群体消费行为分析
4.2.1 用户群体消费金额和消费总数的散点图
group_user = df.groupby('user_id')
plt.scatter(group_user.sum()['order_amount'],group_user.sum()['order_products'],c='green')
plt.xlabel('消费金额')
plt.ylabel('消费总数')
plt.title('用户消费金额和消费总数的散点图')
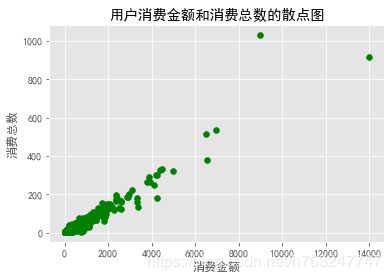
从图中可以看出,数据中存在极少的极值点,为了减少极值点对数据分析的影像,去掉这些极值点。
group_user_sum = group_user.sum().query('order_amount<6000')
plt.scatter(group_user_sum['order_amount'],group_user_sum['order_products'],c='red')
plt.xlabel('消费金额')
plt.ylabel('消费总数')
plt.title('用户消费金额和消费总数的散点图')
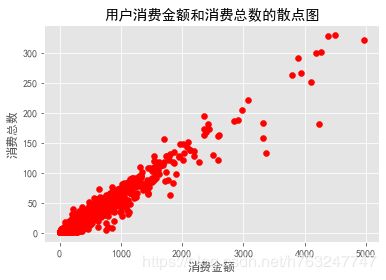 从图中可以看出,用户的消费金额和消费总数存在正相关
从图中可以看出,用户的消费金额和消费总数存在正相关
4.2.2 用户群体消费金额和消费总数的分布图
plt.figure(figsize=(16,9))
plt.subplot(2,2,1)
group_user_sum = group_user.sum().query('order_amount<6000')
plt.hist(group_user_sum['order_amount'],bins=40,color='green')
plt.xlabel('order_amount')
plt.ylabel('frequency')
plt.title('用户消费金额的分布图')
plt.subplot(2,2,2)
group_user_sum = group_user.sum().query('order_products<100')
plt.hist(group_user_sum['order_amount'],bins=40,color='red')
plt.xlabel('order_products')
plt.ylabel('frequency')
plt.title('用户消费总数的分布图')
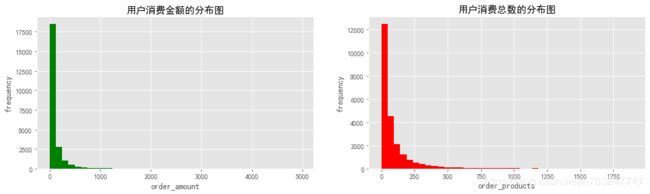 从上图可以看出,用户消费金额的分布和用户消费总数的分布都是符合右偏分布,和描述性统计结果一致。
从上图可以看出,用户消费金额的分布和用户消费总数的分布都是符合右偏分布,和描述性统计结果一致。
4.2.3 新用户变化
group_user.min()['order_date'].value_counts().plot() # value_counts()根据日期进行计数
plt.xlabel('时间')
plt.ylabel('新用户数')
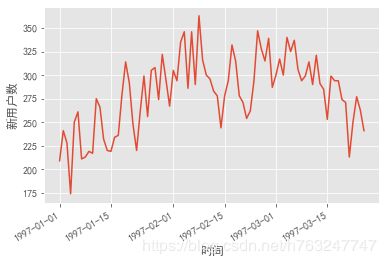
新用户出现剧烈变化,什么原因导致,促销?行业周期?
4.2.4 最后一次消费时间
group_user.max().order_date.value_counts().plot(color='green')
plt.xlabel('用户最后一次消费时间')
plt.ylabel('用户数')
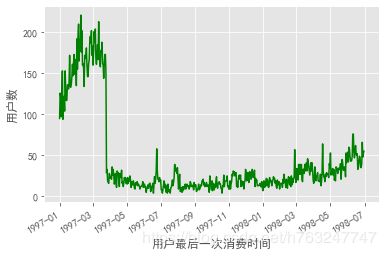
大部分用户最后购买集中在前三个月,很多用户买了之后就不再购买了。
4.2.5 新老客户消费比较
group_month_user = df.groupby(['month','user_id'])
user_life_month = group_month_user['order_date'].agg(['min','max'])
(user_life_month['min'] == user_life_month['max']).value_counts()
新客为46727人,而老客人数为8652人,做一次生意居多,什么原因?服务?价格?
4.3 用户分层
用RFM模型可以对用户再进行细分,分为低价值用户、高价值用户,针对不同的用户群体开展不同的个性化服务,将有限的资源合理地分配给不同价值的客户,实现效益最大化。
- R:recency 最近一次消费时间,理论上R值越小,价值越高;
- F:frequency最近一次消费频率,消费频率越高意味着这部分用户对产品的满意度越高,用户粘性比较好,忠诚度也高;
- M:Money 最近一段时间消费的金额
import numpy as np
# 建立数据透视表
rfm = df.pivot_table(
index='user_id',
values= ['order_products','order_amount','order_date'],
aggfunc={
'order_products': 'count',
'order_amount': 'sum',
'order_date': 'max'
})
# 计算R是使用当前时间-最近一次时间,但是由于这个数据比较老,隔的时间比较久远,故用最大时间来代替
rfm['R'] = (rfm['order_date'].max() - rfm['order_date']) / np.timedelta64(1,'D') # np.timedelta64(1,'D')是为了消除单位
rfm.rename(columns={'order_amount':'M','order_products':'F'},inplace=True)
rfm.head()
rfm1 = rfm[['R','F','M']].apply(lambda x: x-x.mean())
def rfm_func(x):
level = x.apply(lambda x:'1' if x>= 1 else '0') # 根据计算的RFM的数值,如果大于1,则标记为1,如果小于1则标记为0
label = level['R'] + level['F'] +level['M'] # 根据上述的标记,将标记合并则得到每位用户的标签,如用户ID为1的用户的标签为100
# 根据各个用户标签,将用户进行分群
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般发展客户',
'000':'一般挽留客户'
}
result = d[label] # 将用户标签对应到具体的用户分群中
return result
rfm['label'] = rfm1.apply(rfm_func,axis=1)
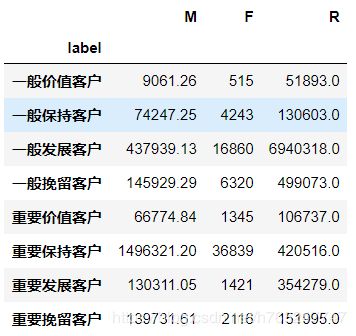
# 针对客户类别进行分组
rfm.groupby('label').sum()
rfm.loc[rfm['label']=='重要价值客户','color'] = 'g' # 设置颜色
rfm.loc[~(rfm['label']=='重要价值客户'),'color'] = 'r'
plt.scatter(rfm['R'],rfm['F'],c=rfm.color)
plt.xlabel('R')
plt.ylabel('F')
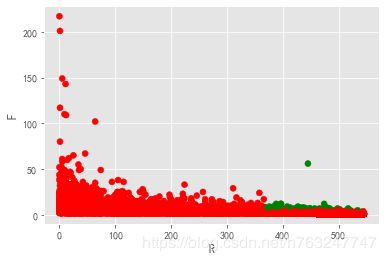
从RFM分层可知,大部分客户为重要保持客户。