代码GitHub地址
树
无论是链表,栈还是队列,它们都是线性结构的,每个节点的左边最多一个节点,右边也最多一个节点。对于大量的输入数据,线性表的访问时间太长,效率较低,不宜使用。
因此需要一种非线性的数据结构,树型结构,其大部分操作的运行时间平均为O(logN)。
线性结构可以理解为树的一种特殊表现形式。
关于树的一些术语
- 节点的度:一个节点含有的子树的个数称为该节点的度,树的度是树内各节点的度的最大值
- 叶节点或终端节点:度为零的节点称为叶节点;
- 非终端节点或分支节点:度不为零的节点;
- 双亲节点或父节点:若一个结点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 树的高度或深度:定义一棵树的根结点层次为1,其他节点的层次是其父结点层次加1。一棵树中所有结点的层次的最大值称为这棵树的深度。
- 节点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推;
- 树的度:一棵树中,最大的节点的度称为树的度;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由m(m>=0)棵互不相交的树的集合称为森林;
树的应用
大部分操作系统的目录结构就是采用树结构。树的种类有很多,树所扩展出来的很多数据结构都有着很大的作用,比如说红黑树,B树,后缀树等等。
树的表示方法
-
双亲表示法 [找父亲,找孩子]
- 优点:很容易定位某个节点的双亲节点。时间复杂度
O(1) - 缺点:如果想知道该节点的孩子节点。必须遍历整个结构才知道
- 解决办法:为节点新增一个长子域(指向节点的左孩子)。如果没有设为
-1。
- 优点:很容易定位某个节点的双亲节点。时间复杂度
-
孩子表示法
- 具体办法:把每个节点的孩子节点排列起来,以单链表作存储结构,则n个节点有n个孩子链表,如果是叶子节点则此单链表为空。然后n个节点有n个孩子链表,如果是叶子节点则此单链表为空。然后n个头指针又组成一个线性表,采用顺序存储结构。存放进一个一维数组
- 优点:既可以让我们找到节点的孩子也可以找到节点的兄弟。
- 缺点,父亲还是找不到
-
孩子兄弟表示法
- 具体办法:每个节点具有
data属性以及firstchild和rightsib的两个属性。这样就可以方便的找到某个节点的兄弟节点以及孩子节点,但在寻找其双亲节点的时候任然有难度。但其实只要再多加一个指针即可。 - 优点:最大的优点或许就是这种表示法把这棵树变成了一颗二叉树。
- 具体办法:每个节点具有
需要注意的是:节点并不是包含的数据域越多越好,这由整个算法适用的整体情况来定。毕竟属性多了,内存占用也大。
二叉树
二叉树是树形结构的一个重要类型。
许多实际问题抽象出来的数据结构往往是二叉树的形式,即使是一般的树也能简单地转换为二叉树,比如在某个阶段都是两种结果的情形,比如开和关,0和1,真和假等都适合用二叉树来建模。而且二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。
需要注意的是:二叉树的左子树和右子树是严格区分并且不能随意颠倒的
二叉树种类
- 斜二叉树
- 满二叉树
- 完全二叉树
一般二叉树的实现都是基于链表而来。顺序存储结构一般只用于完全二叉树。我们一般判断是否适合的判断方法是,能否方便的找到节点的孩子节点,双亲节点。有时一般二叉树也可以使用顺序结构存储,只是我们需要将树种缺少的节点补齐。这是一种以空间换时间的方式
二叉树实现
二叉树中每个节点都有两个节点指针属性,分别指向其左孩子和右孩子节点。如果想找寻其双亲节点只要再添加一个指向其双亲节点的属性即可,这样就成了三叉树了,和之前我们说过的树结构一样了。
二叉树操作集
二叉树重要操作有:
- 判断非空
- 遍历
- 创建一个二叉树
遍历方式:
环绕节点
- 前序:先根,再左,后右 (第一次碰到节点时push出来)
- 中序:先左,再根,后右 (第二次碰到节点时push出来)
- 后序:先左,再右,后根 (第三次碰到节点时push出来)
- 层序:从上到下逐层遍历,同一层中从左到右逐个访问。
在通过两种序列确定一棵树结构的时候,必须至少具有中序遍历。
遍历
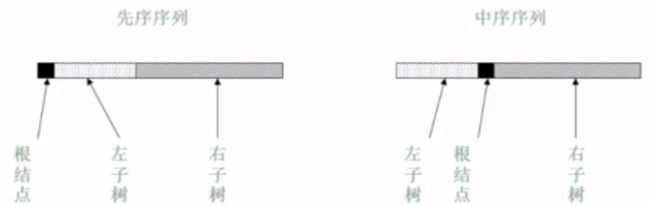
前序遍历
/**
* 前序遍历
* 中 左 右
*
* @param binaryTree
* @return
*/
public static void preOrderTraverse(BinaryTree binaryTree) {
if (binaryTree == null) {
return;
}
System.out.println(binaryTree.value);
preOrderTraverse(binaryTree.lchild);
preOrderTraverse(binaryTree.rchild);
}
/**
* 非递归前序遍历
*
* @param binaryTree
*/
public static void nonRecursivepreOrderTraverse(BinaryTree binaryTree) {
BinaryTree tree;
Stack stack = new Stack();
while (binaryTree != null || !stack.empty()) {
while (binaryTree != null) {
stack.push(binaryTree);
System.out.println(binaryTree.value);
binaryTree = binaryTree.lchild;
}
if (!stack.empty()) {
tree = (BinaryTree) stack.pop();
binaryTree = tree.rchild;
}
}
}
递归方法的三序遍历都很简单。非递归方式的前序遍历,只要想成入栈操作即可。只是节点的孩子节点在入栈的时候是先入右孩子再入左孩子。
中序遍历
/**
* 中序遍历
* 左 中 右
*
* @param binaryTree
*/
public static void inOrderTraverse(BinaryTree binaryTree) {
if (binaryTree == null) {
return;
}
inOrderTraverse(binaryTree.lchild);
System.out.println(binaryTree.value);
inOrderTraverse(binaryTree.rchild);
}
/**
* 非递归中序遍历 - 栈
*
* @param binaryTree
*/
public static void nonRecursiveInOrderTraverse(BinaryTree binaryTree) {
BinaryTree tree;
Stack stack = new Stack();
while (binaryTree != null || !stack.empty()) {
while (binaryTree != null) {
stack.push(binaryTree);
binaryTree = binaryTree.lchild;
}
if (!stack.empty()) {
tree = (BinaryTree) stack.pop();
System.out.println(tree.value);
binaryTree = binaryTree.rchild;
}
}
}
需要注意的是,三序遍历的区别无非第几次碰到时打印。
- 递归方式的实现思路很简单不赘述了。
- 非递归的原理还是递归。表示手法变了而已,需要注意的是别漏了
stack的判断,严谨一点儿比较好。
流程:
- 判断 - 是否空树或者栈满了
- 循环 - 在数不为空的情况下,循环push当前树的左子树。
- 判断 - 如果栈不为空,pop出栈顶元素并打印,切换到该树的右子树继续。
后序遍历
/**
* 后序遍历
* 左 右 中
*
* @param binaryTree
*/
public static void postOrderTraverse(BinaryTree binaryTree) {
if (binaryTree == null) {
return;
}
postOrderTraverse(binaryTree.lchild);
postOrderTraverse(binaryTree.rchild);
System.out.println(binaryTree.value);
}
层序遍历
/**
* 层序遍历
*
* @param binaryTree
*/
public static void theSequenceTraverse(BinaryTree binaryTree) {
if (binaryTree == null) {
return;
}
ArrayBlockingQueue queue = new ArrayBlockingQueue(10);
BinaryTree tree;
queue.add(binaryTree.value);
while (!queue.isEmpty()) {
tree = (BinaryTree) queue.remove();
System.out.println(tree.value);
if (tree.lchild != null) {
queue.add(tree.lchild);
}
if (tree.rchild != null) {
queue.add(tree.rchild);
}
}
}
层序这里我们使用了队列的方式进行打印更简单一些。每个节点push进去然后每次打印头节点,打印出来的头结点再把左右孩子节点分别push进去等待remove即可。利用队列存储规则
打印所有叶子节点
/**
* 输出一颗二叉树的所有叶子节点
*
* @param binaryTree
*/
public static void pushLeafnode(BinaryTree binaryTree) {
if (binaryTree == null) {
return;
}
if (binaryTree.lchild == null && binaryTree.rchild == null) {
System.out.println(binaryTree.value);
}
pushLeafnode(binaryTree.lchild);
pushLeafnode(binaryTree.rchild);
}
递归实现。在任意一种遍历前加一个判断语句打印即可。只要一个节点不存在左右孩子那么即是leafnode。
计算二叉树高度
/**
* 计算二叉树高度
*
* @param binaryTree
* @return
*/
public static int high(BinaryTree binaryTree) {
int maxHigh;
int leftHigh;
int rightHigh;
if (binaryTree != null) {
leftHigh = high(binaryTree.lchild);
rightHigh = high(binaryTree.rchild);
maxHigh = leftHigh > rightHigh ? leftHigh : rightHigh;
return maxHigh + 1;
}
return 0;
}
借用后序遍历处理逻辑。在递归左右子树的时候,把原先的打印换成比较大小即可。
二叉搜索树
二叉搜索树利用了二分查找的原理。之前我们说的二分查找树是基于数组的,虽然查找迅速,但是面临着插入和删除上的不便。所以我们可以把这种思路通过二叉树来实现。
- 二叉搜索树任意节点的左叶子节点都小于该节点。右叶子节点都大于该节点。
二叉搜索树操作集
查找某一节点地址
/**
* 二叉搜索树查找某一节点(尾递归)
*
* @return
*/
public static BinaryTree recursiveFind(BinaryTree binaryTree, int value) {
if (binaryTree == null) {
return null;
}
if (value > binaryTree.value) {
return recursiveFind(binaryTree.rchild, value);
}
if (value < binaryTree.value) {
return recursiveFind(binaryTree.lchild, value);
}
return binaryTree;
}
/**
* 二叉搜索树查找某一节点(迭代)
*
* @param binaryTree
* @param value
* @return
*/
public static BinaryTree ineratorFind(BinaryTree binaryTree, int value) {
if (binaryTree == null) {
return null;
}
while (binaryTree != null) {
if (value > binaryTree.value) {
binaryTree = binaryTree.rchild;
} else if (value < binaryTree.value) {
binaryTree = binaryTree.lchild
} else {
return binaryTree;
}
}
return null;
}
查找某一节点的算法利用的是递归的方式,而且可以看出来是尾递归。所以可以优化成循环的方式,但是这种尾递归的算法,现如今编译器在编译的时候已经可以给我们优化成循环的算法。所以递归的写法还是最好的,因为看上去简洁明了。
- 这种算法的查找效率取决于树的高度。如果该树是个斜树的话那么时间复杂度即是
O(n),否则即是O(log n)
查找最小元素地址
/**
* 查找二叉搜索树中最小元素
* 非递归
*
* @param binaryTree
* @return
*/
public static BinaryTree nonRecursiveFindMin(BinaryTree binaryTree) {
if (binaryTree == null) {
return null;
}
while (binaryTree.lchild != null) {
binaryTree = binaryTree.lchild;
}
return binaryTree;
}
/**
* 查找二叉搜索树中最小元素
* 递归
*
* @param binaryTree
* @return
*/
public static BinaryTree recursiveFindMin(BinaryTree binaryTree) {
if (binaryTree == null) {
return null;
}
// 真正退出递归的条件
if (binaryTree.lchild == null) {
return binaryTree;
}
return recursiveFindMin(binaryTree.lchild);
}
查找最大元素地址
/**
* 查找二叉搜索树中最大元素
* 非递归
*
* @param binaryTree
* @return
*/
public static BinaryTree nonRecursiveFindMax(BinaryTree binaryTree) {
if (binaryTree == null) {
return null;
}
while (binaryTree.rchild != null) {
binaryTree = binaryTree.rchild;
}
return binaryTree;
}
/**
* 查找二叉搜索树中最大元素
* 递归
*
* @param binaryTree
* @return
*/
public static BinaryTree recursiveFindMax(BinaryTree binaryTree) {
if (binaryTree == null) {
return null;
}
if (binaryTree.rchild == null) {
return binaryTree;
}
return recursiveFindMax(binaryTree.rchild);
}
插入元素
/**
* 二叉搜索树插入节点
*
* @param binaryTree
* @param value
* @return
*/
public static BinaryTree insert(BinaryTree binaryTree, int value) {
if (binaryTree == null) {
binaryTree = new BinaryTree();
binaryTree.value = value;
binaryTree.lchild = null;
binaryTree.rchild = null;
} else if (value > binaryTree.value) {
binaryTree.rchild = insert(binaryTree.rchild, value);
} else if (value < binaryTree.value) {
binaryTree.lchild = insert(binaryTree.lchild, value);
}
// 递归时分析清楚,该层返回的内容 对于上层是什么
return binaryTree;
}
插入时我们没有判断插入已有节点的情况。
同时插入节点时只要清楚,我们最终要插入的位置肯定是一个空的位置。我们只是要定位这个空的位置
删除元素
/**
* 二叉搜索树删除节点
*
* @param binaryTree
* @param value
* @return
*/
public static BinaryTree remove(BinaryTree binaryTree, int value) {
if (binaryTree == null) {
return null;
}
if (value < binaryTree.value) {
binaryTree.lchild = remove(binaryTree.lchild, value);
} else if (value > binaryTree.value) {
binaryTree.rchild = remove(binaryTree.rchild, value);
} else {
if (binaryTree.lchild != null && binaryTree.rchild != null) {
// 右子树找最小,左子树找最大
BinaryTree tempTree = nonRecursiveFindMin(binaryTree.rchild);
// 替换找到的节点的值,然后牺牲掉给值的节点。
binaryTree.value = tempTree.value;
binaryTree.rchild = remove(binaryTree.rchild, tempTree.value);
} else {
if (binaryTree.lchild == null) {
binaryTree = binaryTree.rchild;
} else if (binaryTree.rchild == null) {
binaryTree = binaryTree.lchild;
}
}
}
return binaryTree;
}
待删除节点有两个孩子节点时:
- 我们从其左子树找到最大节点,或者从其右子树找到最小节点。因为二叉搜索树的性质,找到右子树最小元素后拿出其
value来赋予待删除节点。然后再把这个最小节点通过特定值搜索删除即可。然后我们再把这个被修改过value得待删除节点binaryTree返回给其双亲节点。虽然其没有被删除只是被改值了,但是也是达到了删除节点的目的。只是删除了另一个替代节点
待删除节点只有一个孩子节点时:
- 我们对二叉树种某一节点删除操作其实就是把其双亲节点对其的指向改变。由于函数调用外层已经用双亲节点的孩子指针来指向返回值,所以我们只需要找到待删除节点并且把其替代节点覆盖的赋予
binartTree并返回即可。
二叉搜索树的节点删除有两种策略:
- 可以取右子树中最小元素(没有左子树)或者左子树中的最大元素(没有右子树)来替换该被删除节点的位置,因为这两个节点都不可能有两个儿子,这样在将选取的节点来填补被删除节点的时候,如果我们选择的是右边,那么我们只需要保留原删除节点的左子树。重置其右子树即可。
平衡二叉树(AVL树)
在二叉搜索树中我们前面也说过,该数据结构算法的时间复杂度十分依赖树的结构。不同排列顺序的节点顺序可以形成不同的搜索树。将导致不同的深度和平均查找长度(ASL)。所以一个树是否左右平衡,是否是一个平衡二叉树,对于二叉搜索树的查找策略将十分重要
概念:
- 任意一棵树的左右子树高度差不超过1。
平衡二叉树的调整
平衡二叉树的数据结构模型固然对我们搜索算法效率提升很高。但是也一定有需要克服的问题。即如果我们在进行插入删除的时候把一个原本平衡的二叉树变得不平衡了怎么办的问题。
- 左单旋(RR旋转):破坏节点在被破坏节点右子树的右子树上
- 右单旋(LL旋转):破坏节点在被破坏节点左子树的左子树上
- 左右旋转(LR旋转):破坏节点在被破坏节点左子树的右子树上
- 右左旋转(RL旋转):破坏节点在被破坏节点右子树的左子树上
- 提点:需要做左单旋操作那么即提被破坏节点的左儿子节点作为父亲节点,然后被破坏节点作为该节点的右儿子节点。如果需要做右单旋操作那么即提被破坏节点的右儿子节点作为父亲节点,然后被破坏节点作为该节点的左儿子节点。
我们在判断应该做什么旋转操作的时候应该先考虑好,破坏节点和被破坏节点的关系。同时一定要记住它是一颗查找树,必须要保证左边小右边大这一准则。
递归心得
可以看到在树结构的算法中,我们用到了很多递归的想法。这里我总结了一些关于递归的使用心得。
- 在写递归函数时,处理掉特殊情况。设定好最深层返回条件
- 被递归的函数在调用它时当成既有函数来使用,不要在意细节。只要想着,这个被递归的函数能为你做什么即可。然后你只需要调用它并且给他传递参数即可。
- 多想着递归函数的参数和返回值是什么。有什么意义
- 要想清楚递归函数的返回值对于上一层递归时什么意义。