python 实现 模板模式
本文的目录地址
本文的代码地址
编写优秀代码的一个要素是避免冗余。在面向对象编程中,方法和函数是我们用来避免编写冗余代码的重要工具。回想策略模式中的sorted()例子。sorted()函数非常通用,可使用任意键来对多种数据结构(列表、元组和命名元组等)进行排序。这是一个良好函数的定义。
sorted()这样的函数属于理想的案例。现实中,我们没法始终写出100%通用的代码。许多算法都有一些(但并非全部)通用步骤。广度优先搜索(Breadth-First Search,BFS)和深度优先搜索(Depth-First Search,DFS)是其中不错的例子,这两个流行的算法应用于图搜索问题。起初,我们提出独立实现两个算法(文件graph.py)。函数bfs()和dfs()在start和end之间存在一条路径时返回一个元组(True, path);如果路径不存在,则返回(False, path)(此时,path为空)。
注意两个算法之间的相似点。仅有一处不同,其余部分完全相同。
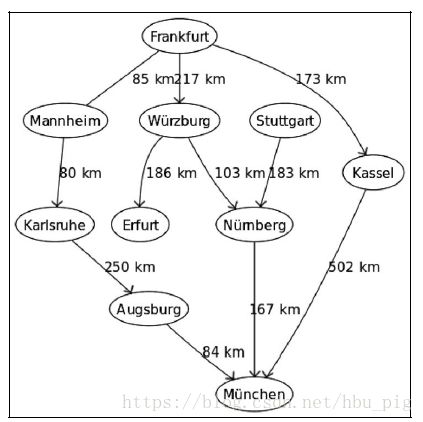
先使用Wikipedia提供的图来测试算法。为了简化,假设该图是有向的。这意味着只能朝一个方向移动,我们可以检测如何从Frankfurt到Mannheim,而不是另一个方向。
可以使用列表的字典结构来表示这个有向图。每个城市是字典中的一个键,列表的内容是从该城市始发的所有可能目的地。叶子顶点的城市(例如,Erfurt)使用一个空列表即可(无目的地)。
#encoding:utf-8
def bfs(graph,start,end):
path=[]
visited=[start]
while visited:
current=visited.pop(0)
if current not in path:
path.append(current)
if current==end:
print(path)
return (True,path)
if current not in graph:
continue
visited=visited+graph[current]
return (False,path)
def dfs(graph, start, end):
path = []
visited = [start]
while visited:
current = visited.pop(0)
if current not in path:
path.append(current)
if current == end:
print(path)
return (True, path)
# 两个顶点不相连,则跳过
if current not in graph:
continue
visited = graph[current] + visited
return (False, path)
def main():
graph = {
'Frankfurt': ['Mannheim', 'Wurzburg', 'Kassel'],
'Mannheim': ['Karlsruhe'],
'Karlsruhe': ['Augsburg'],
'Augsburg': ['Munchen'],
'Wurzburg': ['Erfurt', 'Nurnberg'],
'Nurnberg': ['Stuttgart', 'Munchen'],
'Kassel': ['Munchen'],
'Erfurt': [],
'Stuttgart': [],
'Munchen': []
}
bfs_path = bfs(graph, 'Frankfurt', 'Nurnberg')
dfs_path = dfs(graph, 'Frankfurt', 'Nurnberg')
print('bfs Frankfurt-Nurnberg: {}'.format(bfs_path[1] if bfs_path[0] else 'Not found'))
print('dfs Frankfurt-Nurnberg: {}'.format(dfs_path[1] if dfs_path[0] else 'Not found'))
bfs_nopath = bfs(graph, 'Wurzburg', 'Kassel')
print('bfs Wurzburg-Kassel: {}'.format(bfs_nopath[1] if bfs_nopath[0] else 'Not found'))
dfs_nopath = dfs(graph, 'Wurzburg', 'Kassel')
print('dfs Wurzburg-Kassel: {}'.format(dfs_nopath[1] if dfs_nopath[0] else 'Not found'))
if __name__ == '__main__':
main()
'''
Output:
['Frankfurt', 'Mannheim', 'Wurzburg', 'Kassel', 'Karlsruhe', 'Erfurt', 'Nurnberg']
['Frankfurt', 'Mannheim', 'Karlsruhe', 'Augsburg', 'Munchen', 'Wurzburg', 'Erfurt', 'Nurnberg']
bfs Frankfurt-Nurnberg: ['Frankfurt', 'Mannheim', 'Wurzburg', 'Kassel', 'Karlsruhe', 'Erfurt', 'Nurnberg']
dfs Frankfurt-Nurnberg: ['Frankfurt', 'Mannheim', 'Karlsruhe', 'Augsburg', 'Munchen', 'Wurzburg', 'Erfurt', 'Nurnberg']
bfs Wurzburg-Kassel: Not found
dfs Wurzburg-Kassel: Not found
'''从性质来看,结果并不能表明什么,因为DFS和BFS不能很好地处理加权图(权重完全被忽略了)。处理加权图更好的算法是(Dijkstra的)最短路径优先算法、Bellman-Ford算法和A*算法等。然而,我们仍然希望按打算的那样遍历图。我们期望的算法输出是一个城市列表,这些城市是在搜索从Frankfurt到Nurnberg的路径时访问过的。
结果看起来没问题。BFS按广度进行遍历,DFS则按深度进行遍历,两个算法都没返回任何非期望的结果。这样不错,但我们的代码仍然有一个问题,那就是冗余。两个算法之间仅有一处不同,但其余代码都写了两遍。对于这个问题我们能做点什么吗?
是的!这个问题可以通过模板设计模式(Template design pattern)来解决。这个模式关注的是消除代码冗余,其思想是我们应该无需改变算法结构就能重新定义一个算法的某些部分。为了避免重复而进行必要的重构之后,我们来看看代码会变成什么样子(文件graph_template.py)
def traverse(graph, start, end, action):
path = []
visited = [start]
while visited:
current = visited.pop(0)
if current not in path:
path.append(current)
if current == end:
return (True, path)
# 两个顶点不相连,则跳过
if current not in graph:
continue
visited = action(visited, graph[current])
return (False, path)
def extend_bfs_path(visited, current):
return visited + current
def extend_dfs_path(visited, current):
return current + visited不再有bfs()和dfs()两个函数,我们将代码重构为使用单个traverse()函数。traverse()函数实际上是一个模板函数。它接受一个参数action,该参数是一个“知道”如何延伸路径的函数。根据要使用的算法,我们可以传递extend_bfs_path()或extend_dfs_path()作为目标动作。
你也许会争论说,通过在traverse()内部添加一个条件来检测应该使用哪个遍历算法,也能达到相同的结果。下面的代码展示了这个思路(文件graph_template_slower.py)。
BFS = 1
DFS = 2
def traverse(graph, start, end, algorithm):
path = []
visited = [start]
while visited:
current = visited.pop(0)
if current not in path:
path.append(current)
if current == end:
return (True, path)
# 顶点不相连,则跳过
if current not in graph:
continue
if algorithm == BFS:
visited = extend_bfs_path(visited, graph[current])
elif algorithm == DFS:
visited = extend_dfs_path(visited, graph[current])
else:
raise ValueError("No such algorithm")
return (False, path)我不喜欢这个方案,有以下几个原因。
- 它使得traverse()难以维护。如果添加第三种方式来延伸路径,就需要扩展traverse()的代码,再添加一个条件来检测是否使用新的路径延伸动作。更好的方案是traverse()能发挥作用却好像根本不知道应该执行哪个action,因为这样在traverse()中不要求什么特殊逻辑。
- 它仅对只有一行区别的算法有效。如果存在更多区别,那么与让本应归属action的具体细节污染traverse()函数相比,创建一个新函数会好得多
- 它使得traverse()更慢。这是因为每次traverse()执行时,都需要显式地检测应该执行哪个遍历函数
目录
1.1现实生活的例子
1.2应用案例
1.3实现
1.4小结
1.1现实生活的例子
工人的日程,特别是对于同一个公司的工人而言,非常接近于模板设计模式。所有工人都遵从或多或少相同的例行流程,但例行流程的某些特定部分区别又很大

1.2应用案例
模板设计模式旨在消除代码重复。如果我们发现结构相近的(多个)算法中有重复代码,则可以把算法的不变(通用)部分留在一个模板方法/函数中,把易变(不同)的部分移到动作/钩子方法/函数中。
页码标注是一个不错的模板模式应用案例。一个页码标注算法可以分为一个抽象(不变的)部分和一个具体(易变的)部分。不变的部分关注的是最大行号/页号这部分内容。易变的部分则包含用于显示某个已分页特定页面的页眉和页脚的功能
所有应用框架都利用了某种形式的模板模式。在使用框架来创建图形化应用时,通常是继承自一个类,并实现自定义行为。然而,在执行自定义行为之前,通常会调用一个模板方法,该方法实现了应用中一定相同的部分,比如绘制屏幕、处理事件循环、调整窗口大小并居中,等等
1.3实现
本节中,我们将实现一个横幅生成器。想法很简单,将一段文本发送给一个函数,该函数要生成一个包含该文本的横幅。横幅有多种风格,比如点或虚线围绕文本。横幅生成器有一个默认风格,但应该能够使用我们自己提供的风格。
函数generate_banner()是我们的模板函数。它接受一个输入参数(msg,希望横幅包含的文本)和一个可选参数(style,希望使用的风格)。默认风格是dots_style,我们马上就能看到。generate_banner()以一个简单的头部和尾部来包装带样式的文本。实际上,这个头部和尾部可以复杂得多,但在这里调用可以生成头部和尾部的函数来替代仅仅输出简单字符串也无不可。
默认的dots_style()简单地将msg首字母大写,并在其之前和之后输出10个点。
该生成器支持的另一个风格是admire_style()。该风格以大写形式展示文本,并在文件的每个字符之间放入一个感叹号。
接下来这个风格是我目前最喜欢的。cow_style()风格使用cowpy模块生成随机ASCII码艺术字符,夸张地表现文本。如果你的系统中尚未安装cowpy,可以使用命令(pip install cowpy)来安装。
cow_style()风格会执行cowpy的milk_random_cow()方法,该方法在每次cow_style()执行时用于生成一个随机的ASCII码艺术字符。
main()函数向横幅发送文本“happy coding”,并使用所有可用风格将横幅输出到标准输出。
下面是template.py的完整代码。
from cowpy import cow
def dots_style(msg):
msg = msg.capitalize()
msg = '.' * 10 + msg + '.' * 10
return msg
def admire_style(msg):
msg = msg.upper()
return '!'.join(msg)
def cow_style(msg):
msg = cow.milk_random_cow(msg)
return msg
def generate_banner(msg, style=dots_style):
print('-- start of banner --')
print(style(msg))
print('-- end of banner --\n\n')
def main():
msg = 'happy coding'
[generate_banner(msg, style) for style in (dots_style, admire_style, cow_style)]
if __name__ == '__main__':
main()
输出。。由于cowpy的随机性,你的cow_style()输出也许会有所不同。
-- start of banner --
..........Happy coding..........
-- end of banner --
-- start of banner --
H!A!P!P!Y! !C!O!D!I!N!G
-- end of banner --
-- start of banner --
______________
< happy coding >
--------------
\ ,-^-.
\ !oYo!
\ /./=\.\______
## )\/\
||-----w||
|| ||
Cowth Vader
-- end of banner --1.4小结
我们学习了模板设计模式。在实现结构相近的算法时,可以使用模板模式来消除冗余代码。具体实现方式是使用动作/钩子方法/函数来完成代码重复的消除,它们是Python中的一等公民。我们学习了一个实际的例子,即使用模板模式来重构BFS和DFS算法的代码
我们看到了一个工人的日常工作是如何与模板模式相类似的
最后实现了一个横幅生成器,使用一个模板函数来实现可定制的文本风格
最后,借用一位重要的Python贡献者Alex Martelli说过的一句话来提醒你:“设计模式是被发现,而不是被发明出来的”