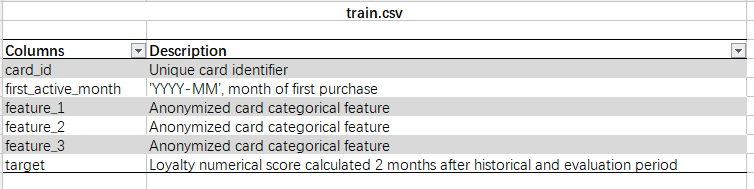
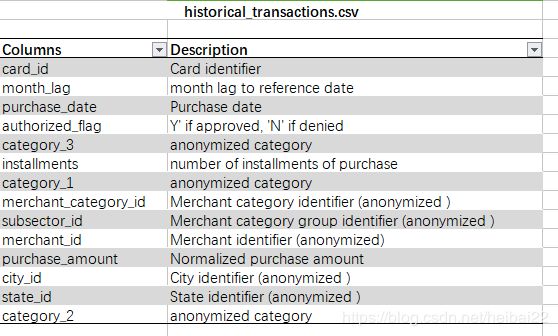
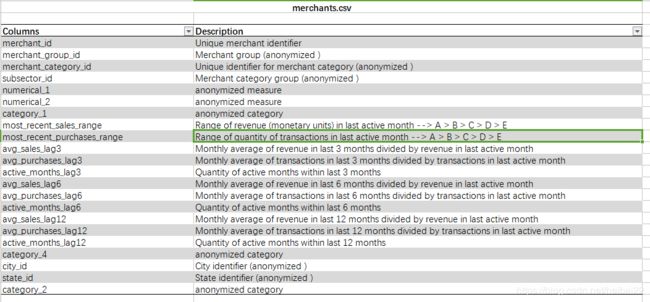
Elo顾客忠诚度 —— kaggle数据
前言
这个数据集来自Kaggle这是链接,是Elo(巴西最大的本土支付品牌之一)和Kaggle合作的项目,通过Elo的匿名数据集预测每个客户的忠诚度(具体到card_id),以及查找影响客户忠诚度的因素。这个是数据集是虚构的(官方是这么说的),而且部分变量都经过匿名处理,并不清楚具体何意(保密工作相当到位)。
整个数据集包含以下的数据,
- historical_transactions: 每个card_id的消费历史,共有2千9百多万条
- new_merchant_transactions:测评期的消费数据,每个card_id在新商店的消费,近2百万条
- merchants:商户的信息数据
- train:训练集
- test: 验证集
- sample_submission:提交数据样本

分析建模
下面将通过python对消费数据进行处理,展现原始数据,已经数据清洗、特征工程和建模的过程。
数据载入
ht = pd.read_csv('all/historical_transactions.csv', dtype={'city_id': np.int16, 'installments': np.int8, 'merchant_category_id': np.int16, 'month_lag': np.int8, 'purchase_amount': np.float32, 'category_2': np.float16, 'state_id': np.int8, 'subsector_id':np.int8})
nt = pd.read_csv('all/new_merchant_transactions.csv', dtype={'city_id': np.int16, 'installments': np.int8, 'merchant_category_id': np.int16, 'month_lag': np.int8, 'purchase_amount': np.float32, 'category_2': np.float16, 'state_id': np.int8, 'subsector_id':np.int8})
train = pd.read_csv('all/train.csv')
test = pd.read_csv('all/test.csv')
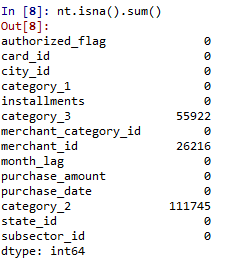
我们先来看看数据长什么样,可以看到历史交易一共29112361条,测评期的交易有1963031条。


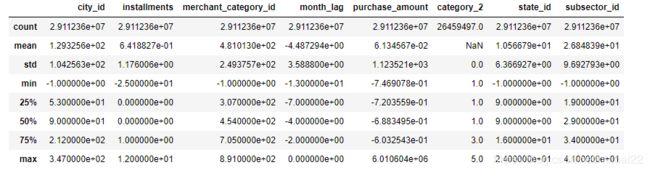
两份交易数据都有3个变量含有缺失值,下面进行数据清洗。
数据清洗
定义一个函数,然后对数据进行清洗。
def tidy_data(df):
df['category_2'].fillna(0, inplace=True)
df['category_3'].fillna('D', inplace=True)
df['installments'].clip(-1, 12, inplace=True)# 有outliers,统一规定范围
mode_mer = df['merchant_id'].mode().iloc[0]# 通过每张卡对应店铺的众数对merchant_id插补
df.sort_values('card_id', inplace=True)
group = df.groupby('card_id')['merchant_id'].apply(lambda x:x.fillna(x.mode().iloc[0] if len(x.mode())>0 else mode_mer))
df.drop('merchant_id', axis=1, inplace=True)
df['merchant_id'] = group.values
return df
ht = tidy_data(ht)
nt = tidy_data(nt)
特征工程
现在,通过已有的数据增加一些变量,然后我们根据每个card_id消费记录(与各个变量的关系)对数据进行重组,构造一个新的数据集,方便后续操作。
def new_data(df):
df['purchase_date'] = pd.to_datetime(df['purchase_date'], format='%Y-%m-%d %H:%M:%S')
df['month'] = df['purchase_date'].dt.month
df['month'] = df['month'].astype(np.int8)
df['day'] = df['purchase_date'].dt.day
df['day'] = df['day'].astype(np.int8)
df['week'] = df['purchase_date'].dt.week
df['week'] = df['week'].astype(np.int8)
df['dayofweek'] = df['purchase_date'].dt.dayofweek
df['dayofweek'] = df['dayofweek'].astype(np.int8)
df['hour'] = df['purchase_date'].dt.hour
df['hour'] = df['hour'].astype(np.int8)
df['is_weekend'] = 0
df.loc[df['dayofweek'].isin([5, 6]), ['is_weekend']] = 1
df['is_weekend'] = df['is_weekend'].astype(np.int8)
df['day_interval'] = 0
df.loc[(0 < df['hour']) & (df['hour'] < 9), ['day_interval']] = 1
df.loc[(8 < df['hour']) & (df['hour'] < 17), ['day_interval']] = 2
df['day_interval'] = df['day_interval'].astype(np.int8)
df['authorized_flag'] = df['authorized_flag'].map({'Y': 1, 'N':0})
df['authorized_flag'] = df['authorized_flag'].astype(np.int8)
df['category_1'] = df['category_1'].map({'Y': 1, 'N':0})
df['category_1'] = df['category_1'].astype(np.int8)
df['days_to_now'] = (datetime.datetime.today()-df['purchase_date']).dt.days
df['days_to_now'] = df['days_to_now'].astype(np.int16)
df['month_diff'] = df['days_to_now']//30
df['month_diff'] += df['month_lag']
df['month_diff'] = df['month_diff'].astype(np.int8)
return df
def cal_amount(df, var, prefix=None):
g = df.groupby(['card_id', var])['purchase_amount'].mean().unstack(var)
g.fillna(0, inplace=True)
columns_names = []
if prefix:
for i in g.columns.values:
new_name = prefix + '_' + var + '_' + str(i) + '_' +'amt'
columns_names.append(new_name)
else:
for i in g.columns.values:
new_name = var + '_' + str(i) + '_' +'amt'
columns_names.append(new_name)
g.columns = columns_names
g.reset_index(inplace=True)
return g
ht = new_data(ht)
nt = new_data(nt)
dict_list = {
'authorized_flag': ['count', 'sum', 'mean'],
'category_1': ['sum', 'mean'],
'month_lag': ['max', 'min', 'mean', 'nunique'],
'month': ['mean', 'nunique'],
'day': ['mean', 'nunique'],
'week': ['mean', 'nunique'],
'dayofweek': ['mean', 'nunique'],
'hour': ['mean', 'nunique'],
'is_weekend': ['sum', 'mean'],
'month_diff': ['mean'],
'days_to_now':['max', 'min'],
'installments': ['max', 'min', 'sum', 'mean', 'std', 'nunique'],
'purchase_amount': ['max', 'min', 'sum', 'mean', 'std'],
'merchant_id': ['nunique'],
'merchant_category_id': ['nunique'],
'subsector_id': ['nunique'],
'city_id': ['nunique'],
'state_id': ['nunique']
}
column_names = []
for key in dict_list.keys():
for i in dict_list[key]:
new_name = key + '_' + i
column_names.append(new_name)
group = ht.groupby('card_id').agg(dict_list)
group.columns = column_names
group['average_days'] = (group['days_to_now_max']-group['days_to_now_min'])/group['authorized_flag_count']
group.reset_index(inplace=True)
g = cal_amount(ht, 'category_2')
group = pd.merge(group, g, how='left', on='card_id')
g = cal_amount(ht, 'category_3')
group = pd.merge(group, g, how='left', on='card_id')
g = cal_amount(ht, 'is_weekend')
group = pd.merge(group, g, how='left', on='card_id')
g = cal_amount(ht, 'day_interval')
group = pd.merge(group, g, how='left', on='card_id')
g = cal_amount(ht, 'month_lag')
group = pd.merge(group, g, how='left', on='card_id')
dict_list = {
'authorized_flag': ['count'],
'category_1': ['sum', 'mean'],
'month_lag': ['mean', 'nunique'],
'month': ['max', 'mean', 'nunique'],
'day': ['mean', 'nunique'],
'week': ['mean', 'nunique'],
'dayofweek': ['mean', 'nunique'],
'hour': ['mean', 'nunique'],
'is_weekend': ['sum', 'mean'],
'month_diff': ['mean'],
'days_to_now':['max', 'min'],
'installments': ['max', 'min', 'sum', 'mean', 'std', 'nunique'],
'purchase_amount': ['max', 'min', 'sum', 'mean', 'std'],
'merchant_id': ['nunique'],
'merchant_category_id': ['nunique'],
'subsector_id': ['nunique'],
'city_id': ['nunique'],
'state_id': ['nunique']
}
column_names = []
for key in dict_list.keys():
for i in dict_list[key]:
new_name = 'new' + '_' + key + '_' + i
column_names.append(new_name)
group_new = nt.groupby('card_id').agg(dict_list)
group_new.columns = column_names
group_new['new_average_days'] = (group_new['new_days_to_now_max']-group_new['new_days_to_now_min'])/group_new['new_authorized_flag_count']
group_new.reset_index(inplace=True)
g = cal_amount(nt, 'category_2', 'new')
group_new = pd.merge(group_new, g, how='left', on='card_id')
g = cal_amount(nt, 'category_3', 'new')
group_new = pd.merge(group_new, g, how='left', on='card_id')
g = cal_amount(nt, 'is_weekend', 'new')
group_new = pd.merge(group_new, g, how='left', on='card_id')
g = cal_amount(nt, 'day_interval', 'new')
group_new = pd.merge(group_new, g, how='left', on='card_id')
g = cal_amount(nt, 'month_lag', 'new')
group_new = pd.merge(group_new, g, how='left', on='card_id')
两份交易数据已经重新构造,现在可以获得一个经过特征工程的新数据集。新数据集有126个变量。
data = pd.merge(group, group_new, how='left', on='card_id')

模型建立
在建立模型前,先对训练集和验证集简单处理一下。
train['target'].plot.hist(bins=50)
len(train[train['target'] < -30])
train['first_active_month'] = pd.to_datetime(train['first_active_month'])
train['year'] = train['first_active_month'].dt.year
train['month'] = train['first_active_month'].dt.month
train.drop('first_active_month', axis=1, inplace=True)
train = pd.merge(train, data, how='left', on='card_id')
train_X = train.drop(['target', 'card_id'], axis=1)
train_y = train['target']
test['first_active_month'].fillna('2017-03', inplace=True)
test['first_active_month'] = pd.to_datetime(test['first_active_month'])
test['year'] = test['first_active_month'].dt.year
test['month'] = test['first_active_month'].dt.month
test.drop('first_active_month', axis=1, inplace=True)
test = pd.merge(test, data, how='left', on='card_id')
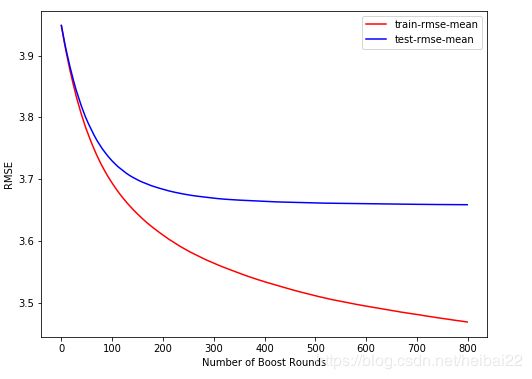
准备完毕,可以上正菜了。在xgboost运行到400轮时,验证集的均方根误差基本平稳。
xgbmodel = xgb.XGBRegressor(
n_estimators=400,
learning_rate=0.01,
max_depth=6,
min_child_weight=8,
gamma=0,
subsample=1,
colsample_bytree=0.6,
reg_alpha=1,
reg_lambda=10,
n_jobs=7,
random_state=123
)
xgbmodel.fit(train_X, train_y, eval_metric='rmse')
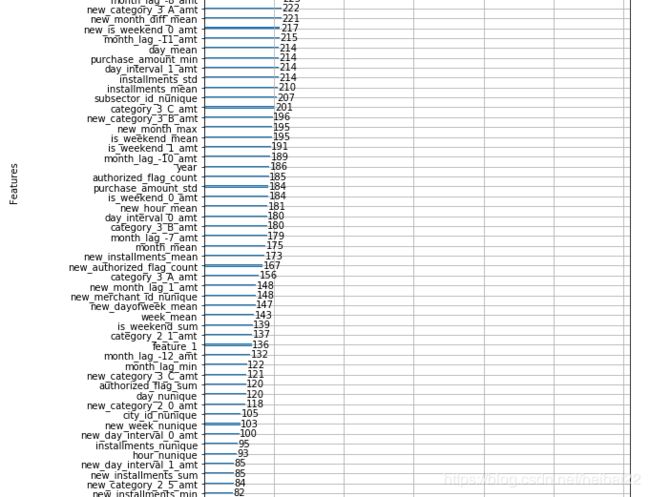
下面,我们来看看变量的重要性得分,哪些变量对客户的忠诚度影响比较大呢。

结论
未完待续……