【论文学习记录】PyramidBox: A Context-assisted Single Shot Face Detector
论文地址:PyramidBox: A Context-assisted Single Shot Face Detector
论文来自百度,2018年的文章。
论文提出新的网络模型名为PyramidBox,主要有以下五个方面的成就:
- 论文提出了一种基于anchor的环境辅助方法PyramidAnchors,引入监督信息学习小的、模糊的和部分遮挡的人脸环境特征。
- 设计了LFPN(Low-level Feature Pyramid Networks)来更好的融合环境特征和人脸特征。同时,LFPN可以在单步方法中很好的处理不同尺度的人脸。
- 提出了一种环境敏感的预测模型,由混合网络结构和max-in-out层组成,从融合的特征中学习准确的定位和分类。
- 提出了一个关注尺度的策略Data-anchor-sampling,可以改变训练样本的分布,强调更小的人脸。
- 在通用人脸检测基准FDDB和WIDER FACE上达到了state-of-the-art的水平。
一、网络结构
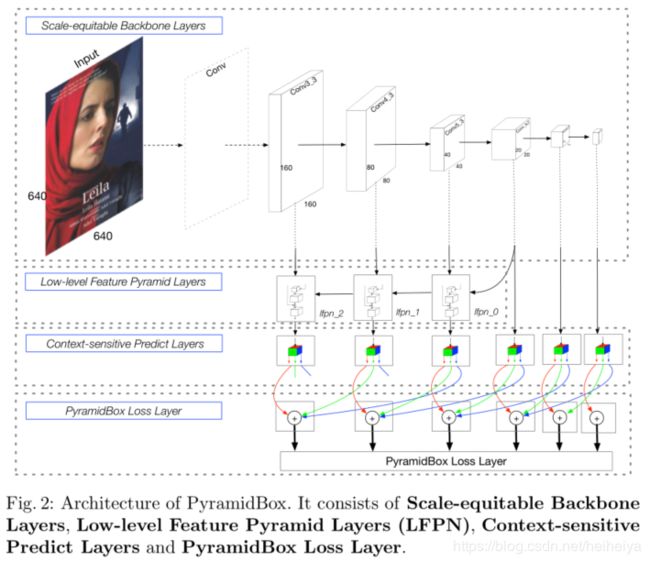
论文使用的是与S3FD相同的主干网络,包括基础卷积层和额外卷积层,其中基础卷积层是VGG16的conv1_1到pool5层,额外卷积层是将VGG16的fc6和fc7替换成conv_fc层,然后添加更多的卷积层使网络更深。
高分辨率的低层特征在提升多尺度人脸的检测效率上的作用至关重要。传统的FPN网络是一种自顶向下的结构,但并不是所有的高层级特征都对小的人脸有帮助,相反还可能引入噪声。因此论文提出一种新的结构LFPN,这种自顶向下的结构开始于网络的中间层。
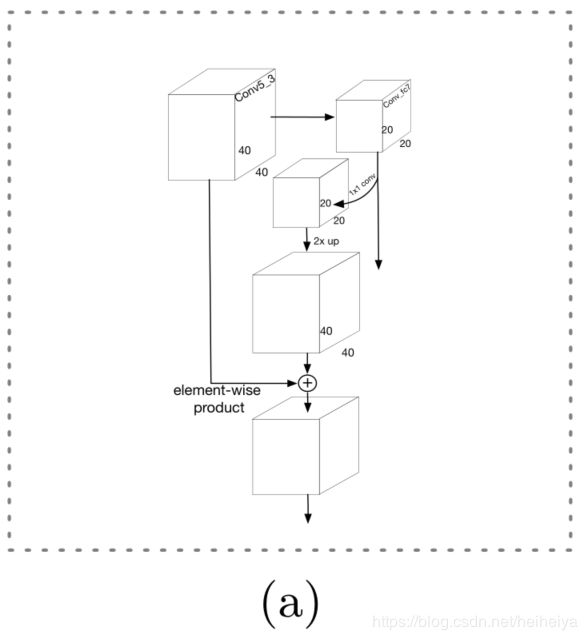
将lfpn_2,lfpn_1,lfpn_0,conv_fc7,conv6_2,conv7_2作为检测层,对应的anchor尺寸分别为16,32,64,128,256,512。这里lfpn_2,lfpn_1,lfpn_0是LFPN的输出层,对应的是conv3_3,conv4_3,conv5_3。对LFPN层使用L2归一化。
每一个检测层的后面接一个CPM(Context-sensitive Predict Module),CPM的输出用于监督pyramid anchors,在论文的实验中近似覆盖人脸、头和身体区域。
第 个CPM的输出尺寸是
个CPM的输出尺寸是![]() ,其中
,其中![]() 是对应的特征尺寸,通道数
是对应的特征尺寸,通道数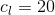 ,=0,1,...,5。每个通道的特征被分别用来分类会回归人脸、头、身体。这里人脸的分类需要
,=0,1,...,5。每个通道的特征被分别用来分类会回归人脸、头、身体。这里人脸的分类需要![]() 个通道,其中
个通道,其中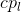 和
和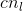 分别是前景和背景的max-in-out标签,满足
分别是前景和背景的max-in-out标签,满足

头部和身体的回归分别需要两个通道,人脸、头部和身体的定位都需要四个通道。
受Inception_ResNet的启发,为了让网络变得更宽和更深,论文设计了CPM。
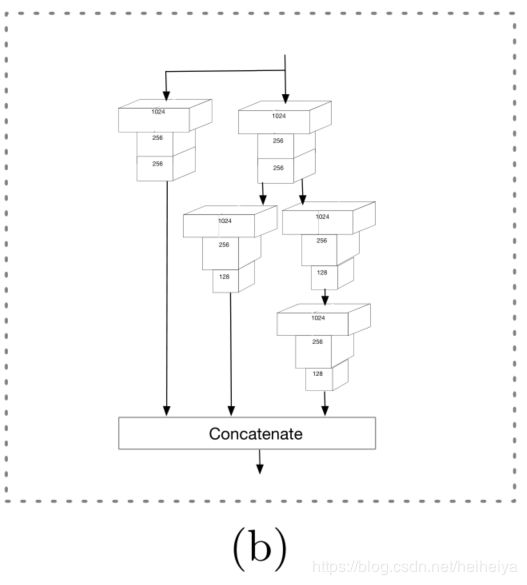
用DSSD中的残差预测模块替换了SSH 中的环境模块的卷积层,使得CPM既有DSSD模块方法的所有优势,又从SSH环境模块中保留了丰富的环境信息。
为解决正负样本不平衡问题,论文改进了S3FD中的max-out方法,称之为max-in-out。

首先为每个预测模块预测![]() 个分数,然后选择max
个分数,然后选择max  作为正样本的分数,max
作为正样本的分数,max 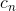 作为负样本的分数。在论文中设置第一个预测模块的
作为负样本的分数。在论文中设置第一个预测模块的![]() ,
,![]() ,其他预测模块
,其他预测模块![]() ,
,![]() ,以便召回更多的人脸。
,以便召回更多的人脸。
传统的人脸检测anchor都是基于面部设计的,忽略了环境特征,因此论文提出一种新的anchor设计方法PyramidAnchors。对每一个目标人脸,PyramidAnchors生成一系列anchors,这些anchors有着和人脸相关的更大的区域,包含如头部、肩部和身体等环境信息。通过匹配区域大小和anchor尺寸来设置anchors层,这将会监督高层级的层为低层级尺寸的人脸学习更有表现力的特征。加上头部、肩部和身体的额外标签,可以准确地匹配anchors和ground truth来生成损失。
为了不增加额外的标签,论文采用一种半监督的方式来生成头、肩、身体的标签。
基于具有相同比例和偏移的不同人脸的区域有相同的环境特征的假设,可以用一些统一的boxes来近似头部、肩部和身体的实际区域。
对于一个在原始图像中在目标区域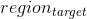 人脸,
人脸,![]() 代表第
代表第 个特征层的第
个特征层的第 个anchor,步长是
个anchor,步长是 ,定义第
,定义第 个pyramid-anchor为
个pyramid-anchor为

其中,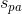 是pyramid anchors的步长,
是pyramid anchors的步长,![]() 表示
表示![]() 在原始图像中对应的区域,
在原始图像中对应的区域,![]() 表示以步长
表示以步长![]() 下采样的区域。论文中设置
下采样的区域。论文中设置![]() ,
,![]() ,
,![]() ,这样
,这样![]() 、
、![]() 、
、![]() 分别是人脸、头、身体的标签。
分别是人脸、头、身体的标签。

二、训练
使用WIDER FACE数据集12880张图片训练,使用了颜色扭曲、随机裁剪和水平翻转增强数据集。
还使用了一种称为Data-anchor-sampling的方法增强数据。Data-anchor-sampling是把训练图像中的一个随机的人脸变成一个随机的更小的 anchor 尺寸。首先随机选择一个人脸,大小为![]() ,PyramidBox中anchors的尺度为
,PyramidBox中anchors的尺度为
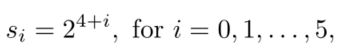
令
![]()
为选择的人脸最相近的anchor尺度的索引,然后在集合

随机选择一个索引![]() 。最后将选择的人脸缩放到
。最后将选择的人脸缩放到
![]()
就得到缩放尺度
![]()
将原始图像以![]() 进行缩放,然后再随机裁剪到包含人脸的标准大小640 x 640。
进行缩放,然后再随机裁剪到包含人脸的标准大小640 x 640。
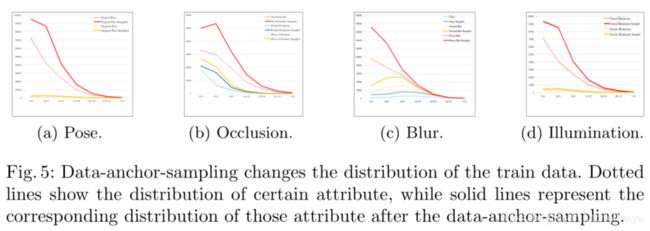
Data-anchor-sampling改变了训练数据的分布,较小的人脸的比例大于较大的人脸,并且通过较大的人脸生成了更多更小的人脸,增加了较小人脸的多样性。
定义一张图片的PyramidBox损失函数为

第k个pyramid-anchor的损失为
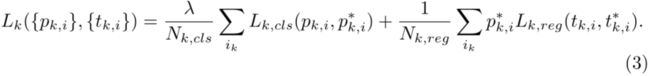
在论文中k=0,1,2分别代表人脸、头、身体,是anchor的索引,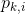 是第个anchor属于第k个目标的概率。
是第个anchor属于第k个目标的概率。
Ground-truth的标签定义为
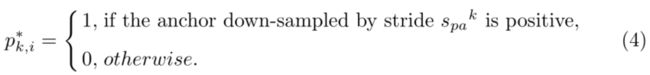
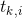 是一个四维向量代表预测的bounding box的坐标,
是一个四维向量代表预测的bounding box的坐标,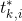 是正的anchor的ground-truth box。
是正的anchor的ground-truth box。
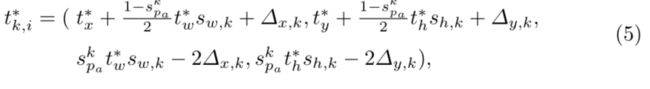
其中![]() 和
和![]() 代表偏移量,
代表偏移量,![]() 和
和![]() 代表宽和高的缩放因子,论文设置当
代表宽和高的缩放因子,论文设置当![]() 时,
时,![]() ,
,![]() ,当
,当 时,
时,![]() ,
,![]() ,
,![]() ,
,![]() 。分类损失
。分类损失 是人脸和非人脸的二分类log损失,回归损失
是人脸和非人脸的二分类log损失,回归损失 是smooth
是smooth 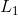 损失。
损失。![]() 表示回归损失仅对正的anchors有效。分类损失和回归损失分别利用和进行归一化。
表示回归损失仅对正的anchors有效。分类损失和回归损失分别利用和进行归一化。
论文使用了VGG16的预训练参数,conv_fc6和conv_fc7的参数利用VGG16的fc6和fc7下采样参数进行初始化,其他层的参数用“xavier”方法随机初始化。前80k次迭代学习率 ,80k-100k学习率
,80k-100k学习率 ,100k-120k学习率
,100k-120k学习率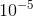 ,batch size 16,momentum 0.9, weight decay 0.0005。
,batch size 16,momentum 0.9, weight decay 0.0005。
三、实验
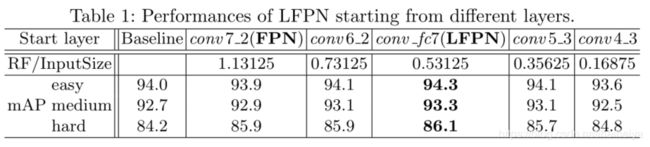
证明LFPN结构有效。

PyramidAnchor确实有助于提升性能。
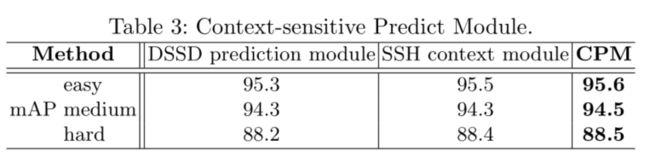
CPM可以微弱提高性能。

最终,各部分组合起来性能提升是很明显的。