计算图片HOG特征
提取算法
代码
计算特征&特征维度
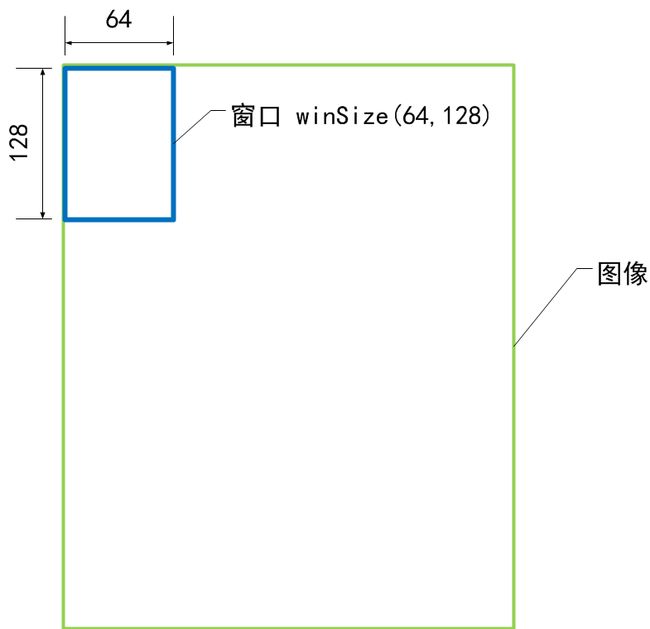
HOGDescriptor *descriptor=new HOGDescriptor(cvSize(40,80),//winSize
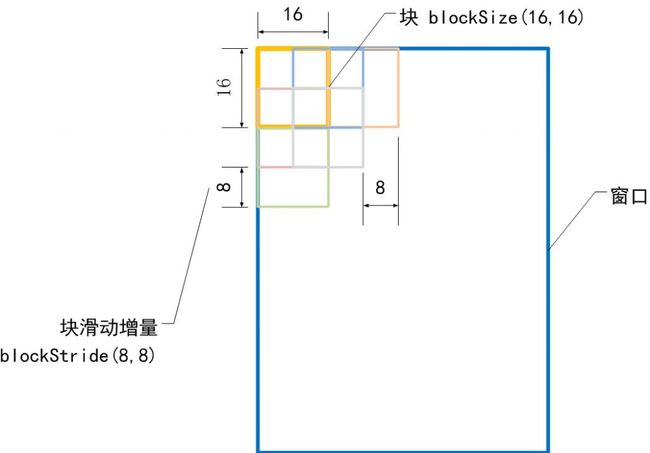
cvSize(10,20),//blockSize
cvSize(5,10),//blockStride
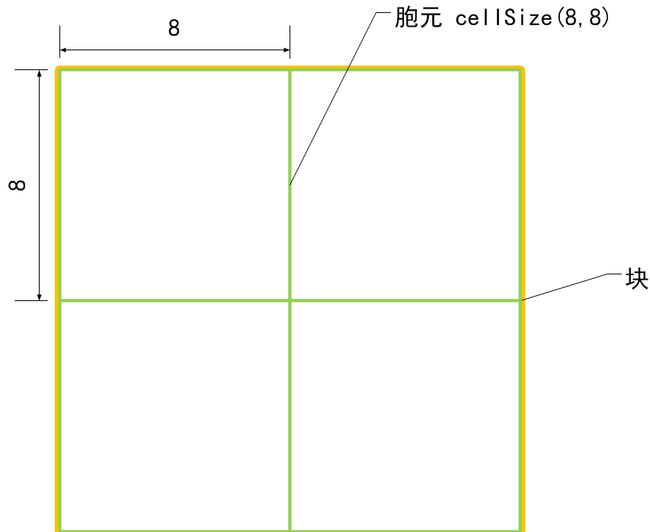
cvSize(5,5),//cellSize
9);//nbins每个block中cell的个数为blockSize/cellSize=2*4=8(无重叠)
每个cell中有9个bin
因此每个window中bin的个数为49*8*9=3528
2 计算图片特征
vectorw;
descriptor->compute(cv::cvarrToMat(Img),// image
w, // hog feature
cvSize(10,20), //winStride
cvSize(0,0)); //paddingSize 当设置padding为默认(0,0)时, 计算(imgSize - winSize) /windowStride +1 不一定为整数
在compute函数中可以看到:
padding.width =(int)alignSize(std::max(padding.width, 0), cacheStride.width);
padding.height = (int)alignSize(std::max(padding.height, 0), cacheStride.height);
即padding的大小会自动适应stride的值.
img的尺寸是96*160的, 对应了6.6 * 5, 经函数调整后变成7 * 5 =35
因此96*160的图片, 共有35*3528=123480维特征向量
参数说明
窗口大小 winSize
块大小 blockSize
胞元大小 cellSize
梯度方向数 nbins
nBins表示在一个胞元(cell)中统计梯度的方向数目,例如nBins=9时,在一个胞元内统计9个方向的梯度直方图,每个方向为180/9=20度。
hog源码分析
http://www.cnblogs.com/tornadomeet/archive/2012/08/15/2640754.html
使用opencv自带SVM进行训练
=++++++++++++++++++++++提取 HOG 特征+++++++++++++++++++++++++=
//样本矩阵,nImgNum:横坐标是样本数量。 列数是该 样本对应的 特征维数。ex: 样本是学生,其样本特征可以由 身高,体重,年龄 组成,那么 第二个参数就是 3 啦。
CvMat *data_mat = cvCreateMat( nImgNum, 1764, CV_32FC1 );
//类型矩阵,存储每个样本的类型标志 , 一维,只需要存储该样本属于哪一类即可(只有两类)
CvMat * res_mat = cvCreateMat( nImgNum, 1, CV_32FC1 );
HOGDescriptor *hog=new HOGDescriptor(cvSize(64,64),cvSize(16,16),cvSize(8,8),cvSize(8,8),9);
// 计算hog特征
// trainImg是读入的需要计算特征的图像,IplImage* trainImg=cvCreateImage(cvSize(64,64),8,3);
//descriptors 是结果数组 vector
hog->compute(trainImg, descriptors,Size(1,1), Size(0,0));
//计算完成后,把hog特征存储到 上面声明的那个 样本 矩阵中
// i 是当前处理的第 i 张 图片, n 从 0 开始 ++ ,从第 0 列 开始存储。 *iter 是 (vector
cvmSet(data_mat, i, n,*iter);
// 训练读入的图片是有 标签 的( 知道已知属于哪一类), 将标签存入 标签 矩阵 。i 是当前处理的 图片 的 编号。 img_catg[i] 是 读入 的已知的 数据。
cvmSet( res_mat, i, 0, img_catg[i] );
++++++++++++++++++++++++++++++++++开始训练+++++++++++++++++++++++++++
首先要/新建一个SVM
CvSVM svm = CvSVM();
// 开始训练~
svm.train( data_mat, res_mat, NULL, NULL, param ); //data_mat 是 上面提取 到的 HOG特征,存储 m 个样本的 n 个特征, res_mat 是标签矩阵,m个样本属于哪一类,已// 知的。 param 的定义如下:
CvSVMParams param = CvSVMParams( CvSVM::C_SVC, CvSVM::RBF, 10.0, 0.09, 1.0, 10.0, 0.5, 1.0, NULL, criteria );
CvTermCriteria criteria = cvTermCriteria( CV_TERMCRIT_EPS, 1000, FLT_EPSILON );
// 将训练结果保存在 xml文件中
svm.save( "SVM_DATA.xml" );
此阶段生成文件:
SVM_DATA.xml
训练完成之后,就开始 对 你所需要 的 数据 进行 预测。 这里预测 当前 图片 属于 那一类别。
++++++++++++++++++++++++++++++++++检测样本+++++++++++++++++++++++++++
读入当前要预测的图片 testImg
将testImg 缩放 至 与 训练图片 一样大小 ,直接存放到 trainImg中
计算读入的图片的Hog特征,
hog->compute(trainImg, descriptors,Size(1,1), Size(0,0)); //调用计算函数开始计算
仍用 vector
创建一个 一行 n 列 的向量。 n 是 特征的个数 。 就是上面的 3 啊, descriptors.size() 啊。 用来存放 当前要预测的图片的 特征
CvMat* SVMtrainMat=cvCreateMat(1,descriptors.size(),CV_32FC1);
// 开始预测
int ret = svm.predict(SVMtrainMat);
ret 返回的是 当前 预测 的 图片 的 类别。 就是 一开始 读到 标签 矩阵 中的 数据。 一般 用 0 or 1 来标示 两大类别。
可将结果文件保存在:
SVM_PREDICT.txt