视觉SLAM常见面试题 (下)
常见面试题
1、 视觉SLAM框架及组成
a) SLAM即实时定位建图,按照使用的传感器分为激光SLAM(LOAM、V-LOAM、cartographer、gmapping)与视觉SLAM,其中视觉SLAM又可分为单目SLAM(MonoSLAM、PTAM、DTAM、LSD-SLAM、ORB-SLAM(单目为主)、SVO)、双目SLAM(LIBVISO2、S-PTAM等)、RGBD SLAM(KinectFusion、ElasticFusion、Kintinous、RGBD SLAM2、RTAB SLAM);按照前端方法分为特征点法(稀疏法)、光流法、稀疏直接法、半稠密法、稠密法;按照后端方法分为基于滤波(EKF,UKF,PF原理简介)与基于图优化的方法。
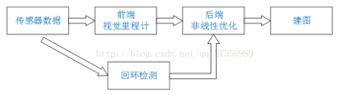
b) 视觉SLAM由前端(视觉里程计)、后端(位姿优化)、闭环检测、建图图4个部分组成。
2、如何对匹配好的点做进一步的处理,更好保证匹配效果?或如何滤除外点
a) 确定匹配的最大距离:先求出所有匹配点最小距离min_dist(Hamming距离吗?),小于2倍的最小距离的点,认为是内点,即30<匹配点距离<=2*min_dist,30是经验值,有些点会特别小。
b) 基于KNN匹配算法:令k=2,即取最近邻与次近邻距离(.distance(),该距离类似于欧式距离,用于表征匹配质量,距离越小,匹配效果越好)的比值,比值小于一定阈值(如<0.8)则认为是内点;
c) RANSAC方法。
3、对于单目相机,F和H矩阵有何不同,E和F矩阵有何不同,只旋转不平移能不能求F、能不能求H?
a) F和E描述的都是两帧间的极线约束,只不过坐标系不同:F描述的是同一空间点在不同帧之间像素坐标的几何约束关系,也即极线约束,E描述的是归一化相机坐标之间的几何约束关系,且 , ,其中 ;可知,E只与相机内参有关,F与内外参都有关;而H描述的是一系列共面的3D点到相机成像平面(两个平面间)的投影变换关系;
b) 三者分解出R,t不同: ,其中(n,d)表示世界坐标系下某个平面的平面方程,因此H只与外参、平面参数有关,而与内参无关。
c) 在相机只有纯旋转而没有平移时,此时t为0,E、F也将为0,导致无法求解R;此时可以使用单应矩阵H求旋转,但仅无平移t,无法三角化求深度。
4、计算H矩阵和F矩阵的时候有什么技巧呢?实际上在问归一化的操作。
5、ORB-SLAM初始化的时候为什么要同时计算H矩阵和F矩阵?
a) 当特征点共面或相机间发生了纯旋转时,基础矩阵自由度下降,即发生了所谓的退化,此时如果仍采用八点法估算F矩阵,基础矩阵多出来的自由度将会由噪声决定,对结果造成极大误差。为避免退化现象造成的影响,通常会同时估计基础矩阵F和单应矩阵H,选择重投影误差较小的那个作为最终的运动估计矩阵。
6、什么是极线约束
a) 所谓极线约束就是说同一个点在两幅图像上的映射,已知左图映射点p1,那么右图映射点p2一定在相对于p1的极线上,这样可以减少待匹配的点数量、提高匹配效率。(画图解释)
7、描述BA过程
a) BA是Bundle Adjustment的简称,又称光束法平差、捆绑调整、集束调整,其本质是一个优化模型,其目的是最小化重投影/光度误差,用于优化相机位姿和路标点。其主要过程为:根据相机的投影模型构造代价函数,利用非线性优化(比如高斯牛顿或L-M(Levenberg-Marquardt)算法)来求最优解,利用Hessian矩阵的稀疏性解增量方程,得到最优的相机位姿和3D特征点。
b) 局部BA用于优化局部的相机位姿/三维点,提高跟踪的精度;全局BA用于全局过程中的相机位姿/三维点,使相机经过长时间、长距离的移动之后,相机位姿还比较准确。可以直接计算,也可以使用g2o或者Ceres等优化库进行计算。局部BA的约束:相机位姿、三维点,全局BA约束:相机位姿、三维点、回环检测的约束。
c) Bundle Adjustment :光束指的是三维空间点投影到像平面上的光速,每一个特征点都会反射几束光线,当把相机位姿和特征点位置做出最优的调整后,即使用光束法调整光束以后,这些光线都收束到相机光心。

8、描述PnP过程
a) PnP即Perspective-n-Points,它是一种由3D-2D匹配点求解相机位姿的方式,此处的3D点是世界坐标系,2D点是归一化相机坐标(内参已知),对于那些没有3D匹配点的2D-2D匹配点对,求解其3D点仍需采用三角化的方式。
b) 此时求解出来的位姿均是相机相对世界坐标系的变换关系Twc(Twc是所求目标结果,但一般存储的是Tcw,便于计算)。
c) 目前遇到的场景主要有两个,其一是求解相机相对于某2维图像/3维物体的位姿;其二就是SLAM算法中估计相机位姿时通常需要PnP给出相机初始位姿。在场景1中,我们通常输入的是物体在世界坐标系下的3D点以及这些3D点在图像上投影的2D点,因此求得的是相机坐标系相对于世界坐标系(Twc)的位姿。在场景2中,通常输入的是上一帧相机坐标系下的3D点(把上一帧视为世界坐标系,本质仍是世界坐标系)和这些3D点在当前帧中的投影得到的2D点,所以它求得的是当前帧相对于上一帧的位姿变换。两种情况本质上是相同的,都是基于已知世界坐标系3D点和对应的归一化相机坐标系2D点求解相机运动的过程。
9、如何选择关键帧
关键帧选择指标:
a) 跟踪质量:比如当前帧跟踪到的特征点数大于一定阈值,如大于50个点,或关键帧跟踪到的点比参考关键帧少90%。
b) 距离最近关键帧的距离是否足够远(空间):即当前帧空间位置是否有足够的变换,如在静止不动或移动幅度较小的情况下,当移动角度大于一定程度才认为是关键帧。
c) 距离上一关键帧的帧数是否足够多(时间):如过了20帧仍没有插入关键帧;
d) 关键帧作用:图像插入频率过高会导致信息冗余度快速增加,而这些冗余的信息对系统的精度提升却十分有限,甚至没有提高,反而消耗了更多的计算资源。关键帧的目的在于,适当地降低信息冗余度,减少计算机资源的损耗,保证系统的平稳运行。
10、为什么要引入李群李代数?李群与李代数的关系?
a) 旋转矩阵自身是带有约束的,即是正交矩阵且行列式为1,他们作为优化变量时,会引入额外的约束,优化变的困难,通过李群李代数的转换关系,把位姿估计变成无约束的优化问题。
b) 李群与李代数是对数与指数的关系,李群到李代数是对数变换,李代数到李群是指数变换。李群是矩阵的集合,李代数是向量的集合,矩阵求导时对加法不封闭,而映射为李代数之后对向量来说,加法是封闭的。
11、什么是闭环检测
a) 在视觉SLAM问题中,位姿的估计往往是由上一帧位姿解算当前帧位姿,这么递增求解,因此相邻两帧之间的误差就会产生累计。如我们在求解第五帧位姿的时候,一般是根据第四帧计算的,但是如果我们发现第5帧还可以由第2帧计算出来,就减少了误差的累计。这种与之前的某一帧(非相邻帧)建立位姿约束关系就叫做回环。找到可以建立这种位姿约束的历史帧,就是回环检测。回环通过减少约束数,起到了减小累计误差的作用。
b) 方法:特征匹配,提取当前帧与过去所有帧的特征,并进行匹配,这种方式假设了过去所有帧都有可能出现回环,匹配十分耗时、计算量大。基于词袋模型,词袋模型就是把特征看成是一个个单词,通过比较两张图片中单词的一致性,来判断两张图片是否属于同一场景。词袋模型需要训练字典(K-means聚类),但通常字典内单词数量巨大,在确定某个特征时需要与字典内每个单词进行匹配,效率低下。为提高匹配效率,字典在训练的过程中构建了一个有k个分支,深度为d的树(K叉树),类似于层次聚类,可容纳k^d个单词,保证了对数级别的查找效率。
12、单目视觉尺寸漂移是怎么产生的
a) 单目相机无法根据一张图片得出一张图片中物体的实际大小,同理也就无法得出运动的尺度大小,这是产生尺度漂移的根源。而在使用单目估计相机位姿和3D点坐标时,需要通过对极几何、三角化进行估计,在这个过程中会产生误差(特征点精度误差、计算误差),即使是极小的误差经过多帧累积后会变得特别大,无法保证尺度的一致性,造成尺度漂移。
b) 解决办法:从理论上说,只靠单目相机是无法确定尺度的。视觉与IMU融合,IMU可以测量实际尺度,借助IMU测得的高帧率的角速度、加速度对视觉进行修正、补充;后端优化时,把尺度作为一个优化变量进行优化,可以减小尺度漂移问题。
单目SLAM初始化过程、单目SLAM整个过程
a) 初始化过程:是通过前两帧之间2D-2D匹配点,使用对极几何计算出相机的旋转、平移矩阵,并将该平移矩阵初始化为后续相机运动的单位,即初始化之后的运动都以初始化时的平移作为单位1,是为了解决单目的尺度不确定性问题。且在初始化时,要保证两帧图片之间的运动必须包括平移(不能只是纯旋转),否则将导致求得的本质矩阵E为0,也就无法分解得到相机位姿。
b) 单目SLAM流程是:初始化—PnP—三角化—PnP—三角化……。具体方法是依赖对极几何的相关知识,根据2D-2D匹配点对计算本质矩阵(或基本矩阵),并对其进行分解得到相机运动,再依据三角化原理计算特征点距离。至此即得到3D-2D匹配点对,后续的相机位姿的估计就是PnP问题了、后续3D点的计算仍采用三角化方式。
13、SLAM中的绑架问题(重定位)
a) 绑架问题就是重定位,是指机器人在缺少之前位置信息的情况下,或跟踪丢失的情况下,如何进行重新定位、确定当前位姿。例如当机器人被安置在一个已经构建好地图的环境中,但是并不知道它在地图中的相对位置,或者在移动过程中,由于传感器的暂时性功能故障或相机的快速移动,都导致机器人先前的位置信息的丢失,在这种情况下如何重新确定自己的位置。
词袋模型可以用于回环检测,也可以用于重定位,有什么区别
词袋模型在SLAM中的应用:当前帧与关键帧的特征匹配、重定位的特征匹配、回环检测的特征匹配;(第一个是后两个的基本原理,后两个是应用场景)。连续帧间特征匹配采用的并不是词袋模型。
a) 重定位:主要是通过当前帧与关键帧的特征匹配,定位当前帧的相机位姿。
b) 回环检测:优化整个地图信息,包括3D路标点、及相机位姿、相对尺度信息。回环检测提供了当前帧与所有历史帧的关系,
14、相比VSLAM,加入IMU后,哪些状态可观?
a) 单目SLAM7个自由度不可观:6个自由度+尺度;
b) 单目+IMU4个自由度不可观:偏航角(yaw)+3自由度不可观;翻滚角(roll)、俯仰角(pitch)由于重力存在而可观,尺度因子由于加速度计的存在而可观;
15、仿射变换、透视变换、欧式变换有什么区别
a) 仿射变换:形状会改变,但直线的平行关系不变,如矩形变成平行四边形。是透视变换的特殊形式。
b) 透视变换(或称射影变换):是仿射变换更一般的形式,是共面点投影的变换关系,如单应性矩阵。平行的直线变换前后可能不会保持平行。
c) 欧式变换(或称等距变换):旋转、平移;
16、什么是紧耦合、松耦合?优缺点
a) VIO是融合相机和IMU数据实现SLAM的算法,根据融合框架的区别又分为紧耦合和松耦合,松耦合中视觉运动估计和惯导运动估计系统是两个独立的模块,将每个模块的输出结果进行融合,而紧耦合则是使用两个传感器的原始数据共同估计一组变量,传感器噪声也是相互影响的,紧耦合算法上比较复杂,但充分利用了传感器数据,可以实现更好的效果,是目前研究的重点。
b) 按照是否把图像的Feature加入到状态向量区分,也就是松耦合是在视觉和IMU各自求出的位姿的基础上做的耦合,紧耦合是使用图像和IMU耦合后的数据计算相机位姿。
17、室内SLAM与自动驾驶SLAM有什么区别?
RANSAC在选择最佳模型的时候用的metric是什么?
a) Metric译作:admission to a group,可以理解为指标、许可。我的理解是,此处指的是按照什么指标选择最佳模型,对每个模型计算内点数量,内点数量的大小即是选择指标,内点数量最大的即是最佳模型。
18、除了RANSAC之外,还有什么鲁棒估计的方法?
a) M-估计(鲁棒核函数)、最小中值估计。
b) 参考
19、有哪几种鲁棒核函数?
a) RANAC和鲁棒核函数都是为了解决出现outlier的问题:RANAC是从数据中选择正确的匹配进行估计,鲁棒核函数则是直接作用在残差上,对残差进行饱和函数运算,限制单个数据点对于误差函数的影响力。等于对最小二乘问题做了包装,通过降低错误匹配的权重,使得观测数据中的outlier影响不到最终的估计结果:
20、什么是边缘化?First Estimate Jacobian算法?一致性?可观性?
a) 对于VIO系统,边缘化的目的是把旧的状态量从状态估计窗口中移除,保证运行效率;同时,需要把移除的状态量的信息保留下来,作为当下窗口的先验,尽可能避免信息丢失。
RGB-D的SLAM和RGB的SLAM有什么区别?
a) RGBD-SLAM与RGB-SLAM使用的相机不同,前者可读出深度图像和彩色图像、后者只能读出彩色图像(单目或双目);
b) 传感器数据不同,主要造成前端视觉里程计很多不同,如RGBD-SLAM不用初始化、计算3D点云方式不同、可以使用ICP直接计算相机位姿,
c) 参考
21、什么是ORB特征,ORB特征的旋转不变性是如何做的,BRIEF算子是怎么提取的。
a) ORB特征即Oriented FAST and Rotated BRIEF,由FAST关键点和BRIEF描述子两部分组成,先使用FAST提取角点作为特征点,再使用BRIEF对特征点周围区域进行描述,计算描述子;
b) 通过改进FAST特征点获得尺度不变性和旋转不变性:普通FAST角点不具备方向性和尺度不变性,ORB对其进行改进,增加了尺度不变性和特征点的方向信息,所以称为Oriented FAST关键点;尺度不变性通过构建图像金字塔、并在金字塔每一层检测角点实现;特征的方向(旋转)信息由灰度质心法计算图像块的质心、再连接图像块几何中心O与质心C,即可得到特征点的方向向量OC,特征点的方向即定义为theta =arctan(m01/m10)。至此FAST角点具有了尺度与旋转的描述。FAST特征点有了方向信息,在后续计算BRIEF描述子时,即可保证特征点的旋转不变性。
c) FAST角点提取:半径为3的圆上16个像素点,如果连续的N个点的亮度大于Ip+T或小于Ip-T(T为设定的阈值,如0.2*Ip),则认为该点是特征点,N常去12,即FAST-12。
d) BRIEF算子是二进制描述子,其描述向量由许多0和1组成,通过在关键点附近随机取两个像素(如p和q),比较p和q像素值的大小关系,如果p大于q,则取1,反之取0,取128组这样的p、q,即可得到特征点的128维描述子。
e) ORB速度快的原因:相比其他特征点检测算法,FAST只是比较像素亮度大小;BRIEF通过随机选点、编码0和1的方式计算描述子,因此速度快。
f) 参考:《视觉SLAM十四讲》P134-P36;
22、ORB-SLAM中的特征是如何提取的?如何均匀化的?
ORB-SLAM中关键帧之间的连接,共视图(Covisibility Graph)数据结构
a) ORB-SLAM2中关键帧之间的连接是通过共视图(Covisibility Graph)和生成树(Spanning Tree)表达的。
b) 共视图:是一个有权重的无向图,图的结点为一个关键帧,如果两个关键帧能共同观测到一定数量的地图点,那么这两个关键帧之间建立一条边,边的权重为共同观测到的地图数量。
c) 生成树: 生成树是共视图的包含最少边的子图,每次向生成树添加一个关键帧时,将该关键帧与树中共视地图点数量最多的关键帧连接。从生成树中删除一个关键帧时,也要更新受到影响的所有关键帧的连接关系。
d)参考