以前在进行搜索引擎rank-svm排序模型训练时,直接使用python读取的HDFS日志文件、统计计算等预处理操作再进行svm模型,最终产生出训练模型。现在回想一下,数据预处理这一块完全可以使用spark进行,而且看起来更“正规一点”和高大上,并借机接触一下大数据。pyspark的安装折腾了一上午,这篇文章简述一下unbuntu下如何安装pyspak。
主要过程:1) 安装jdk1.8; 2)安装pyspark; 3)安装py4j。
jdk1.8的安装相对简单,这里省略。下面介绍安装pyspark。
1.pip命令安装
官方文档说pypi已经支持pyspark,因此对于python用户,可以使用pip install pyspak命令进行(前提是你已经安装了pip)。该命令执行后一段时间,会出现如下打印
然后,你可以泡壶茶,静静等待。。。
在安装过程中,你可能会遇到2个问题:1)安装的过程中出现timeout的问题,这个问题是站点或者网络问题,可以延长pip install的默认超时时间(15s)来解决,例如设置默认超时时间100s:pip install --default-time=100 pyspark ; 2) 如果你使用的python版本过低,例如python2.7,在安装的过程中,会抛出如下异常
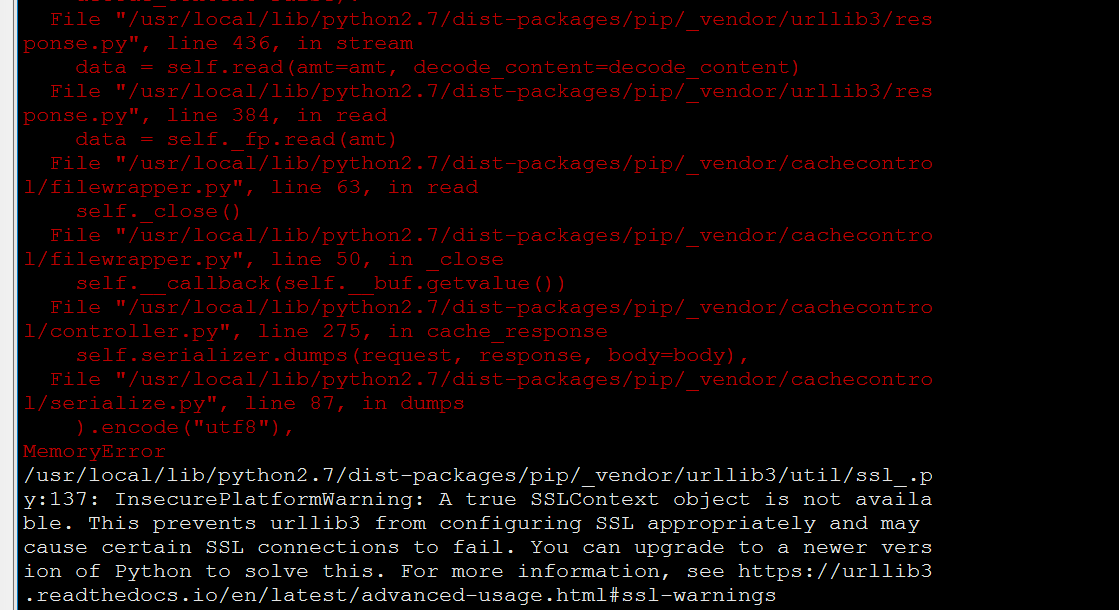
白色字体提示:InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. You can upgrade to a newer version of Python to solve this.
意思就是说建议你升级python版本。笔者的很多脚本都是python2.7.14的,因此升级python2.7是万万不可能的,那么智能另辟蹊径了,看下面。
2. 源码包绿色安装
如果pip命令安装不可行,则可以使用该方法。
1) 下载spark-2.3.0-bin-hadoop2.7.tgz
2) 然后tar -xzf spark-2.3.0-bin-hadoop2.7.tgz,之后在解压的bin目录下就可以可以看到pyspark了。
3)运行./pyspark
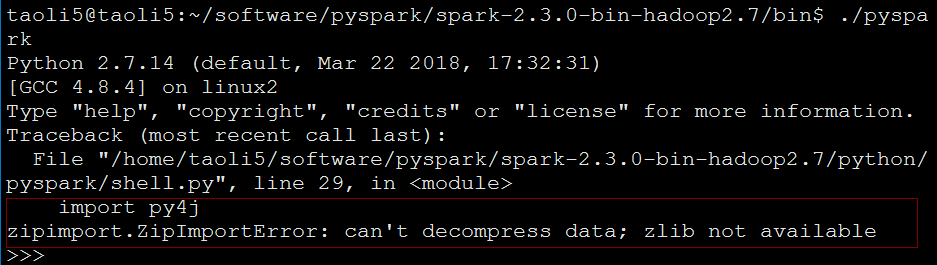
点背啊,又遇到问题了:zipimport.ZipImportError: can't decompress data; zlib not available。解决办法:
(1) 先安装系统相应的依赖库文件: sudo apt-get install zlibc zlib1g-dev
(2) 到python安装目录下执行: sudo ./configure
(3) 编辑Modules/Setup文件:
vim Modules/Setup
找到下面这句,去掉注释
#zlib zlibmodule.c -I$(prefix)/include -L$(exec_prefix)/lib -lz
(4) 重新编译安装:
sudo make
sudo make -i install
重新编译安装后,在运行./pyspark,终于出现spark图标了,如下。

4)配置变量,增加/home/taoli5/software/pyspark/spark-2.3.0-bin-hadoop2.7/bin目录,这样以后就可以在任何地方直接调用pyspark了。
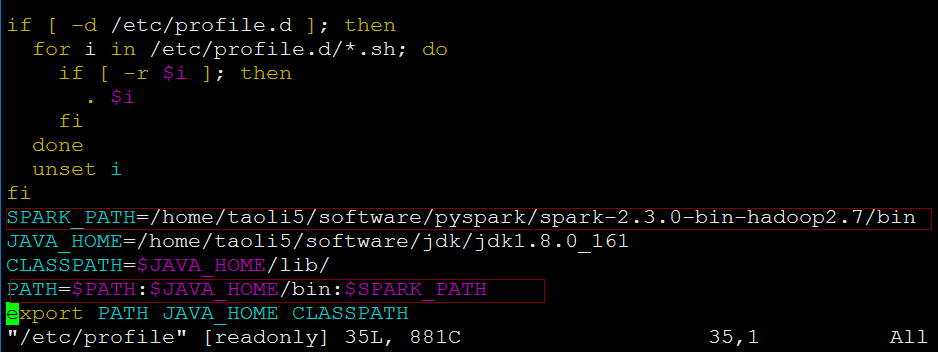
3.安装py4j,直接执行sudo pip install py4j就行了。
4,.测试pyspark
>>>pyspark >>> textFile = spark.read.text("README.md") >>> textFile.count() [Stage 0:> (0 +[Stage 0:===========================================================(1 + 103 >>> textFile.count() 103 >>> textFile.filter(textFile.value.contains("Spark")).count() 20 >>>
至此,整个安装过程就完成了,good lock!