Redis 横向扩展案例
Redis 横向扩展案例
文/温国兵
0x00 目录
- 0x00 目录
- 0x01 背景介绍
- 0x02 分析解决
- 2.1 初步分析
- 2.2 使用 Twemproxy 横向扩展
- 2.3 问题解决
- 0x03 原理探讨
- 0x04 案例小结
0x01 背景介绍
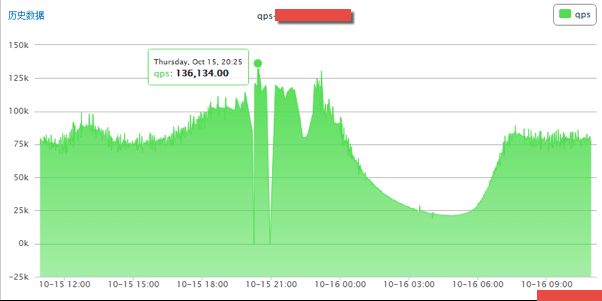
A 项目采集其它项目生成的数据,数据保存一定时间,并且不需要持久化。故 A 项目使用单点 Redis 做缓存。长期以来,该 Redis 实例在高峰期间的 QPS 高达 100K,甚至一度达到 120K。某天晚上,终于崩溃了。这也印证了「 墨菲定律 」,事情如果有变坏的可能,不管这种可能性有多小,它总会发生(Anything that can go wrong will go wrong)。所以,平时的运维过程,千万不要抱有侥幸心理,有问题就第一时间反应,有隐患就及时处理。
0x02 分析解决
2.1 初步分析
单点 Redis 实例崩溃的现象就是新的连接不能建立,超时严重,数据不能及时读取。查看系统日志,发现有大量形如「kernel: Possible SYN flooding on port xxxx. Sending cookies」的日志。我们很快排查了系统遭受攻击的可能性。查看端口占用情况,确实是被 Redis 消耗了。分析监控数据和端口数情况,此时的 Redis 连接数达到了 7K,QPS 已经达到 100K。现在亟待解决的问题就是连接数高的问题。另外,针对 QPS 过高的问题,确认是否可以使用 Redis 管道技术。
经过和研发沟通,得知程序采用 Nginx Lua 实现。Lua 是一个简洁、轻量、可扩展的脚本语言,也是号称性能最高的脚本语言。使用 Nginx Lua,再加上 LuaRedisModule 模块,就可以原生地和 Redis 建立请求,并解析响应。但真实的项目中采用的是 lua-resty-redis,这是一个为 ngx_lua 设计的,基于 cosocket API 的 Redis Lua 客户端。
程序中使用了如下设置:
set_keepalive(5000, 20)其中第一个参数表示 max_idle_timeout,第二个参数表示 pool_size。这个方法是为每个 Nginx 工作进程设置的。也就是说,最终建立的连接计算公式如下:
connectionNum(连接数) = machineNum(机器数) * nginxWokerProcess(每台机器的 Nginx 工作进程数) * pool_size(连接池大小)
前端有四台 Web 服务器,每台机器 18 个 Nginx 工作进程,按照上面的设置,那和单点 Redis 建立的连接数为 4*18*20,也就是 1440。然而,真实的连接已经达到 7K,看来问题不在这里。
我们尝试使用 Redis Pipeline,至于原因,且听我慢慢道来。
Redis 是一种基于客户端/服务端模型以及请求/响应协议的 TCP 服务。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听 Socket 返回,通常是以阻塞模式,等待服务端响应;
- 服务端处理命令,并将结果返回给客户端。
Redis 管道可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。可以简单地理解为批量操作,一次返回。
然而,真实场景中,绝大多多数的命令是 INCR,也就是 +1 的操作。这类操作使用管道的意义不是太大,于是放弃了。
2.2 使用 Twemproxy 横向扩展
我们尝试进行 Scale Out,增加 Redis 实例,并且使用 Twemproxy 代理,每台 Web 服务器访问本地的 Twemproxy。
在此不妨简单介绍下 Twemproxy。为了满足数据的日益增长和扩展性,数据存储系统一般都需要进行一定的分片。分片主要存在三个位置,第一层,数据存储系统本身支持;第二层,服务器端和客户端中间建代理支持;第三层,客户端支持。Redis Cluster 属于第一层,Twemproxy 属于第二层,Memcached 属于第三层。Twemproxy(又称为 nutcracker)是一个轻量级的 Redis 和 Memcached 代理,主要用于分片。Twemproxy 由 Twitter 开源出来的缓存服务器集群管理工具,主要用来弥补 Redis 和 Memcached 对集群 (Cluster) 管理的不足。Twemproxy 按照一定的路由规则,转发给后台的各个 Redis 实例,再原路返回。有了 Twemproxy,前端不再关心后端代理了多少 Redis 实例,而只需访问 Twemproxy 即可,一方面简化了开发难度,另一方面提高了性能。Twemproxy 支持大部分命令,但对多键命令的支持有限,并且会有 20% 左右的性能损失(Twitter 官方测试结果)。简单来说,Twemproxy 就是一个支持 Redis 协议,对前端透明,支持分片,性能优秀的代理。当然,目前 Redis 3.0 已经发布,不少厂商会选择使用 Redis 3.0 代替 Twemproxy,这需要时间。
我们在独立服务器新增了 4 个实例,并且 Web 服务器部署 Twemproxy,应用访问本地的 Twemproxy。但实际的效果并不理想,Redis QPS 依然高,本地的 Twemproxy 居然让 Web 服务器性能恶化。另外一个有趣的现象是,Twemproxy 代理的几个 Redis 实例存在严重的数据倾斜。有些 Redis 实例 QPS 可以达到 80K,有些 Redis 只有 5K 左右。
那目前我们的问题主要集中在两个问题上,第一,连接数过高;第二,数据倾斜。经过研发排查,找出一段令人匪夷所思的代码。Nginx Lua 中的超时时间是 60s,这也解释了为什么实际连接跟理论连接相差如此巨大。
2.3 问题解决
根据以上的分析,我们决定分两步走。第一,更改超时时间;第二,解决数据倾斜的问题。
研发把超时改为 2s,并且根据实际情况更改了连接池,观察效果。可以明显地看到,连接数降到 1K 左右,机器 Socket 使用数下降显著,连接没有阻塞,业务没有较大的波动。
解决了连接数的问题,我们接下来解决数据倾斜的问题。
如前所述,Scale Out 后,Redis 实例存在严重的数据倾斜。有些 Redis 实例 QPS 可以达到 80K,有些 Redis 只有 5K 左右。分析这个问题,这就要从业务数据形态入手。这个业务是统计业务,由大量的 INCR 操作,并且产生的 Key 较少。Twemproxy 根据配置的一致性 Hash 函数,对 Key 进行 Hash 校验,再决定转发到对应的 Redis 实例。
根据以上分析,产生的 Key 较少,也就是重复率较高,导致转发的 Redis 实例就会集中。这也解释了为什么会产生数据倾斜。针对这个问题,我们展开讨论。最开始打算写本地文件,然后定时写入 Redis,这样 Redis 的 QPS 会下降不少。但考虑到定时器实现较复杂,于是采取了拆分 Key 的办法。举个例子,比如之前是一分钟一个 Key,那现在 1 分钟产生 10+ Key,甚至更多,那这样数据倾斜的问题自然会慢慢减缓,直至消除。
经过研发的艰苦奋斗,把 Key 拆分后,效果明显。QPS 分摊到各个 Redis 实例,连接数下降,Web 服务器性能提高。
0x03 原理探讨
在原理探讨这一小结,笔者只针对 Twemproxy 一致性 Hash 函数进行浅薄地分析。
Twemproxy 提供取模,一致性哈希等手段进行数据分片,维护和后端 Server 的长连接,自动踢除 Server、恢复 Server,提供专门的状态监控端口供外部工具获取状态监控信息。Twemproxy 使用的是单进程单线程来处理请求,只是另外起了一个线程来处理统计数据。
Twemproxy 的代码组成如下:事件处理、多种 Hash 函数、协议、自定义的数据类型、网络通信、信号处理、数据结构和算法、统计日志和工具、配置文件和主程序。
第二小结有提到 Twemproxy 的 一致性Hash 函数。一致性 Hash 函数有:one_at_a_time、md5、crc16、crc32、crc32a、fnv1_64、fnv1a_64、fnv1_32、fnv1a_32、hsieh、murmur 和 jenkins。Key 的分发模式有:ketama、modula 和 random。线上业务配置的 Hash 函数是 fnv1a_64 ,分发模式为 ketama 。
fnv1a_64 Hash 算法的实现,我们可以用如下 Python 代码(来自 ning )模拟:
def hash_fnv1a_64(s):
UINT32_MAX=2**32
FNV_64_INIT = 0xcbf29ce484222325 % UINT32_MAX
FNV_64_PRIME = 0x100000001b3 % UINT32_MAX
hval = FNV_64_INIT
for c in s:
hval = hval ^ ord(c)
hval = (hval * FNV_64_PRIME) % UINT32_MAX
return hvalKey 重复率越高,根据一致性函数处理后,转发到相同机器的概率就会越高。
另外,ketama 分发模式的算法复杂度是 O(LogN),然而 modula 的算法复杂度是 O(1)。按照官方的示例,我们默认采用了 ketama。不过最好按照实际环境配置。
0x04 案例小结
此案例非常具有代表性。第一,排查定位问题的思路;第二,Redis 遇到瓶颈的解决思路;第三,Scale Out 的分析角度。遇到瓶颈问题,可以从如下几个角度思考,第一,对代码、服务器和相关服务进行优化;第二,具体产品的选型或者定制;第三,根据业务形态,对数据产生、处理和消费流程进行梳理,梳理完成再决定或者优化架构形态;第四,进行扩展,根据业务场景决定 Scale Out 还是 Scale Up。
–EOF–
插图来自:监控系统
版权声明:自由转载-非商用-非衍生-保持署名 (创意共享3.0许可证)