实战深入理解 Delta Lake 事务日志
笔者在介绍 Delta Lake 的上篇文章中提到过,Delta Lake 的 事务日志是非常重要的,Delta Lake 提供的多个特性都和事务日志相关,比如 ACID 事务、并发读写、时间旅行等,可以说事务日志是 Delta Lake 项目的核心模块之一。在本篇文件中,笔者将带领大家详细理解事务日志的来龙去脉。
Delta Lake 引入事务日志目的
单一事实来源
Delta Lake 作为开源的存储层,构建在 Apache Spark 之上,允许多个数据管道对表进行并发读取和写入数据。提到并发读写表数据,就会涉及数据完整性和一致性,所以 Delta Lake 引入事务日志作为枢纽,记录表的所有变更操作行为,将表或目录的元数据信息存储在事务日志中,而非传统数据库中。
当用户第一次读取 Delta Lake 表或在打开的表上运行一个新查询,该表自上次读取后已经被修改过,那么 Spark 会检查事务日志来查看已向表写入的新事务,然后使用这些新更改更新最终用户的表。这可确保用户表的版本始终与最新查询中的主记录同步,而且防止用户修改表时产生歧义和冲突。
Delta Lake 原子性实现
原子性是 ACID 事务的四个属性之一,它可以保证在 Delta Lake 上执行的操作(如 INSERT 或 UPDATE )要么全部成功要么全部不成功。如果没有此属性,硬件故障或软件错误很容易导致数据仅部分写入表中,从而导致数据混乱或损坏。
事务日志是 Delta Lake 能够提供原子性保证的机制。无论如何,如果具体变更操作没有记录在事务日志中,它就不会真正发生,用户也无法查询到该变更的记录。通过只记录完全执行的事务,并使用该记录作为单一的事实来源。Delta Lake 对待元数据就像对待用户数据一样,利用 Spark 的分布式处理能力来处理它的所有元数据。因此,Delta Lake 可以轻松地处理PB级的表和数十亿个分区和文件。
事务日志工作过程
既然我们知道,Delta Lake 事务日志是 Delta Lake 表上执行每次事务的有序记录。下面我们进行案例实战环节,然后观察事务日志变化情况并进行分析。
1. 准备数据
数据文件 user.csv,内容如下:
uid,name,age
10000001,hdfs,12
10000002,spark,8
10000003,delta,1
将 user.csv 上传到 HDFS 的位置为 /delta/mydelta.db/user_info 。
2. 创建 Delta Lake 表
根据原始数据创建 Delta Lake 表:
scala> val USER_INFO_DATA = "/delta/mydelta.db/user_info_source/user.csv"
scala> val user_info_data_df = spark.read.option("header", "true").option("delimiter",",").csv(USER_INFO_DATA)
scala> user_info_data_df.count()
res0: Long = 3
scala> val USER_INFO_DELTA_TABLE = "/delta/mydelta.db/user_info"
scala> user_info_data_df.write.format("delta").save(USER_INFO_DELTA_TABLE)
3. 查看 Delta Lake 表结构
为了便于查看数据,省略文件和目录的属性信息:
$ hdfs dfs -ls -R /delta/mydelta.db/user_info/
/delta/mydelta.db/user_info/_delta_log
/delta/mydelta.db/user_info/_delta_log/00000000000000000000.j/delta/mydelta.db/user_info/part-00000-f504c7cc-7599-4253-8265-5767b86fe133-c000.snappy.parquet
其中: deltalog: 存储事务日志 user_info: 存储数据文件
我们更新一下数据:
scala> val deltaTable = DeltaTable.forPath("/delta/mydelta.db/user_info")
scala> deltaTable.update(
| condition = expr("uid == 10000002"),
| set = Map("age" -> expr("age -2")))
scala>
scala> deltaTable.toDF.show()
+--------+-----+---+
| uid| name|age|
+--------+-----+---+
|10000001| hdfs| 12|
|10000002|spark|6.0|
|10000003|delta| 1|
+--------+-----+---+
更新一条记录后,我们查看目录情况:
$ hdfs dfs -ls -R /delta/mydelta.db/user_info/
/delta/mydelta.db/user_info/_delta_log
/delta/mydelta.db/user_info/_delta_log/00000000000000000000.json
/delta/mydelta.db/user_info/_delta_log/00000000000000000001.json
/delta/mydelta.db/user_info/part-00000-81c99f05-5e9a-4efc-bf5e-7f6f92ab455c-c000.snappy.parquet
/delta/mydelta.db/user_info/part-00000-f504c7cc-7599-4253-8265-5767b86fe133-c000.snappy.parquet
直观地看,事务日志和数据目录都增加了一个文件。
我们继续操作,这次我们删除一条符合条件的数据:
scala> deltaTable.delete(condition = expr("name == 'hdfs'"))
scala> deltaTable.toDF.show()
+--------+-----+---+
| uid| name|age|
+--------+-----+---+
|10000002|spark|6.0|
|10000003|delta| 1|
+--------+-----+---+
最后,再次查看目录变化情况:
$ hdfs dfs -ls -R /delta/mydelta.db/user_info/
/delta/mydelta.db/user_info/_delta_log
/delta/mydelta.db/user_info/_delta_log/00000000000000000000.json
/delta/mydelta.db/user_info/_delta_log/00000000000000000001.json
/delta/mydelta.db/user_info/_delta_log/00000000000000000002.json
/delta/mydelta.db/user_info/part-00000-81c99f05-5e9a-4efc-bf5e-7f6f92ab455c-c000.snappy.parquet
/delta/mydelta.db/user_info/part-00000-b096e3ea-bde6-4ae6-/delta/mydelta.db/user_info/part-00000-f504c7cc-7599-4253-8265-5767b86fe133-c000.snappy.parquet
事务日志文件和数据文件各增加一个。
好了,下面我们来分析事务日志相关内容。
4. 基于文件级别的事务日志
通过上面的例子,我们可以看出,Delta Lake 的事务日志是基于文件级别。当我们创建 Delta Lake 表时,将在 _delta_log 目录中自动创建该表的事务日志。当对该表进行更改时,这些更改将作为有序的原子提交记录在事务日志中。每个提交都以 JSON 文件的形式写出,首次更改从 00000000000000000000.json 开始,继续对表进行更改按数字升序顺序生成后续 JSON 文件,所以下一次提交被写入到 00000000000000000001.json 文件,接着更改写入到 00000000000000000002.json 文件,依此类推。
介绍完事务日志的生成规则后,接着简单分析一下日志内容,查看 /delta/mydelta.db/user_info/_delta_log/00000000000000000002.json,如下:
{"commitInfo":{"timestamp":1571824795230,"operation":"WRITE","operationParameters":{"mode":"ErrorIfExists","partitionBy":"[]"},"isBlindAppend":true}}
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}
{"metaData":{"id":"44f7e591-cc4c-4121-b0f2-53fb41bf92ec","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"uid\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"age\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1571824794341}}
{"add":{"path":"part-00000-f504c7cc-7599-4253-8265-5767b86fe133-c000.snappy.parquet","partitionValues":{},"size":797,"modificationTime":1571824795183,"dataChange":true}}
这是刚开始创建 Delta Lake 表,可以看出事务日志中包含表的元数据信息,以及添加了一个 parquet 格式的数据文件。
我们再来分析 Delta Lake 表删除一条记录后的事务日志,查看 /delta/mydelta.db/user_info/_delta_log/00000000000000000002.json:
{"commitInfo":{"timestamp":1571825875092,"operation":"DELETE","operationParameters":{"predicate":"[\"(`name` = 'hdfs')\"]"},"readVersion":1,"isBlindAppend":false}}
{"remove":{"path":"part-00000-81c99f05-5e9a-4efc-bf5e-7f6f92ab455c-c000.snappy.parquet","deletionTimestamp":1571825875087,"dataChange":true}}
{"add":{"path":"part-00000-b096e3ea-bde6-4ae6-8402-4fadd9adc397-c000.snappy.parquet","partitionValues":{},"size":784,"modificationTime":1571825875079,"dataChange":true}}
"operation":"DELETE" 记录本次变更为删除操作。
"operationParameters":{"predicate":"[\"(
name= 'hdfs')\"]"} 删除条件为 name = 'hdfs'。remove":{"path":"part-00000-81c99f05-5e9a-4efc-bf5e-7f6f92ab455c-c000.snappy.parquet" 此次变更后,历史数据标记为删除状态,不可用,作为数据版本的一部分,时间旅行功能。
"add":{"path":"part-00000-b096e3ea-bde6-4ae6-8402-4fadd9adc397-c000.snappy.parquet" 此次变更后,新的可用的数据文件。
上面介绍的只是事务日志,接下来我们研究 Delta Lake 的数据文件。
5. 基于 Parquet 存储格式的数据文件
在分析 Delta Lake 事务日志的过程中,我们其实大致了解了 Delta Lake 表的数据文件。针对上面的案例,最后一次执行删除操作后,添加一个新的 parquet 格式的存储文件 /delta/mydelta.db/user_info/part-00000-b096e3ea-bde6-4ae6-8402-4fadd9adc397-c000.snappy.parquet,与此同时,之前的两个 parquet 数据文件不再属于 Delta Lake 表的一部分,但是它们的操作记录继续在事务日志中存在,Delta Lake 仍然保留这些原子提交,以确保在需要审计表或使用 时间旅行来查看表在给定时间点的数据版本内容。
这里我们举例示范一下查看时间旅行特性,由于我们针对 Delta Lake 的表 user_info 一共执行三次变更操作,即 add、update 和 delete操作,我们来查看这三次数据版本内容:
scala> spark.read.format("delta").option("versionAsOf", 0).load("/delta/mydelta.db/user_info").show()
+--------+-----+---+
| uid| name|age|
+--------+-----+---+
|10000001| hdfs| 12|
|10000002|spark| 8|
|10000003|delta| 1|
+--------+-----+---+
scala> spark.read.format("delta").option("versionAsOf", 1).load("/delta/mydelta.db/user_info").show()
+--------+-----+---+
| uid| name|age|
+--------+-----+---+
|10000001| hdfs| 12|
|10000002|spark|6.0|
|10000003|delta| 1|
+--------+-----+---+
scala> spark.read.format("delta").option("versionAsOf", 2).load("/delta/mydelta.db/user_info").show()
+--------+-----+---+
| uid| name|age|
+--------+-----+---+
|10000002|spark|6.0|
|10000003|delta| 1|
+--------+-----+---+
# 查看不存在的时间旅行版本号,报错
scala> spark.read.format("delta").option("versionAsOf", 3).load("/delta/mydelta.db/user_info").show()
org.apache.spark.sql.AnalysisException: Cannot time travel Delta table to version 3. Available versions: [0, 2].;
at org.apache.spark.sql.delta.DeltaErrors$.versionNotExistException(DeltaErrors.scala:595)
at org.apache.spark.sql.delta.DeltaHistoryManager.checkVersionExists(DeltaHistoryManager.scala:146)
at org.apache.spark.sql.delta.DeltaTableUtils$.resolveTimeTravelVersion(DeltaTable.scala:222)
at org.apache.spark.sql.delta.DeltaLog$$anonfun$31.apply(DeltaLog.scala:609)
at org.apache.spark.sql.delta.DeltaLog$$anonfun$31.apply(DeltaLog.scala:608)
at scala.Option.map(Option.scala:146)
at org.apache.spark.sql.delta.DeltaLog.createRelation(DeltaLog.scala:608)
at org.apache.spark.sql.delta.sources.DeltaDataSource.createRelation(DeltaDataSource.scala:208)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
... 51 elided
如果我们从表中删除了基础数据文件,Spark 也不会立刻从磁盘中删除文件。用户可以使用 VACUUM 命令删除不再需要的文件。如下:
scala> import io.delta.tables._
import io.delta.tables._
scala> val userInfoDeltaTable = DeltaTable.forPath("/delta/mydelta.db/user_info")
userInfoDeltaTable: io.delta.tables.DeltaTable = io.delta.tables.DeltaTable@fee6412
scala> userInfoDeltaTable.vacuum()
Deleted 0 files and directories in a total of 1 directories.
res5: org.apache.spark.sql.DataFrame = []
6. 检查点文件
Delta Lake 通过参数 checkpointInterval 来控制多久会自动生成检查点文件,默认为10次间隔。
/** How often to checkpoint the delta log. */
val CHECKPOINT_INTERVAL = buildConfig[Int](
"checkpointInterval",
"10",
_.toInt,
_ > 0,
"needs to be a positive integer.")
也就是说,如果我们提交了每隔10次事务日志,Delta Lake 就会在 _delta_log 目录中以 Parquet 格式保存一个检查点文件,我们这里来操作演示一下。
之前已经存在三次变更操作的事务日志,我们再连续进行8次更新数据操作:
scala> val deltaTable = DeltaTable.forPath("/delta/mydelta.db/user_info")
scala> deltaTable.update(
| condition = expr("uid == 10000002"),
| set = Map("age" -> expr("age + 1")))
scala>
查看一下 Delta Lake 表的目录信息:
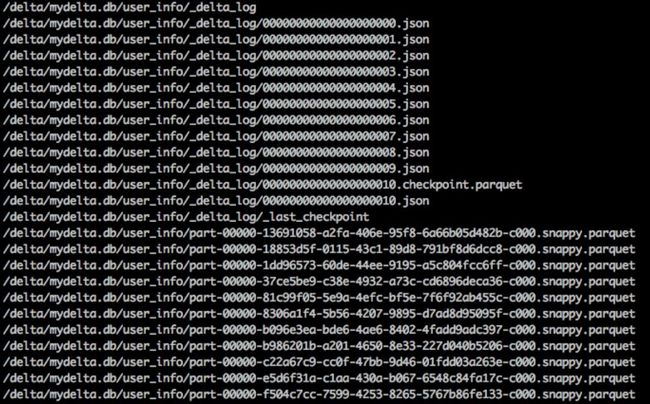
这些检查点文件在某个时间点保存表的整个状态,以原生的 Parquet 格式保存,Spark 可以快速轻松地读取,从而允许 Spark 避免重新处理可能存在的数千个 JSON 格式的小文件。为了提高速度,Spark 可以运行一个 listFrom 操作来查看事务日志中的所有文件,快速跳转到最新的检查点文件,并且只处理自保存了最新的检查点文件以来提交的 JSON 文件。
7. 处理多个并发的读取和写入
上面我们介绍了事务日志有关的内容,接着我们来看一下Delta Lake 处理多个并发读写的情况。
Delta Lake 使用乐观并发控制来提供写操作之间的事务保证。
什么是乐观并发控制?乐观并发控制是一种处理并发事务的方法,它假定不同用户对表所做的事务(更改)可以在不相互冲突的情况下完成。它的速度非常快,因为当处理 PB 级的数据时,用户很可能同时处理数据的不同部分,从而允许他们同时完成不冲突的事务。
Delta Lake 支持并发读取和仅追加写入(append-only)。要被视为只追加数据,写入者必须只添加新数据,而不以任何方式读取或修改现有数据。允许并发读取和追加,即使在相同的 Delta 表分区上操作,也可以获得快照隔离。
在这种机制下,写操作分为三个阶段:
读
读取表的最新可用版本,以确定哪些文件需要修改(即重写)。
写
通过写入新的数据文件来执行所有的更改。
验证和提交
在提交更改之前,检查本次更改是否与自读取快照以来并发提交的任何其他更改相冲突。如果没有冲突,则将所有阶段的更改提交为新的版本快照,并且写入操作成功。但是,如果存在冲突,则写操作将失败,并出现并发修改异常,而不是像使用开源 Spark 那样破坏表。
即使使用乐观并发控制,有时用户也会尝试同时修改数据的相同部分。那我们来看一下 Delta Lake 如何处理这种情况。
乐观地解决冲突
为了提供ACID事务,Delta Lake 有一个协议,用于确定提交应该如何排序(在数据库中称为 Serializability),并确定在同时执行两个或多个提交时应该做什么。Delta Lake 通过实现互斥规则来处理这些情况,然后尝试乐观地解决任何冲突。该协议允许 Delta Lake 遵循 ACID 隔离原则,该原则确保多个并发写操作之后的表的结果状态与那些连续发生的写操作相同,并且是彼此隔离的。
一般来说,过程如下:
记录起始表的版本
记录读和写操作
尝试提交
如果有人已经提交了,检查一下你读到的内容是否有变化
重复上面的步骤
为了了解这一切是如何实时进行的,让我们看一下下面的图表,看看 Delta Lake 在冲突突然出现时是如何管理冲突的。假设两个用户从同一个表中读取数据,然后每个用户都尝试向表中添加一些数据。
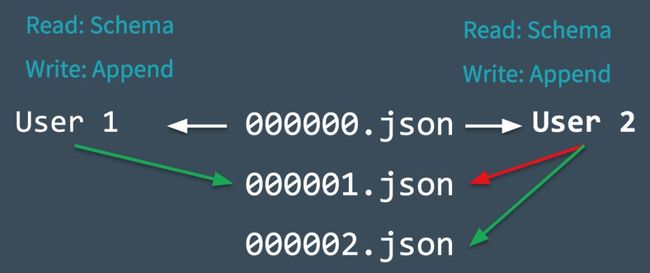
Delta Lake 记录在进行任何更改之前读取的表的起始表版本(版本0)
用户1和2都试图同时向表添加一些数据。在这里,我们遇到了一个冲突,因为接下来只有一个提交可以被记录为 000001.json
Delta Lake使用互斥处理这种冲突,这意味着只有一个用户能够成功提交 000001.json。用户1的提交被接受,而用户2的提交被拒绝
Delta Lake 更倾向于乐观地处理这种冲突,而不是为用户2抛出错误。它检查是否对表进行了任何新的提交,并悄悄地更新表以反映这些更改,然后在新更新的表上重试用户2的提交(不进行任何数据处理),最后成功提交 000002.json。
但是,如果 Delta Lake 无法乐观地解决不可调和的问题(例如,如果用户1删除了文件,用户2也删除这个文件),那么惟一的选择就是抛出一个错误。
由于在 Delta Lake 表上进行的所有事务都直接存储到磁盘中,因此这个过程满足 ACID 持久性的特性,这意味着即使在系统发生故障时,它也会保持。
时间旅行
每个表都是事务日志中记录的所有提交的总和的结果。事务日志提供了一步一步的指导,详细描述了如何从表的原始状态转换到当前状态。
因此,我们可以通过从原始表开始重新创建表在任何时间点的状态,并且只处理在该点之前提交的数据。这种强大的功能被称为时间旅行,或数据版本控制。
作为对 Delta Lake 表所做的每个更改的最终记录,事务日志为用户提供了可验证的数据血统,这对于治理、审计和合规性目的非常有用。它还可以用于跟踪一个意外更改或管道中的一个 bug 的起源,以追溯到导致该更改的确切操作。
参考资料
Michael Armbrust等大神的技术文章《Diving Into Delta Lake: Unpacking The Transaction Log》