知识抽取(二)
目录
面向文本的知识抽取
关系抽取分类
Deepdive关系抽取实战
KBC系统
kbc系统自动搭建框架
KBC流程
框架实战:抽取上市公司中的股权交易关系
开放域关系抽取
知识挖掘
实体消歧与链接
知识规则挖掘
Stactical Schema Induction
关联规则挖掘 (ARM)
统计关系学习 (SRL)
基于图的方法
路径排序方法
知识图谱表示学习
PRA vs. TransE
路径的表示学习
加入规则的表示学习
多模态的表示学习
基于知识图谱图结构的表示学习
总结和挑战
面向文本的知识抽取
-
关系抽取分类
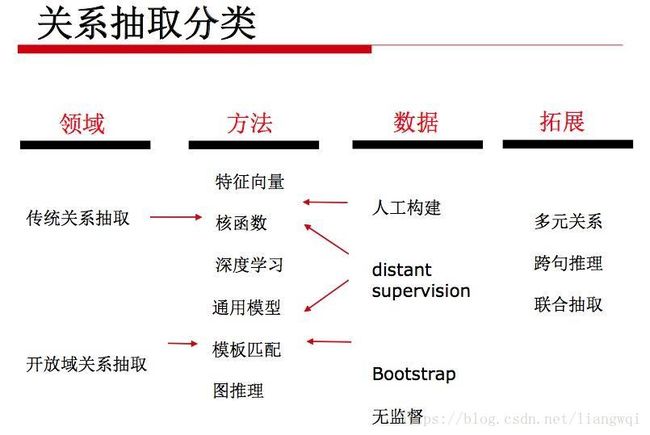
-
Deepdive关系抽取实战
-
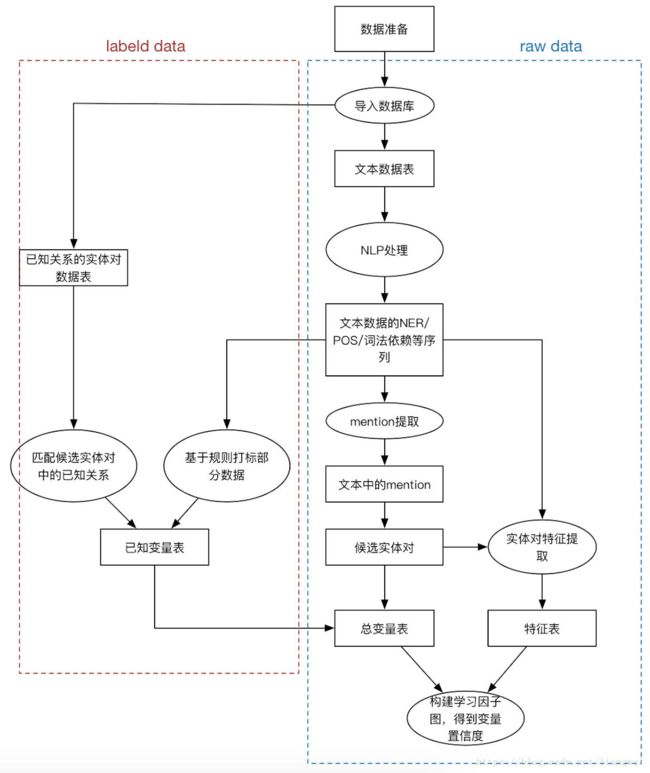
KBC系统
填充、融合不同来源的知识
输入
非结构化的期刊文章
半结构化的html、table等
输出
结构化知识库

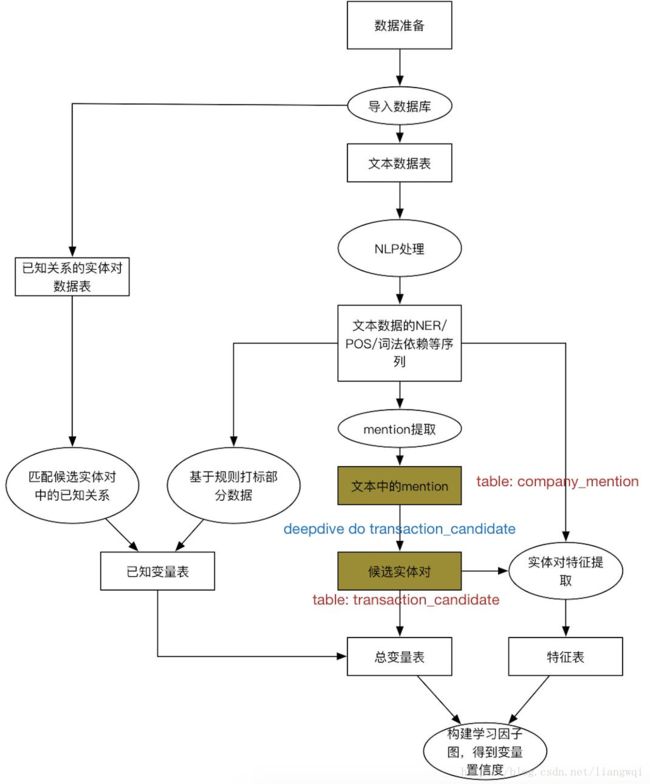
kbc系统自动搭建框架
特征工程 + distant supervision + 图优化
考虑全局最优而不是某个三元组最优
帮助领域专家自主搭建KB,专家只需要填充领域知识,不用考虑算法性能等问题
技术难点
设计一个KBC系统的工作流,包括文本预处理、特征抽取、统计推理与学习、迭代优化等。用户通过自定义datalog语言调控这些过程。
利用分布式数据库大幅度提升系统性能
-
KBC流程
特征抽取
OCR、NLP工具等
用户自定义脚本
专业知识融合
在整个知识库上进行多种关系的融合
监督学习
distant supervision
迭代优化
如何分析模型并提升最终结
-
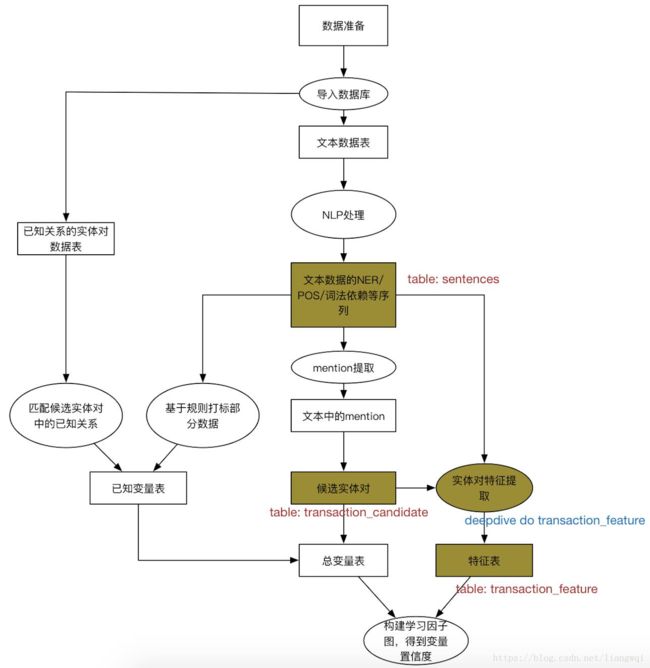
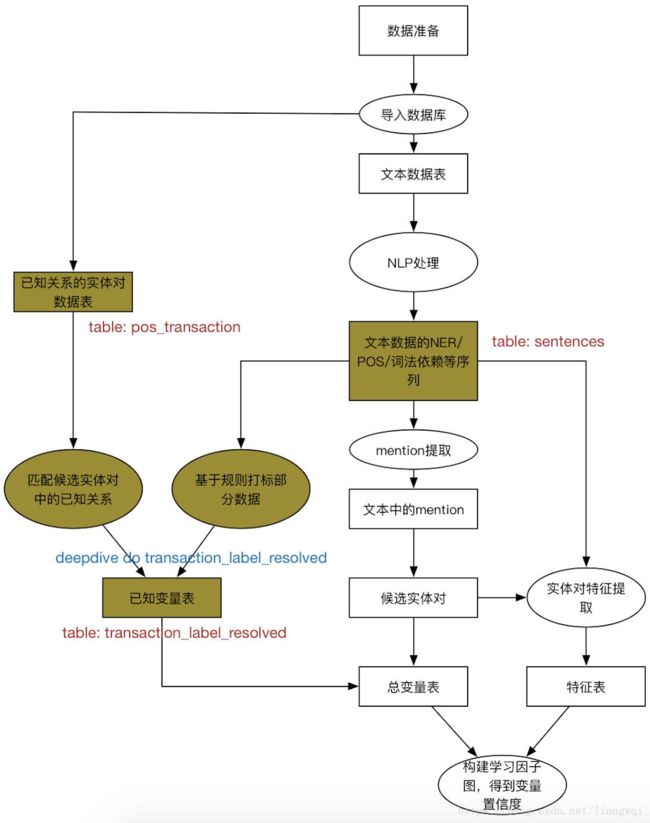
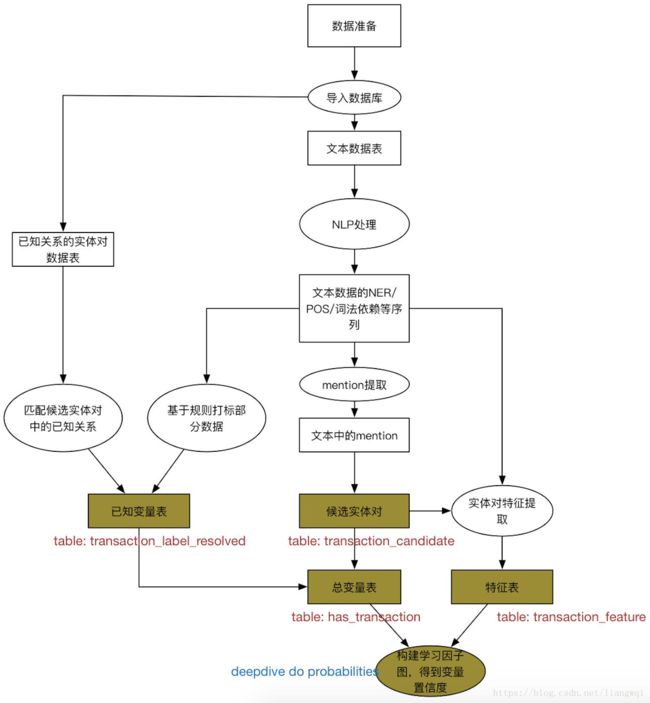
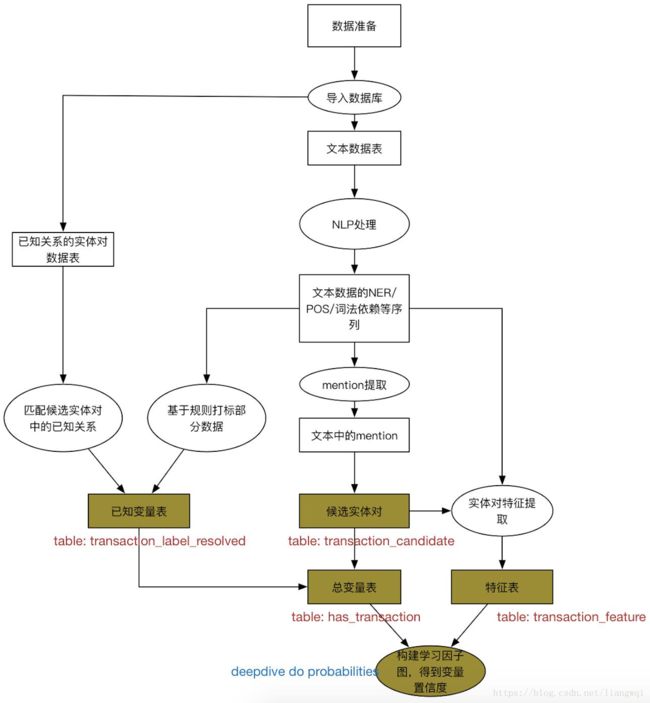
框架实战:抽取上市公司中的股权交易关系
 先验数据导入
先验数据导入
准备抽取所需的先验数据 (国泰安)
从知识库中获得已知具有交易关系的实体对
命名为pos_transaction.csv,放在input文件夹下
在app.ddlog中定义相应的数据表

-
命令行生成postgresql数据表
$ deepdive do pos_transaction
对于定义输入的表格,deepdive会自动去input文件夹下找到同名csv文件,在postgresql里建表导入
待抽取文章导入
准备待抽取的文章,命名为articles.csv,放在input文件夹下 (上市公司公告)
在app.ddlog中定义文章数据表,包括doc_id和content
同理,用deepdive do articles导入文章到postgresql里
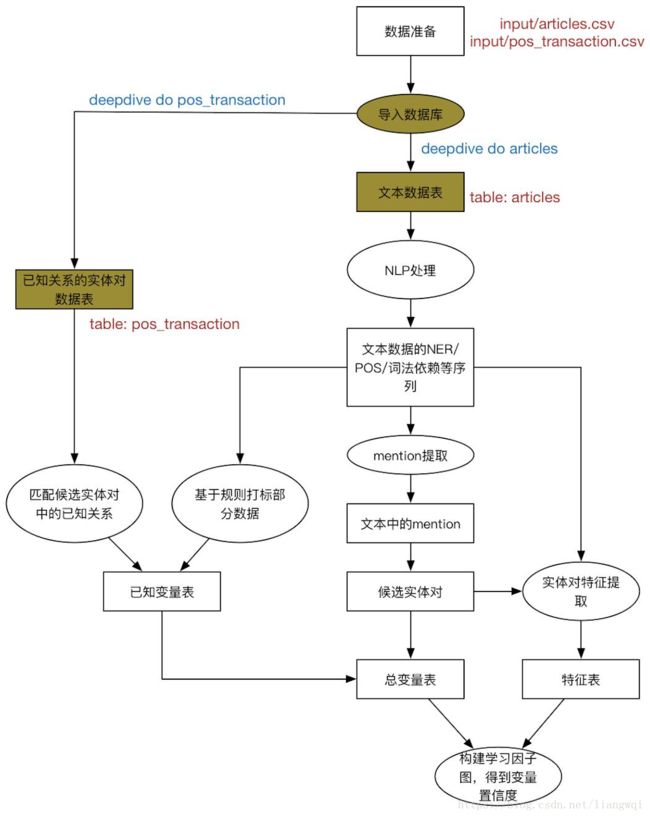 文章数据预处理
文章数据预处理
对数据库中的文章数据进行NLP解析,为后续特征抽取做准备
在app.ddlog中定义sentences表,用于存放POS、NER等字段
 定义NLP处理的函数nlp_markup
定义NLP处理的函数nlp_markup
输入为doc_id和content,输出按sentence表的字段格式
函数调用nlp_markup.sh这个脚本实现NLP的处理,可自由发挥
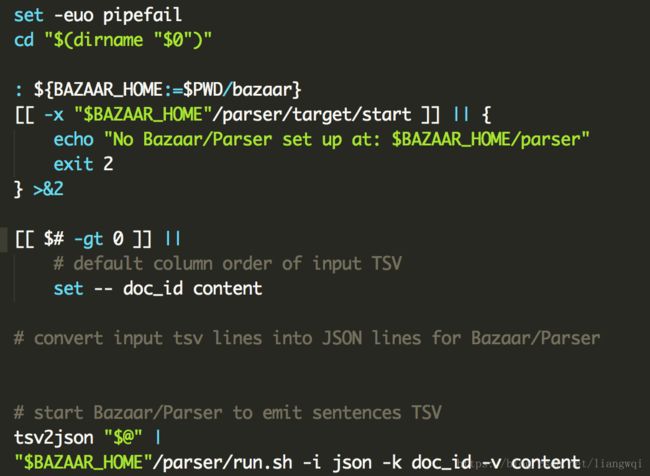
 nlp_markup.sh
nlp_markup.sh
这里是调用udf/bazaar/parser下的run.sh进行实现的,run.sh调用了stanford nlp集成好的jar包。
这一步要逐句做NER、词法分析等,耗时比较久。
把输入的articles的行转化为json,传给stanford nlp
-
函数调用,从articles表中读取输入,输出存放sentences表中
 编译并执行$ deepdive do sentences,生成sentences表
编译并执行$ deepdive do sentences,生成sentences表
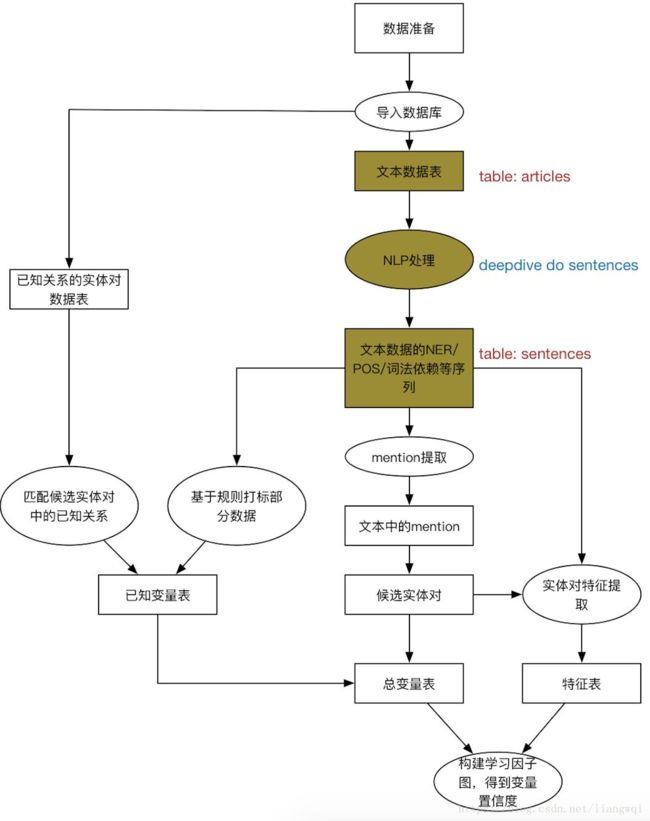 候选实体抽取
候选实体抽取 抽取文本中的候选实体
在app.ddlog中定义候选实体表

定义候选实体抽取的函数map_company_mention
输入为sentence的token和对应的NER标签
函数调用map_company_mention.py抽取NER为ORG的标签,并返回实体和在句中的位置
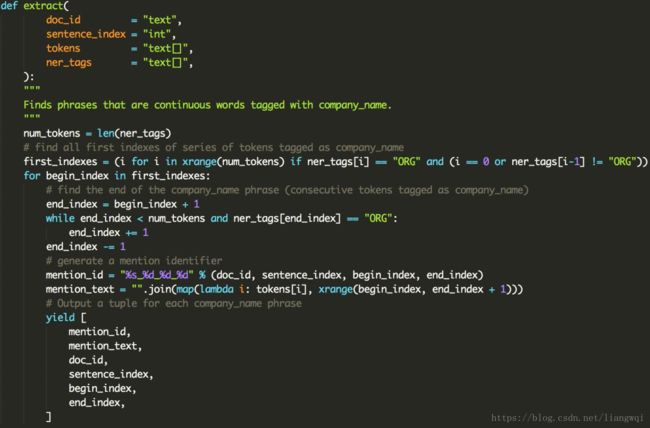
 map_company_mention.py
map_company_mention.py
找到连续的ORG标签作为实体,并定位实体位置。
可在此处对一些误识别的非实体进行过滤。
找到每个ORG标签起始位置,从起始位置往后遍历,找到结束位置
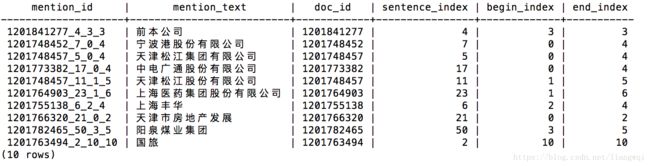
 函数调用,从sentences表中读取输入,输出到company_mention中
函数调用,从sentences表中读取输入,输出到company_mention中
 编译并执行$ deepdive do company_mention,生成候选实体表
编译并执行$ deepdive do company_mention,生成候选实体表
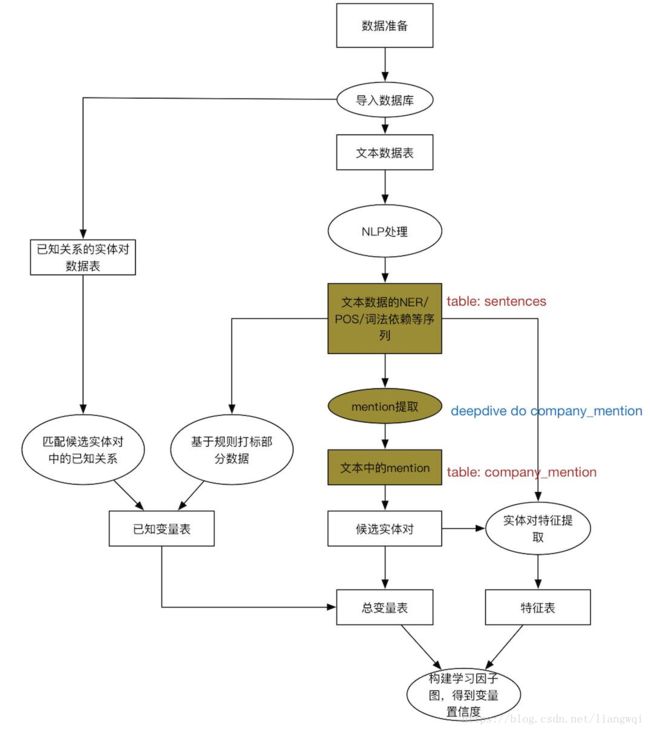
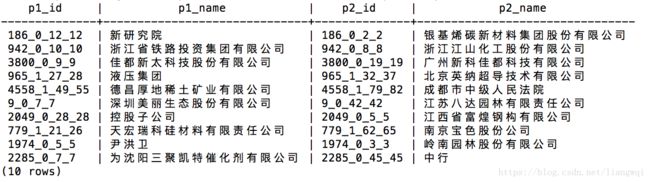
Join实体表,筛选出在同句中的不同实体,生成候选实体对
 编译并执行$ deepdive do transaction_candidate,生成候选实体对表
编译并执行$ deepdive do transaction_candidate,生成候选实体对表
-
 特征抽取
特征抽取
抽取候选实体对的文本特征
在app.ddlog中定义特征表
定义特征抽取的函数extract_transaction_features
输入为sentence的NLP结果,输出NLP组合的各种特征
函数调用extract_transaction_features.py,脚本调用自带

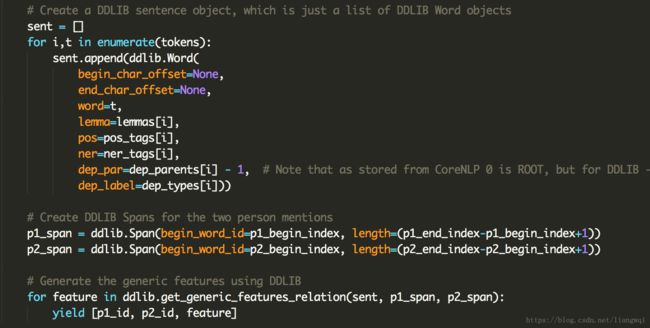
 extract_transaction_features.py
extract_transaction_features.py
调用ddlib库,得到各种POS/NER/词序列的窗口特征,此处可以自定义特征
每个实体对都要生成大量特征,这一步耗时比较久。
 extract_transaction_features.py
extract_transaction_features.py
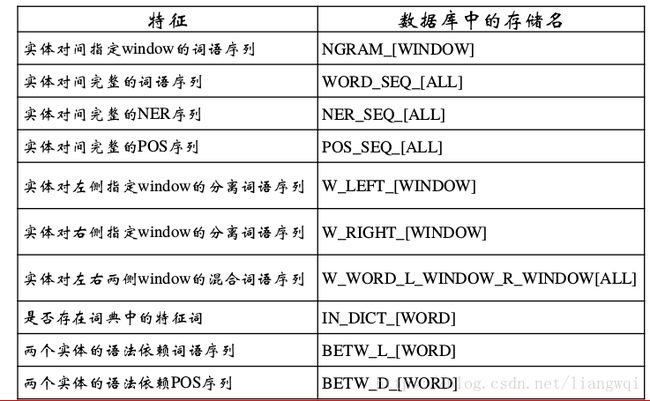
Ddlib自带的一些特征如下:
 Join sentences表和mention表作为输入,输出到transaction_feature
Join sentences表和mention表作为输入,输出到transaction_feature

编译并执行$ deepdive do transaction_feature,生成特征表(下图是部分窗口词特征)

 样本打标
样本打标
从候选实体对中标出部分正负例
利用已知的实体对和候选实体对关联
利用规则打部分正负标签
在app.ddlog中定义标签表
导入所有的候选实体对,初始标签均为0

将db数据与候选实体对关联,关联到的权重标注为+3,规则标记为从知识库得到
 通过规则再标注一部分实体,输入候选实体对的关联文本,进行打标
通过规则再标注一部分实体,输入候选实体对的关联文本,进行打标
 将规则抽取的标签也加入到transaction_label中
将规则抽取的标签也加入到transaction_label中

 规则在supervise_transaction.py中定义
规则在supervise_transaction.py中定义
最后,在多条规则和知识库标记的结果中为每对实体做vote,执行deepdive do transaction_label_resolved生成最终标签。

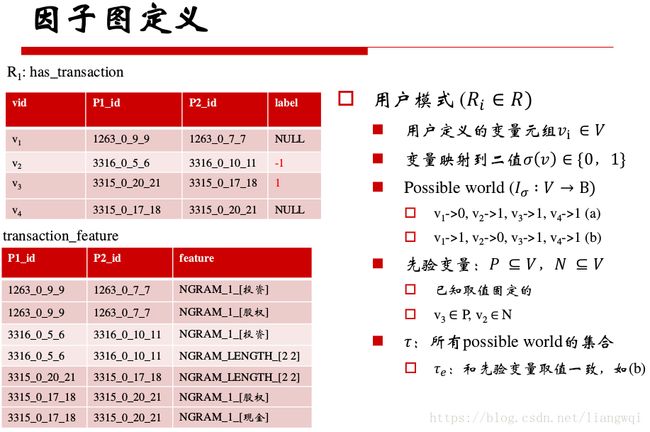
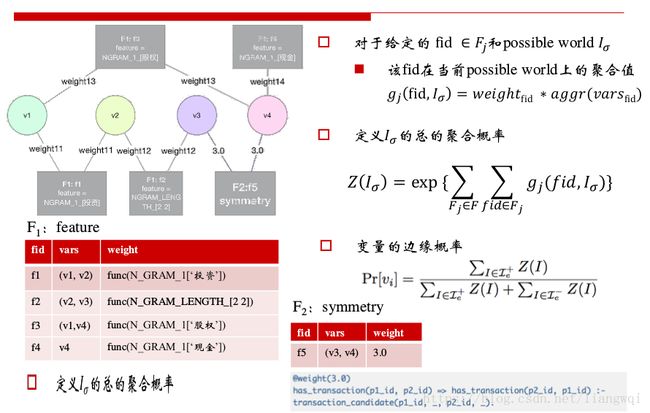
因子图构建
定义最终存储的表格,「?」表示此表是用户模式下需要推导label的最终表。

定义一系列推导关系,构建因子图
 根据打标的结果,灌入已知的变量
根据打标的结果,灌入已知的变量

对于给定的 fid ∈ F j 和possible world I σ
该fid在当前possible world上的聚合值g j fid, I σ = weight fid ∗ aggr(vars fid )
定义I σ 的总的聚合概率
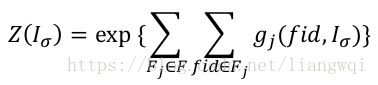
变量的边缘概率
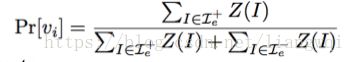
 吉布斯采样
吉布斯采样
采样得到符合内在条件概率的possible world集合
先随机一个possible world I 0
根据每个变量的相关变量,依次更新每个变量v的边缘概率
得到新的possible world I 1 ,再循环
不共享factor的变量独立sample
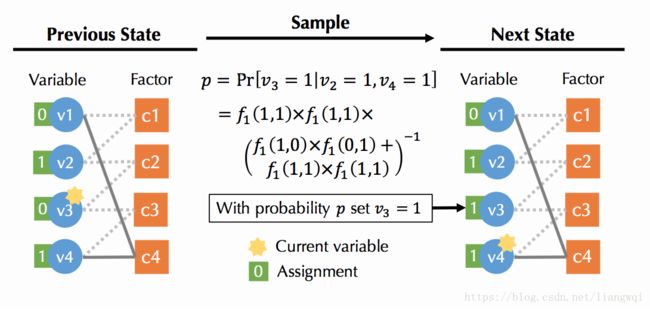 权重学习
权重学习
最大化和先验变量取值一致的possible world的数目
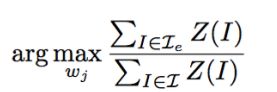
在采样得到的样本上随机梯度下降
deepdive针对硬件做了优化,支持分布式、增量式训练
执行deepdive do probablities,开始训练。
 其他配置文件
其他配置文件
迭代调试
$ deepdive do calibration_plots
系统自动在run/model/calibration_plots下生成此图
 (a) 横轴表示模型输出的分数,纵轴是该分数段的 正例率。越趋近蓝色标准线,模型效果越好。
(a) 横轴表示模型输出的分数,纵轴是该分数段的 正例率。越趋近蓝色标准线,模型效果越好。
(b) 测试集上置信度的分布,越靠近横轴两端,说明模型区分度越好。
(c) 全集上置信度的分布。
$ mindbender tagger labeling/*/mindtagger.conf
Mindtagger是deepdive提供的一套可视化工具,可参考http://deepdive.stanford.edu/labeling 搭建环境
执行完毕后,会开启web服务,默认通过http://localhost:8000访问
 可以通过特征的weight,分析置信度的误差,调整先验数据等
可以通过特征的weight,分析置信度的误差,调整先验数据等
$ mindbender search update && mindbender search gui
直接执行,默认通过http://localhost:8000访问
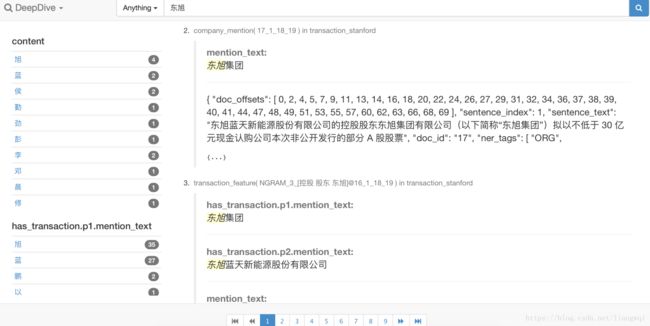 可以通过可视搜索功能,方便定位要找的实体/特征等
可以通过可视搜索功能,方便定位要找的实体/特征等
总结
模块化、便于更改替换
NLP影响较大,可以考虑尝试其他端到端模型
便于分析和迭代开发
-
开放域关系抽取
IE的发展趋势
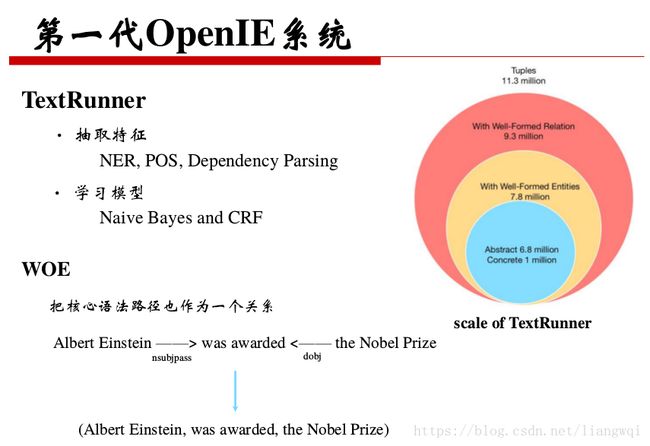
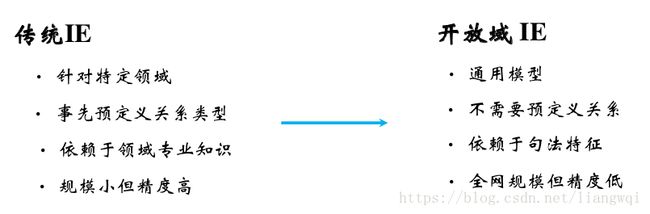 主要系统
主要系统

传统IE和OpenIE互相补充,可以按当前知识库的规范数据,链接更多网络数据。OpenIE得到的三元组可以用扩充知识库。
 面临的挑战
面临的挑战
•关系不一致、不准确
E.g. Peter thought that John began his career as a scientist
True: (John, began, his career as a scientist)
False: (Peter, began, his career as a scientist)
•提取的关系不包含有效信息
E.g. Al-Qaeda claimed responsibility for the 9/11 attacks
True: (AI-Qaeda, claimed responsibility, for the 9/11 attacks)
False: (Al-Qaeda, claimed, responsibility)
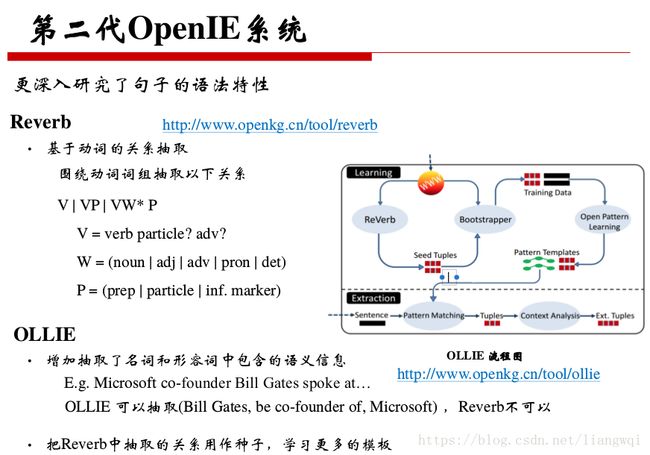

更多进展
模型
• 联合训练
训练一个统一模型,同时抽取实体和关系
• 模板匹配 + 深度学习
• 矩阵因式分解等所有好用的分类器
源数据
结构化的知识库,可以依赖知识库进行更好的链接和特征抽取
知识挖掘
-
-
实体消歧与链接
-
• 给定一篇文本中的实体指称(mention),确定这些指称在给定知识库中的目标实体 (entity)
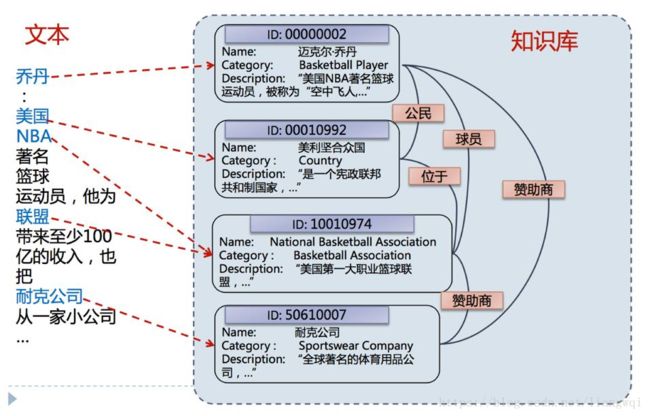
百科型知识库,适用于长文本场景
构建实体关联图
实体关联图由3个部分组成:
(1) 每个顶点Vi=
(2) 每个顶点得分 :代表实体指称mi的目标实体为ei概率可能性大小
(3) 每条边的权重:代表语义关系计算值,表明顶点Vi和Vj的关联程度
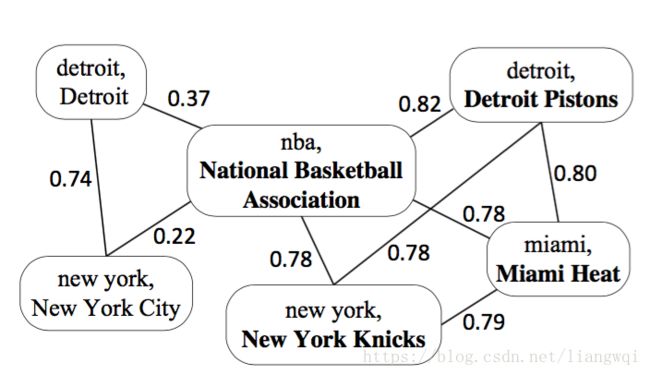
顶点的得分初始化方法:
(1) 若顶点V实体不存在歧义,则顶点得分设置为1;
(2) 若顶点中mention和entity满足p(e|m)>=0.95,则顶点得分也设置为1。
(3) 其余顶点的得分设置为p(e|m)。
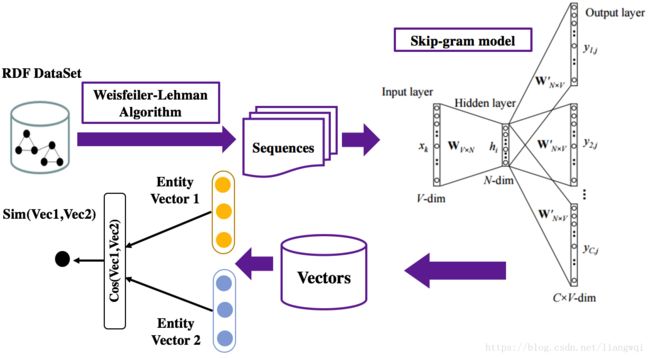
边权初始化方法:深度语义关系模型
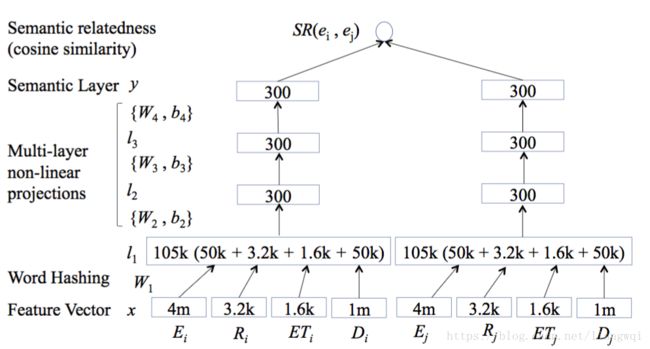 基于图的标签传播算法
基于图的标签传播算法
(1) 构造相似矩阵
(2) 迭代传播直到收敛算法结束
 百科型知识库,适用于长文本场景
百科型知识库,适用于长文本场景
 候选实体间语义相似度计算
候选实体间语义相似度计算
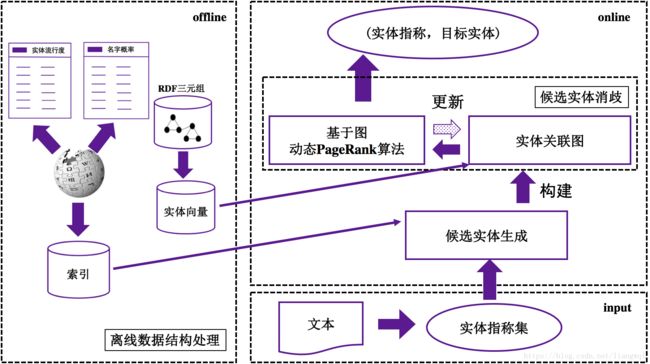
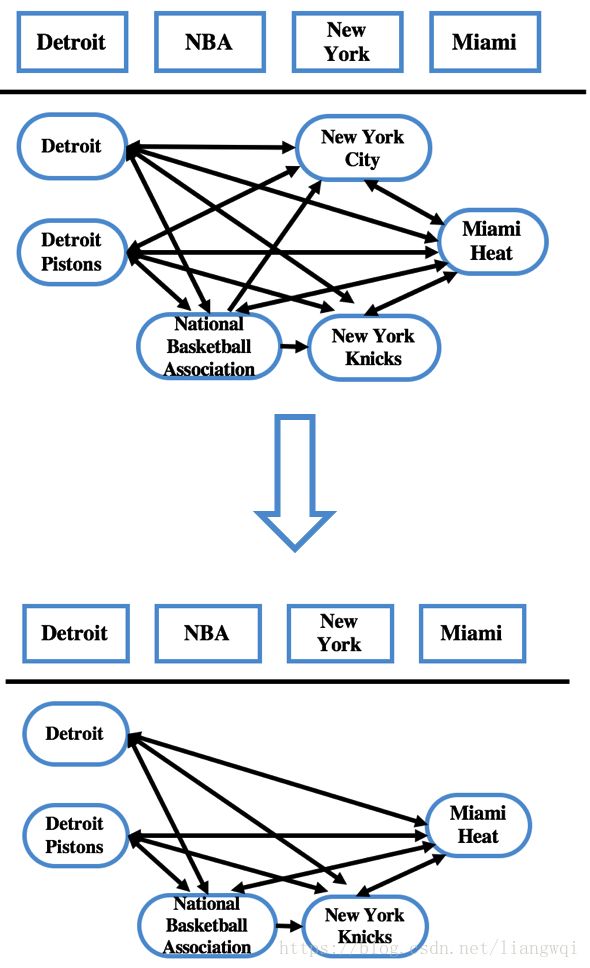
 构建实体关联图
构建实体关联图
实体关联图由四个部分组成:
(1) 实体指称节点
(2) 候选实体节点
(3) 候选实体节点顶点值:代表该候选实体是实体指称的目标实体概率大小
(4) 候选实体节点边权值:代表两个候选实体间的转化概率大小
各候选实体节点顶点值:初始化为均等,之后每轮更新为上一轮的PageRank得分候选实体节点边权值计算公式如下:
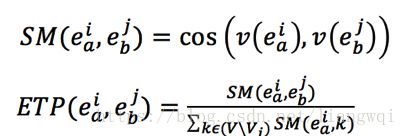
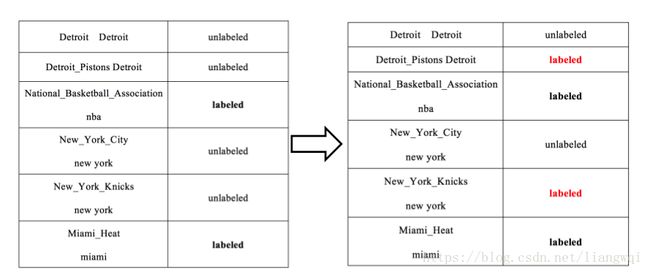
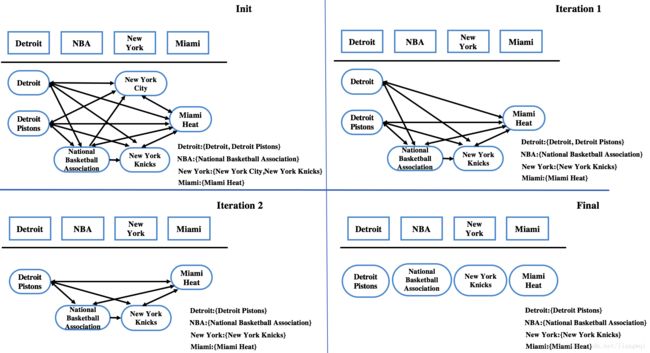
 更新实体关联图
更新实体关联图
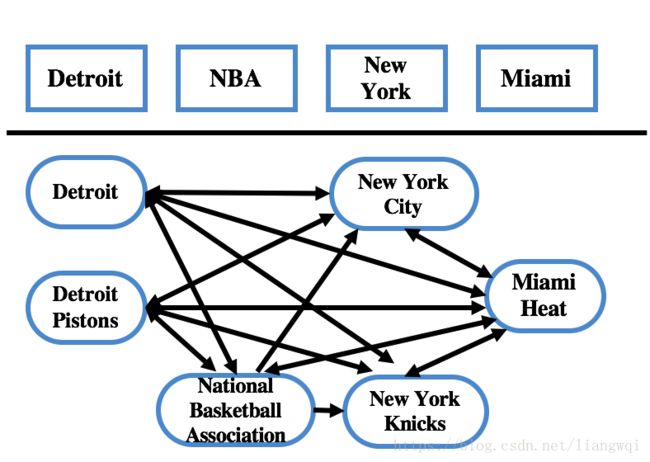
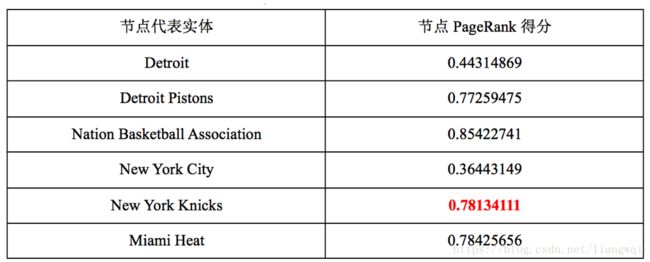 选择本轮最高得分的未消歧实体 New York Knicks作为实体指称New York的最佳实体,删除其他候选实体 NewYork City及相关的边,更新图中的边权值。
选择本轮最高得分的未消歧实体 New York Knicks作为实体指称New York的最佳实体,删除其他候选实体 NewYork City及相关的边,更新图中的边权值。
实体消歧整体过程示例
-
 总结
总结
知识库的变更:从百科知识库发展到特定领域知识库
实体链接的载体:从长文本到短文本,甚至到列表和表格数据
候选实体生成追求同义词、简称、各种缩写等的准备和高效从Mention到实体候选的查找
实体消歧则考虑相似度计算的细化和聚合,以及基于图计算协同消歧
-
知识规则挖掘
Stactical Schema Induction
基于归纳逻辑编程 (Inductive Logic Programming, ILP)
的方法
使用精化算子 (refinement operators)
基于统计关系学习 (Statistical Relational Learning, SRL)的方法
主要对贝叶斯网络进行扩展
基于关联规则挖掘 (Association Rule Mining,ARM)的方法
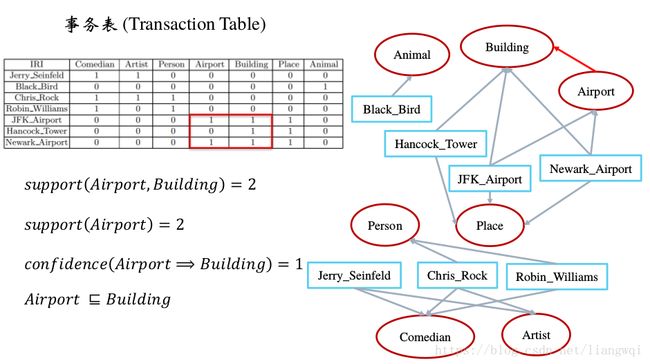
1构建事务表
2挖掘规则
3将规则转换为OWL公理
4构建本体
关联规则挖掘 (ARM)
OWL2公理可被转换为关联规则

示例
公理 (Axiom) 规则 (Rules)
C⊑D C ⇒ {D}
规则 C ⇒ {D} 意味着:概念C的实例同时也属于概念D
规则的置信度 (confidence)越高,C ⊑ D越可能成立
事务表 (Transaction Table)
 统计关系学习 (SRL)
统计关系学习 (SRL)
输入
实体集合 {e i}
关系集合{ r k}
已知三元组集合 {(e i , r k , e j)}
目标
根据已知三元组对未知三元组成立的可能性进行预测
P((e i , r k , e j) = 1)
可以应用于知识图谱补全
基于图的方法
基本思想
将连接两个实体的路径作为特征来预测其间可能存在的关系
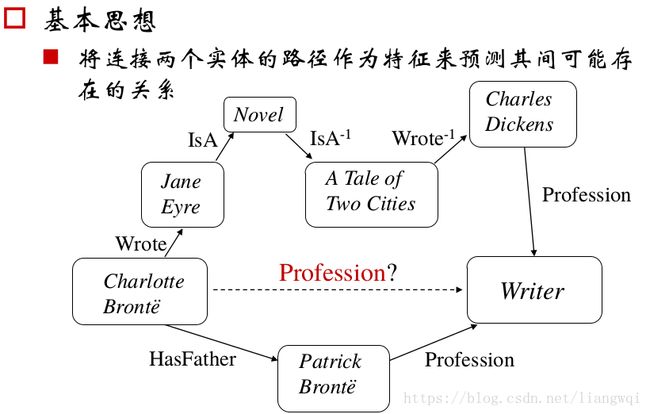
路径排序方法
通用关系学习框架 (generic relational learning framework)

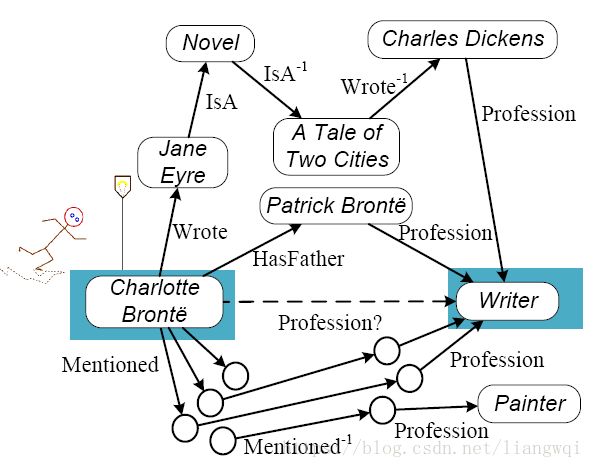
Profession(Charlotte Bonte, Writer)?

Q: all path types starting from s and ending with t (with length of n)
θ: weights obtained by training
Probability of a path type
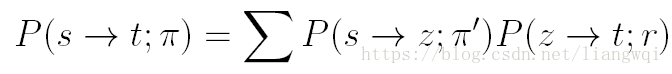 P:the probability of reaching target node t starting from source node s and following path Use dynamic programming procedure
P:the probability of reaching target node t starting from source node s and following path Use dynamic programming procedure
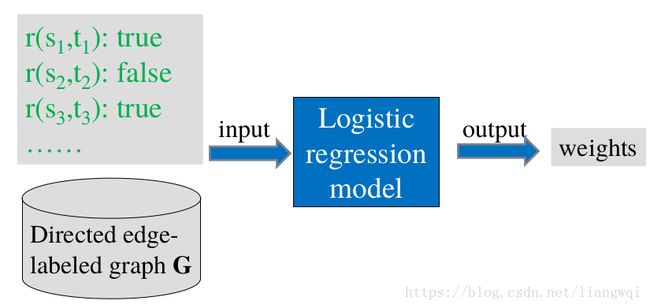
Weight training (offline)
-
知识图谱表示学习
建立统一的语义空间,语义可计算
实体预测和推理
输入:实体、关系、属性、描述、上下文词
输出:表示模型
使用时,要确信两个实体关系的关系,把两个实体输入训练好的模型;模型输出关系向量,计算输出向量和关系向量词典距离找出最可能的关系作为输出。
关系推理
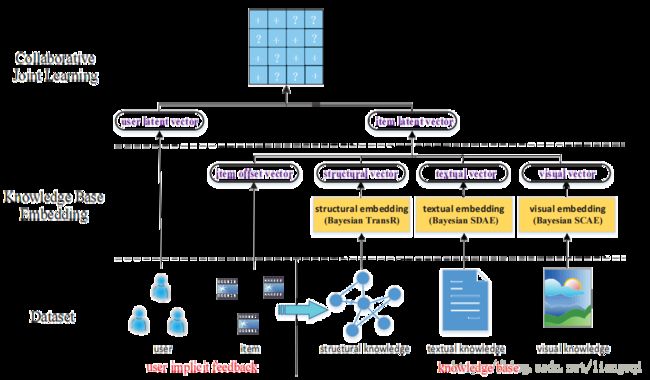
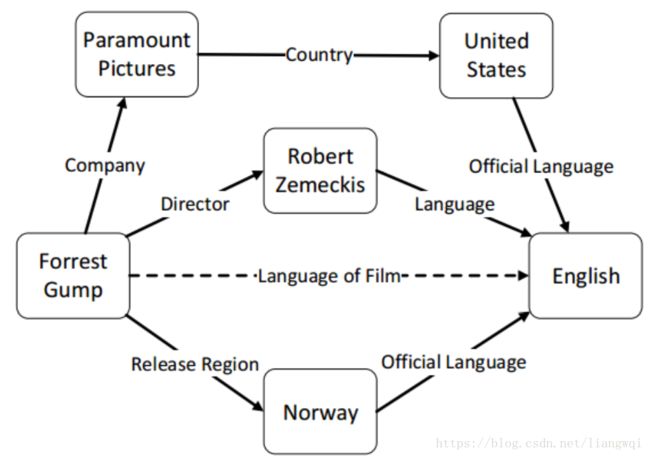 推荐系统
推荐系统
 TransE
TransE
 无法处理一对多、多对一和多对多问题关系的性质
无法处理一对多、多对一和多对多问题关系的性质
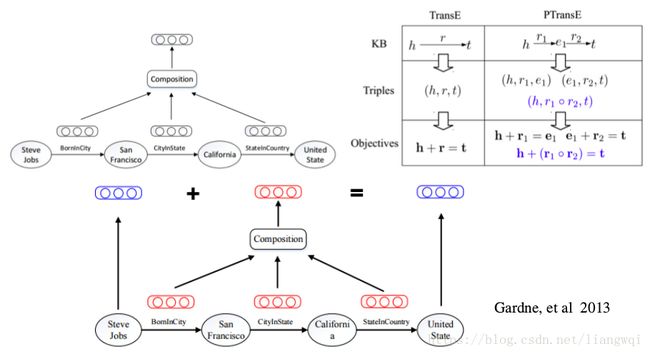
PRA vs. TransE
两类方法之间存在互补性
• PRA
可解释性强
能够从数据中挖掘出推理规则
难以处理稀疏关系
路径特征提取效率不高
• TransE
– 能够表示数据中蕴含的潜在特征
– 参数较少,计算效率较高
– 模型简单,难以处理多对一、一对多、多对多的复杂关系
– 可解释性不强
路径的表示学习
TransE孤立地学习每个事实三元组,关系之间存在复杂关系,涉及关系推理
 加入规则的表示学习
加入规则的表示学习
 多模态的表示学习
多模态的表示学习
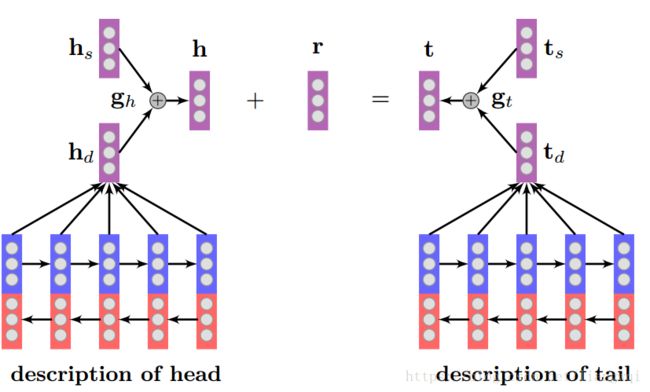 基于知识图谱图结构的表示学习
基于知识图谱图结构的表示学习
哪些数据可以用来描述实体
实体周围的实体
从一个实体到这个实体的联通路径
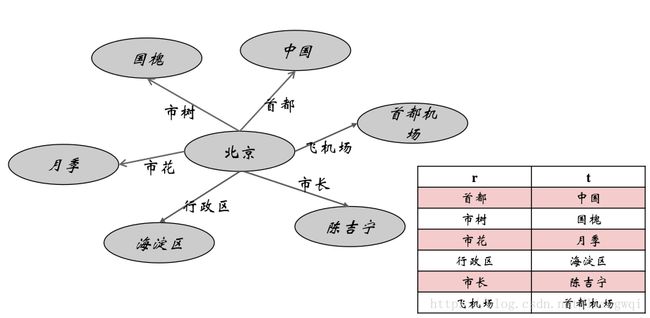
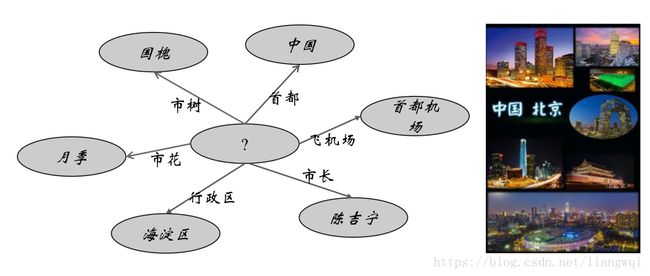 Neighbor Context
Neighbor Context
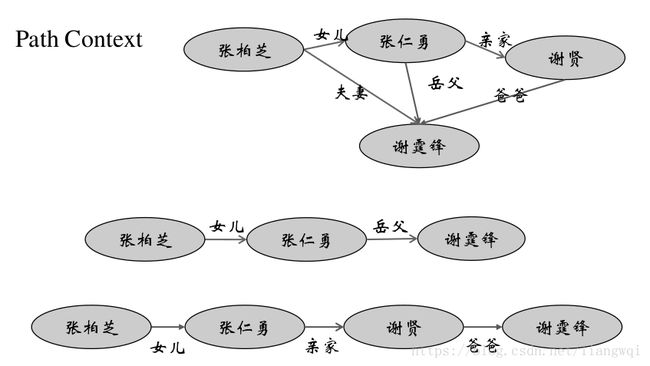
 Path Context
Path Context
 Triple Context = Triple + Path Context + Neighbor Context
Triple Context = Triple + Path Context + Neighbor Context
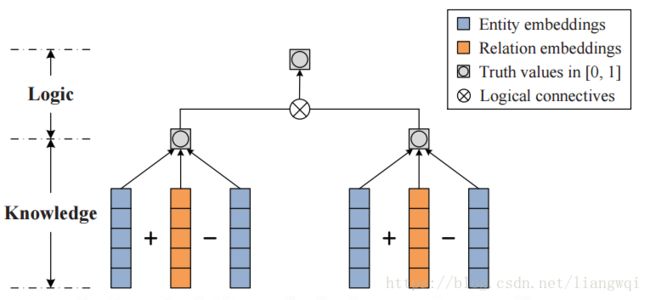
势能函数
希望三元组在Triple Context概率最大
![]()

假设不同的Context都是相互独立的企且独立用来描述三元组的某一部分
目标函数
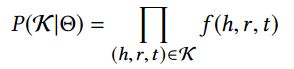
实验结果
在一对多、多对多、多对一下均有较好的表现
如果用TransE训练后的结果作为输入还有提高的空间
总结和挑战
融合更多本体特征的知识图谱表示学习算法研发
知识图谱表示学习与本体推理之间的等价性分析
知识图谱学习与网络表示学习之间的异同
神经符号系统