Android dumpsys cpuinfo 信息解读
Android dumpsys命令详细使用 :https://blog.csdn.net/jingwen3699/article/details/82631235
adb shell dumpsys cpuinfo
Load: 0.72 / 0.79 / 0.85
CPU usage from 729557ms to 163888ms ago (2019-06-05 16:33:41.670 to 2019-06-05 16:43:07.338):
45% 754/system_server: 43% user + 2.1% kernel / faults: 3258 minor
3.6% 191/logd: 3% user + 0.5% kernel / faults: 22 minor
2.2% 21046/adbd: 0.5% user + 1.7% kernel / faults: 70590 minor
2.2% 524/zygote: 0.4% user + 1.7% kernel / faults: 71347 minor
0.6% 40/cfinteractive: 0% user + 0.6% kernel
0.3% 392/ksdioirqd/mmc2: 0% user + 0.3% kernel
0.3% 4714/logcat: 0.1% user + 0.1% kernel
0.3% 216/surfaceflinger: 0.1% user + 0.1% kernel / faults: 487 minor
0.2% 290/idsd: 0.2% user + 0% kernel / faults: 217 minor
0.1% 1140/RTW_CMD_THREAD: 0% user + 0.1% kernel
0.1% 7/rcu_preempt: 0% user + 0.1% kernel
0.1% 910/com.android.systemui: 0.1% user + 0% kernel / faults: 207 minor
0.1% 148/mmcqd/1: 0% user + 0.1% kernel
0.1% 1341/com.android.launcher3: 0% user + 0% kernel / faults: 641 minor
+0% 10890/kworker/1:1: 0% user + 0% kernel
+0% 11600/kworker/2:1: 0% user + 0% kernel
+0% 13223/kworker/0:0: 0% user + 0% kernel
+0% 14550/kworker/u8:1: 0% user + 0% kernel
+0% 15769/kworker/1:0: 0% user + 0% kernel
+0% 16364/kworker/2:0: 0% user + 0% kernel
+0% 17806/kworker/0:1: 0% user + 0% kernel
17% TOTAL: 13% user + 3.3% kernel + 0% iowait + 0% softirq信息解读:
第一行显示的是cpuload (负载平均值)信息:Load: 0.72 / 0.79 / 0.85
这三个数字表示逐渐变长的时间段(平均一分钟,五分钟和十五分钟)的平均值,而较低的数字则更好。数字越大表示问题或机器过载。但是,门槛是多少?什么构成“好”和“坏”负载平均值?什么时候应该关注负载平均值,何时应该尽快解决?首先,了解负载平均值的含义。我们将从最简单的情况开始:一台带有一个单核处理器的机器。
交通比喻
单核CPU就像是单通道流量。想象一下,你是一名桥梁操作员...有时你的桥很忙,有车排成一排。您想让人们知道您的桥上的流量是如何移动的。一个合适的指标是在特定时间等待多少辆汽车。如果没有车等待,进入的司机知道他们可以立即开车。如果汽车停滞,司机知道他们有延误。
那么:
- 0.00表示桥上根本没有流量。实际上,介于0.00和1.00之间意味着没有备份,而到达的汽车将直接开启。
- 1.00表示桥梁正好处于饱和容量状态。一切都还不错,但如果流量变得更重,事情就会变慢。
- 超过1.00表示有拥堵。那么,2.00意味着总共有两条车道 - 一条车道的价值在桥上,一条车道值得等待。3.00意味着总共有三条车道 - 桥上有一条车道,两条车道值得等待。
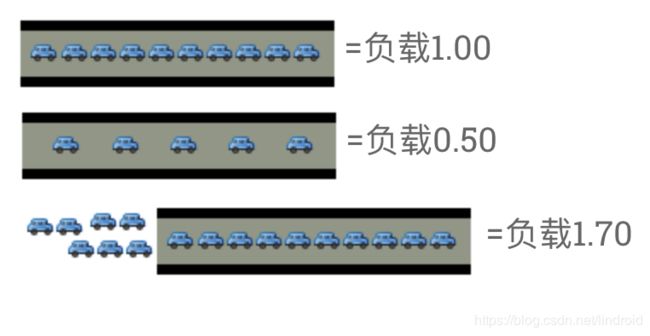
这基本上就是CPU负载。“汽车”是使用一段CPU时间(“过桥”)或排队使用CPU的过程。Unix将此称为运行队列长度:当前运行的进程数加上等待(排队)运行的进程数之和。
像桥梁操作员一样,您希望您的汽车/工艺永远不会等待。因此,CPU负载理想情况下应保持在1.00以下。也像桥梁操作员一样,如果你在1.00以上获得一些临时峰值,你仍然可以......但是当你一直高于1.00时,你需要担心。
所以你说理想负荷是1.00?
好吧,不完全是。负载为1.00的问题是您没有余量。在实践中,许多系统管理员将在0.70处绘制一条线:
-
在“需要考虑其”经验法则:0.70如果你的平均负载在上面停留> 0.70,它的时间在事态进一步恶化之前进行调查。
-
在“立即修复此问题”经验法则:1.00。如果您的平均负载保持在1.00以上,请找到问题并立即修复。否则,你将在半夜醒来,这不会很有趣。
-
在“Arrgh,这是凌晨3点WTF?” 经验法则:5.0。如果您的平均负荷高于5.00,您可能会遇到严重问题,您的任务要么悬挂要么放慢速度,或者最糟糕的时间发生故障。
那么多处理器呢?我的负载是3.00,但运行正常!
有四处理器系统?它仍然健康,负载为3.00。
在多处理器系统上,负载相对于可用处理器核心数。单核系统的“100%利用率”标记为1.00,双核为1.00,四核为4.00等。
如果我们回到桥梁类比,“1.00”真的意味着“一条车道的交通价值”。在单车道桥上,这意味着它已经填满了。在双后桥上,负载为1.00表示其容量为50% - 只有一个车道已满,因此可以填充另一条车道。
与CPU相同:1.00的负载是单核盒上的100%CPU利用率。在双核盒上,2.00的负载是100%的CPU利用率。
多核与多处理器
我们谈论这个主题时,让我们谈谈多核与多处理器。出于性能目的,具有单个双核处理器的机器基本上等同于具有两个处理器的机器,每个处理器具有一个核心?是的,这里有许多关于缓存数量,处理器之间的进程切换频率等的细微之处。尽管有这些更精细的点,但为了确定CPU负载值的大小,核心的总数是重要的,无论如何这些核心分布在许多物理处理器上。
这导致我们有两个新的经验法则:
-
“核心数=最大负载”经验法则:在多核系统上,您的负载不应超过可用核心数。
-
该“内核是内核”经验法则:核心是如何分布在CPU的无所谓。两个四核==四个双核==八个单核。这些都是用于这些目的的八个核心。
疑问:
我应该观察哪个平均值?一,五或十五分钟?
对于我们已经谈过的数字(1.00 =现在修复等),你应该看看5或15分钟的平均值。坦率地说,如果你的盒子在一分钟的平均值上突然超过1.0,你仍然可以。当15分钟的平均值偏离1.0并且保持在那里你需要捕捉到。(显然,正如我们所了解的那样,将这些数字调整为系统所具有的处理器核心数)。
因此,核心数量对于解释负载平均值很重要...我如何知道我的系统有多少核心?
cat /proc/cpuinfo获取系统中每个处理器的信息。
更多:
理解Linux CPU负载和 CPU使用率 https://www.cnblogs.com/muahao/p/6492665.html
解决Linux 负载过高问题过程记录 https://blog.csdn.net/gu_study/article/details/81942939