集成学习
集成学习
这篇博客是在学习集成学习时总结多篇博客和文章,再加上自己一些看法和补充的结果。具体参考的博客和文章见文末参考文献。
集成学习概述
集成学习(Ensemble learing)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器效果更好的一种机器学习方法。对于训练数据,我们通过若干个个体学习器,通过一定的聚合策略,就可以形成一个强学习器,以达到博采众长的目的。
也就是说,集成学习主要有两个问题,一是如何得到若干个个体学习器,二是如何选择一种结合策略,将这些弱学习器集成强学习器。
集成学习之个体学习器
个体学习器有两种选择。一种是所有个体学习器是一个种类的,或者说是同质的,比如都是决策树或者神经网络。另一种是所有个体学习器不全是一个种类的,或者说是异质的,比如对训练集采用KNN,决策树,逻辑回归,朴素贝叶斯或者SVM等,再通过结合策略来集成。
目前来说,同质的个体学习器应用最广泛,一般我们常说的集成方法都是同质个体学习器。而同质学习器使用最多的是CART决策树和神经网络。另外,个体学习器之间是否存在依赖关系可以将集成方法分为两类。一类是个体学习器之间存在强依赖关系,即串行,代表算法是boosting系列算法(Adaboost和GBDT),另一类是个体学习器之间不存在依赖关系,即并行,代表算法是bagging和随机森林。下面分别对这两类算法做一个总结。
集成学习之boosting
boosting算法的工作机制是给每一个样本分配一个初始权重,然后用训练样本和权重训练处弱分类器1,根据弱分类器1更新样本的权重,再训练弱分类器2,如此重复进行,直到学习器达到指定的数目,最终将这些弱学习器集成强学习器。可以看出各个弱分类器之间是串行的。
boosting系列算法中最著名的是有Adaboost和提升树(boosting tree),提升树中应用最广泛的是GBDT(梯度提升树)。
集成学习之bagging
bagging算法的各个弱分类器是并行的,相互之间没有影响,可以单独训练。但是单个学习器的训练数据是不一样的。假设原始数据中有n个样本,有T个弱学习器,在原始数据中进行T次有放回的随机采样,得到T个新数据集,作为每个弱分类器的训练样本,新数据集和原始数据集的大小相等。每一个新数据集都是在原始数据集中有放回的选择n个样本得到的。
随机森林是bagging的一个特化进阶版,特化是指随机森林的弱学习器都是决策树,进阶是指随机森林在bagging的基础上,又加上了特征的随机选择,其基本思想和bagging一致。
集成学习之弱学习器集合策略
在上面几节中主要关注弱学习器,但是没有说学习器如何结合。假定我们有T个若学习器 {h1,h2,hT}
- 对于回归的平均法:对于回归问题,通常使用的是平均法,也就是说将T个弱学习器的输出进行平均作为最终的预测输出。最简单的是算数平均 H(x)=1T∑Ti=1hi(x) 。也可使用加权平均,如果每一个学习器都有自己的权重 wi,wi≥0,∑Ti=1wi=1 ,则最终的预测结果是 H(x)=∑Ti=1wihi(x)
- 对于分类的投票法:对于分类问题最常用的是投票法。最简单的是多数投票法,也就是T个学习器对样本都有自己的预测类别,数量最多的类别作为最终的分类结果。如果不只一个类别获得最高票,则随机选择一个。稍微复杂一些的是过半投票法,在多数投票法的基础上,不仅要最高票,还需要票数过半,否则拒绝预测。更加复杂的是加权投票法,每个弱学习器都有自己的权重,最终将各个类别加权求和,最大的值对应的类别作为最终类别。
- 学习法:上面两种方法将弱学习器的结果做平均,相对比较简单,可能学习误差较大,于是就有了学习法,代表方法是stacking。当使用stacking的结合策略时,我们不是对弱学习器的结果做简单的处理,而是加上了一层学习器。将弱学习的结果作为输入,重新训练一个学习器得到最终的结果。
以上是集成学习的框架,接下来要学习三种集成学习的具体算法,有boosting算法中的Adaboost和GBDT以及bagging中的随机森林。
偏差和方差
经常听到一种税法,bagging是减少variance,而boosting是减少bias?。那么什么是模型的方差和偏差呢?又为什么会有这种说法呢?
理解偏差和方差可以提高模型的准确率。我们从三方面定义偏差和方差:概念,图形和数学
概念
偏差是模型的平均预测的目标值和真实目标值之间的差距。差距小,则偏差小,差距大,则偏差大。得到的是模型的准确性。
方差是给定样本点,通过模型得到该样本点目标值的变化情况。如果多次得到的预测值变化小,则方差小,反之,则方差大。得到的是模型的确定性。
当然,只有一个模型是不能得到预测值的平均情况和变化情况的。通常测量模型的偏差和方差是通过k折交叉验证得到的。
图形
结合偏差和方差的各种情况,可以得到如下图示
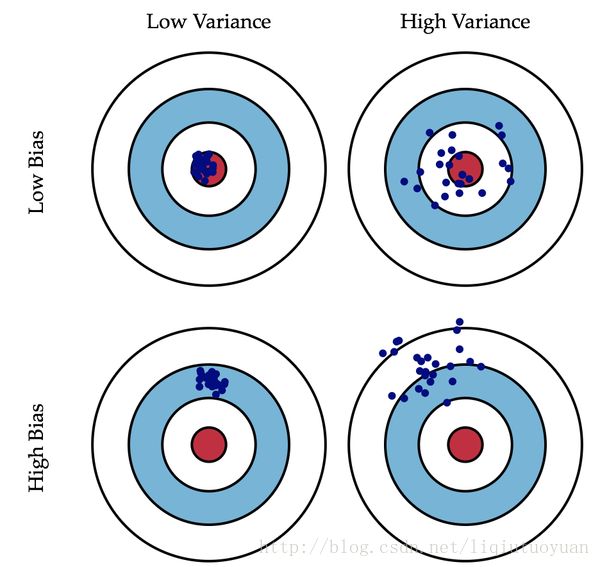
图中的红色靶心表示样本的真实目标值,蓝色离散点表示样本经过模型在交叉验证中得到多次预测值。第一行表示低偏差,预测值的平均离靶心很近,第二行是高偏差,预测值的平均离靶心较远。左一列是低方差,多次得到的预测值变化不明显,确定性高,右一列是高方差,多次得到的预测值变化明显,确定性低。
数学
给定样本X和目标值Y,模型试图建立X和Y之间的关系 Y=f(x)+ϵ 。假设我们得到了 f(x) 的估计 f^(x) ,则均方误差为
Err(x)=E[(Y−f^(x))2]=E[(Y−E[f^(x)]+E[f^(x)]−f^(x))2]=E[(Y−E[f^(x)])2+(E[f^(x)]−f^(x))2+2(Y−E[f^(x)])(E[f^(x)]−f^(x))]=(Y−E[f^(x)])2+E[(E[f^(x)]−f^(x))2]+σ=Bias2+Variance+noise可以看出,模型的误差是有三部分组成的,偏差,方差和噪声。其中噪声是数据本身的噪声,表示当前任务在任何学习算法上所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。所以说要降低一个模型的泛化误差需要使偏差和方差都达到最小。
但通常情况下,偏差度量了学习算法的期望预测值和真实结果的偏离程度,刻画了学习算法本身的拟合能力,要使得偏差小,模型通常会过拟合,便会导致方差大。所以说模型的泛化误差是偏差和方差的折中。
一般来讲,bias高时underfit的表现,variance高时overfit的表现。一个模型的泛化能力很差,即利用训练数据训练好一个模型后,将其用于测试数据集,得到的误差很高,则说明这个模型是underfit或者overfit的。
那么遇到这种情况应该怎样解决呢?有以下解决方案列表:
- 获得更多的训练数据,修正过拟合。增加训练数据对于过拟合是有所改善的,但是对于欠拟合是没有用的;
- 尝试使用较少的特征,修正过拟合。可以使特征的参数稀疏,或者使用正则化;
- 增加正则项系数,修正过拟合
- 使用更多的特征,修正欠拟合
- 使用非线性模型,修正欠拟合
- 减小正则化系数,修正欠拟合
理解了偏差和方差,现在来看集成学习中的一句话,“bagging是减少variance,而boosting是减少bias?”。
我们常说集成学习框架中的基模型是弱模型,通常来说弱模型是偏差高(在训练集上准确度低)方差小(防止过拟合能力强)的模型。但是,并不是所有集成学习框架中的基模型都是弱模型。bagging和stacking中的基模型为强模型(偏差低方差高),boosting中的基模型为弱模型。
在bagging和boosting框架中,通过计算基模型的期望和方差,我们可以得到模型整体的期望和方差。为了简化模型,我们假设基模型的权重、方差及两两间的相关系数相等。由于bagging和boosting的基模型都是线性组成的,那么有:

对于boosting来说,基模型的训练集抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对boosting化简公式为:
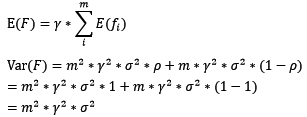
通过观察整体方差的表达式,我们容易发现,若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,boosting框架中的基模型必须为弱模型。
因为基模型为弱模型,导致了每个基模型的准确度都不是很高(因为其在训练集上的准确度不高)。随着基模型数的增多,整体模型的期望值增加,更接近真实值,因此,整体模型的准确度提高。但是准确度一定会无限逼近于1吗?仍然并不一定,因为训练过程中准确度的提高的主要功臣是整体模型在训练集上的准确度提高,而随着训练的进行,整体模型的方差变大,导致防止过拟合的能力变弱,最终导致了准确度反而有所下降。
基于boosting框架的Gradient Tree Boosting模型中基模型也为树模型,同Random Forrest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
对于bagging来说,每个基模型的权重等于1/m且期望近似相等(子训练集都是从原训练集中进行子抽样),故我们可以进一步化简得到:
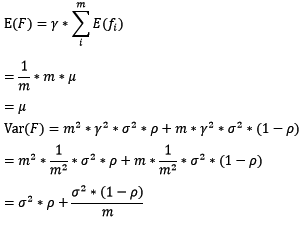
根据上式我们可以看到,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
Random Forest是典型的基于bagging框架的模型,其在bagging的基础上,进一步降低了模型的方差。Random Fores中基模型是树模型,在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,第一项显著减少,第二项稍微增加,整体方差仍是减少。
那么子模型之间的相关性是如何度量的呢?这里主要从样本抽样的角度理解。在boosting中,个子模型的样本一样,所以相关性为1。在bagging中有随机抽样的过程,如果每次抽样的样本完全不重复,则说子模型完全独立,相关性为0,。但是在bagging算法和随机森林中的随机抽样得到的数据集不是完全独立的,总是有重合的,所以此时的相关性介于前两种情况中间,具有一定的相关子那个。从bagging的方差公式中可以看出,当相关性减小是,可以减小整体模型的方差。
综上所述,boosting的弱学习器是高偏差低方差的,因为boosting算法不能减小方差,只能通过集成的策略减小偏差,整体模型的方差依赖于弱学习器的方差,所以弱学习器的方差要小。bagging的弱学习器是低偏差高方差的,因为bagging算法不能改变弱学习器的偏差,但是通过集成策略能显著减小方差,所以其弱学习器的偏差要小,可以过拟合。
boosting之Adaboost
boosting算法的基本思想如下图:

从图中可以看出,boosting算法的工作机制是先初始化样本的权重,利用样本和权重训练出一个弱学习器1,根据弱学习器的学习误差率更新权重系数,利用权重系数更新样本权重,然后基于更新后的权重和样本训练弱学习器2,重复以上的过程,指代弱学习器的个数达到指定的数目,最终将这些弱学习器集成,得到强学习器。
所以boosting算法中有以下几个问题需要解决:
- 如何训练弱学习器
- 如何计算学习误差率 e
- 如何更新弱学习器权重系数 α
- 如何更新样本权重 D
- 使用哪一种集成策略
只要是boosting大家族的算法,都要解决以上5个问题。
Adaboost二分类算法的基本流程
这里主要解决以上5个问题
假设训练集是 T={(x1,y1),(x2,y2),...,(xn,yn)} ,训练集在第k个弱学习器上的样本权重是 [wk1,wk2,...,wkn],w1i=1n,i=1,2,...,n ,即第一个弱分类器的样本权重是自定义的。
输入:训练数据集T,弱学习算法和弱学习器个数T
输出:最终的强分类器 f(x)
初始化样本权重 D1=[w11,w12,...,w1n],w1i=1n,i=1,2,...,n
对 m=1,2,...,T
使用具有样本权重 Dm 的训练数据和弱学习器算法得到弱分类器m, Gm(x):x→{1,−1}
计算 Gm(x) 在训练数据集上的学习误差率 em=P(Gm(x)≠y)=∑ni=1wmiI{Gm(xi)≠yi}
计算弱学习器的权重系数 αm=12ln1−emem
更新样本权重 Dm+1=[wm+1,1,wm+1,2,...,wm+1,n],wm+1,i=wm,iZmexp(−αmyiGm(xi)),i=1,2,...,n
其中 Zm 是归一化因子 Zm=∑ni=1wm,iexp(−αmyiGm(xi)) ,它使得 Dm+1 成为一个概率分布
构建T个弱分类器的线性组合 f(x)=∑Tm=1αmGm(x) ,得到最终的强分类器 G(x)=sign(f(x))
对以上步骤的说明如下:
步骤1,假设训练数据集有均匀的样本权重,即每个样本在若分类器中的作用相等,并保证能够学习出第一个弱分类器
步骤2,算法反复学习弱分类器,每一轮顺序执行以下操作,也分别对应了问题1—4
使用当前的样本权重 Dm 加权的训练数据集训练基本分类器 Gm(x) ,这里的弱分类器理论上可以使用任何分类器,最常用的是CART决策树和神经网络
计算弱分类器 Gm(x) 在加权训练数据集上的分类误差率 em=P(Gm(x)≠y)=∑ni=1wmiI{Gm(xi)≠yi} 。这表明 Gm(x) 在加权训练集上的分类误差率是被 Gm(x) 错误分类的样本的权重之和
计算基本分类器的权重系数 αm=12ln1−emem 。 αm 表示弱分类器 Gm(x) 在最终强分类器中的重要性。从上式可以看出,当 em≤12 时, αm≥0 ,并且随着 em 的减小 αm 增大。这表明,弱分类器 Gm(x) 的分类误差率越小,其在最终强分类其中的比重越大。而且必须有 em≤12 否则有 αm<0 反而使得分类器 Gm(x) 在强分类器中起反作用。这也说明在二分类中每一个弱分类器的正确率必须大于0.5,比随机分类要好
更新样本权重为下一轮训练弱分类器做准备
wm+1,i={wmiZme−αm,Gm(xi)=yiwmiZmeαm,Gm(xi)≠yi有此可知,被弱分类器 Gm(x) 正确分类的样本的权重下降了,而被错误分类的样本的权重增加了,因此误分类样本在下一轮的学习中被更加重视了。当然,如果 αm<0 的话,正好起到相反的作用。不改变训练数据集,而不断改变训练数据的权值分布,使得训练数据在基本分类器的学习中起到不同的作用,这是Adaboost的一个特点。
步骤3,加权线性组合训练好的T个弱分类器,弱分类器系数 αm 表示基本分类器 Gm(x) 的重要性,但是这里 αm 的和并不为1。 f(x) 的符号决定实例x的类, f(x) 的绝对值表示分类的确信度。利用基本分类器的加权线性组合构建最终的强分类器是Adaboost的另一个特点。
Adaboost二分类算法的推导过程
Adaboost是多个弱分类器加权线性组合的结果。不改变训练数据集,而不断改变训练数据的权值分布,利用不同的加权数据集训练弱分类器,最后将弱分类器加权线性组合。上一节中的算法步骤中展示具体的计算过程,但是其中的公式仅仅是魔法公式吗?这些公式可以从Adaboost的模型、目标损失函数和学习算法中推导出来。
Adaboost算法是模型为加法模型,目标损失函数是指数函数,学习算法为前向分步算法时的二分类学习方法。
- 加法模型: f(x)=∑Tm=1αmGm(x) ,最终的强分类器是若干个弱分类器的线性加权平均得到的
- 指数损失函数:标准形式为 L(y,f(x))=exp(−yf(x))
- 前向分步算法:求解优化问题的思想是,因为学习的是加法模型,如果能够从前向后,每一步只学习一个弱分类器和它的系数,逐步逼近优化目标函数,那么就可以简化优化的复杂度
将以上的模型,目标损失函数和学习算法结合起来,Adaboost算法的推到过程如下:
前向分步算法学习的是加法模型,最终的强分类器是若干个弱分类器的线性加权平均得到的,最终的分类器是
其中 Gm(x) 是弱分类器, αm 是弱分类器的系数。根据前向分步算法的思想,逐一学习弱分类器 Gm(x),m=1,2,...,T 。假设经过m-1轮的学习,前m-1个弱分类器及其系数已经得到,而且有 fm−1(x)=∑m−1i=1αiGi(x) ,在第m轮迭代中有
我们的目标就是根据前行分步算法得到最优的 αm 和 Gm(x) ,使得 fm(x) 在训练数据集上的指数损失最小,即目标损失函数为
其中 w¯mi=exp(−yifm−1(x)) ,因为 w¯mi 与 α,G 无关,所以和目标函数 的最小化也无关,但是和 fm−1(x) 有关,随着每一次的迭代而改变,可以看做是样本的权重,
现在的目标是使得上面的目标函数最小化,分为两步:
固定 αm ,求 G∗m(x) :由于 Gm(xi)∈{1,−1},yi∈{1,−1} ,对任意的 αm>0 ,(1)式可以写作
===∑i=1nw¯miexp(−yiαmGm(xi))∑yi=Gm(xi)w¯mie−αm+∑yi≠Gm(xi)w¯mieαm∑w¯mie−αmI{yi=Gm(xi)}+∑w¯mieαmI{yi≠Gm(xi)}(eαm−e−αm)∑i=1nw¯mi{yi≠Gm(xi)}+e−αm−−−−−−−(2)所以
G∗m(x)=argminG∑i=1nw¯mi{yi≠Gm(xi)}—–(3)这里的 Gm(x) 是adaboost算法中第m个弱分类器,因为它是第m轮前向分步算法中指使数目标函数最小的分类器。
固定 Gm(x) ,求 α∗m :将式(2)对 αm 求导,得到
(eαm+e−αm)∑i=1nw¯mi{yi≠Gm(xi)}−e−αm=0得到
α∗m=12ln1−emem—–(4)其中
em=∑i=1nw¯mi{yi≠Gm(xi)}——(5)这里 em 就是第m个弱分类器的学习误差率, αm 就是第m个弱分类器的权重系数,和之前算法步骤中的一致
指数目标函数优化之后,得到 fm(x)=fm−1(x)+αmGm(x) ,和 w¯mi=exp(−yifm−1(xi)) , αm,Gm(x) 分别如式(4)(3)所示,所以可得
这和Adaboost步骤2中的权值更新只相差一个归一化系数。其实这里的 w¯mi 有具体的定义,和真正的样本权重更新公式一致,而且在之前的公式中,充当的也是样本权重的作用,所以认为是样本权重。
以上是Adaboost分类算法的流程和推导过程,从流程上可以很直接的看出Adaboost是集成学习,将一些弱学习器串联学习,集成强学习器,其中的权重更新是Adaboost的一个特点,看似是魔法函数,但是从推导过程中可以看出,Adaboost是有严谨的模型、损失函数和学习算法的。Adaboost算法是模型为加法模型,目标损失函数是指数函数,学习算法为前向分步算法时的二分类学习方法。
Adaboost多分类
原始的Adaboost算法是针对二分类问题的,多分类问题采用的也是将其分解为多个二分类问题。而SAMMA和SAMMA.R算法不采用这种思路,只是二分类的推广,也是加法模型,指数损失函数和前向分步算法,而且每个弱分类器的正确率只要大于0.5即可。具体参考文献[1]。
SAMMA算法流程:
假设训练集是 T={(x1,y1),(x2,y2),...,(xn,yn)} ,训练集在第k个弱学习器上的样本权重是 [wk1,wk2,...,wkn],w1i=1n,i=1,2,...,n ,即第一个弱分类器的样本权重是自定义的, yi∈{1,2,...,K} ,K是类别个数
输入:训练数据集,弱学习算法和弱学习器个数T
输出:最终的强分类器 f(x)
初始化样本权重 D1=[w11,w12,...,w1n],w1i=1n,i=1,2,...,n
对 m=1,2,...,T
使用具有样本权重 Dm 的训练数据和弱学习器算法得到弱分类器m, Gm(x):x→{1,2,...,K}
计算 Gm(x) 在训练数据集上的学习误差率 em=P(Gm(x)≠y)=∑ni=1wmiI{Gm(xi)≠yi}
计算弱学习器的权重系数 αm=12ln1−emem+ln(K−1)
更新样本权重 Dm+1=[wm+1,1,wm+1,2,...,wm+1,n],wm+1,i=wm,iZmexp(−αmyiGm(xi)),i=1,2,...,n
其中 Zm 是归一化因子 Zm=∑ni=1wm,iexp(−αmyiGm(xi)) ,它使得 Dm+1 成为一个概率分布
构建T个弱分类器的线性组合 f(x)=∑Tm=1αmGm(x) ,得到最终的强分类器 G(x)=argmaxk∑Tm=1αmI{Gm(x)=k}
从中可以看出。SAMMA算法和Adaboost算法唯一的不同是步骤2中的第3步,计算弱学习器权重系数。最后的决策函数是一致的。
Adaboost回归
Adaboost的回归算法有很多,这里是R2算法。具体参考文献[2]
假设训练集是 T={(x1,y1),(x2,y2),...,(xn,yn)} ,
输入:训练数据集,弱学习算法和弱学习器个数T
输出:最终的强学习器 G(x)
初始化样本权重 D1=[w11,w12,...,w1n],w1i=1n,i=1,2,...,n
对 m=1,2,...,T
使用具有样本权重 Dm 的训练数据和弱学习器算法得到弱学习器m, Gm(x)
计算弱学习器在训练集上的最大误差 Em=max|yi−Gm(xi)|,i=1,2,...,n
计算每个样本的相对误差:
如果是线性误差: emi=|yi−Gm(xi)|Em
如果是平方误差: emi=|yi−Gm(xi)|2Em
如果是指数误差: emi=1−exp(−yi+Gm(xi)Em)
利用每个样本的相对误差,计算回归误差率 em=∑ni=1wmiemi
计算弱学习器的权重系数 αm=em1−em
更新样本权重 Dm+1=[wm+1,1,wm+1,2,...,wm+1,n],wm+1,i=wm,iZmα1−emm,i=1,2,...,n
其中 Zm 是归一化因子 Zm=∑ni=1wm,iα1−emm ,它使得 Dm+1 成为一个概率分布
构建T个弱学习器的线性组合 f(x)=∑Tm=1(ln1αm)Gm(x) 得到最终的强回归
Adaboost之sklearn
Adaboost的主要优点有:
- Adaboost作为分类器时,分类精度很高
- 在Adaboost的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活。
- 作为简单的二元分类器时,构造简单,结果可理解。
- 不容易发生过拟合
Adaboost的主要缺点有:
对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
scikit-learn中Adaboost类库比较直接,就是AdaBoostClassifier和AdaBoostRegressor两个,从名字就可以看出AdaBoostClassifier用于分类,AdaBoostRegressor用于回归。
AdaBoostClassifier使用了两种Adaboost分类算法的实现,SAMME和SAMME.R。而AdaBoostRegressor则使用了我们原理篇里讲到的Adaboost回归算法的实现,即Adaboost.R2。
当我们对Adaboost调参时,主要要对两部分内容进行调参,第一部分是对我们的Adaboost的框架进行调参, 第二部分是对我们选择的弱分类器进行调参。两者相辅相成。下面就对Adaboost的两个类:AdaBoostClassifier和AdaBoostRegressor从这两部分做一个介绍。
框架参数
| 参数 | AdaBoostClassifier | AdaBoostRegressor |
|---|---|---|
| base_estimator | 弱分类器。理论上可以使用任何分类器,一般使用决策树CART和神经网络MLP,默认是决策树,即DecisionTreeClassifier,分类器需要支持样本权重。另外,如果选择的算法是SAMME.R,则弱分类器需要支持概率预测,即学习器预测的方法除了predict还有predict_proba | 弱回归器。理论上可以使用任何回归方法,一般使用决策树CART和神经网络MLP,默认是决策树,即DecisionTreeRegressor,回归其需要支持样本权重。 |
| algorithm | 这个参数只有AdaBoostClassifier有。主要原因是sklearn实现了两种分类算法,SAMME和SAMME.R。默认使用SAMME.R,需要base_estimator中弱分类器支持概率预测。 | |
| loss | 这个参数只有AdaBoostRegressor有。如上一节所示,有三种损失函数可选,’linear’,’square’和’exponential’ | |
| n_estimators | 弱分类器的个数,太小,容易欠拟合,太大,容易过拟合,默认是50,需要交叉验证选择最佳的个数 | 弱分类器的个数,太小,容易欠拟合,太大,容易过拟合,默认是50,需要交叉验证选择最佳的个数 |
| learning_rate | 学习率 v ,相当于损失函数中的正则项, 0<v<1 ,常和上面的n_estimotors结合使用。太小,需要更多的弱学习器,太大,需要较少的弱学习器。默认是1 | 学习率 v ,相当于损失函数中的正则项, 0<v<1 ,常和上面的n_estimotors结合使用。太小,需要更多的弱学习器,太大,需要较少的弱学习器。默认是1 |
弱分类器参数:使用不同的弱学习器,需要不同的若学习其参数,可以参考各个学习器的参数设置,这里不再详述。
函数
| 函数 | AdaBoostClassifier | AdaBoostRegressor |
|---|---|---|
| fit(X,y[,sample_weight]) | 根据训练数据集X和训练标签y训练adaboost分类模型 | 根据训练数据集X和目标值y训练adaboost回归模型 |
| decision_function(X) | 计算数据集X的决策函数 sumTm=1αmGm(x) | 无 |
| predict(X) | 预测数据集X的类别标签 | 预测数据集X的目标值 |
| predict_log_proba(X) | 属于每个类别的岁数概率 | 无 |
| predict_proba(X) | 属于每个类别的概率 | 无 |
| score(X,y[,sample_weights]) | 根据给定的数据集X和其对应的标签计算分类正确率 | 计算预测目标和和真实值y的平方误差 |
属性
| 属性 | AdaBoostClassifier | AdaBoostRegressor |
|---|---|---|
| estimators_ | 每一个弱分类器,包括他们的参数 | |
| classes_ | 训练样本的类别向量 | 无 |
| n_classes_ | 训练样本的类别个数 | 无 |
| estimator_weights_ | 每一个弱分类器的权重系数 α 组成的向量 | |
| estimator_errors_ | 每个弱分类器的分类误差组成的向量 | |
| feature_importances_ | 每个特征的重要性 |
例子
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
#产生随机样本
X1, y1 = make_gaussian_quantiles(cov=2.0,n_samples=500, n_features=2,n_classes=2, random_state=1)
X2, y2 = make_gaussian_quantiles(mean=(3, 3), cov=1.5,n_samples=500, n_features=2, n_classes=2, random_state=1)
#将两组数据合成一组数据
X = np.concatenate((X1, X2))
y = np.concatenate((y1, - y2 + 1))
#训练AdaBoostClassifier,采用网格法验证最佳的参数
#弱分类器是决策树
#bdt=AdaBoostClassifier(DecisionTreeClassifier(),algorithm="SAMME"),n_estimators=100,learning_rate=0.5)
from sklearn.model_selection import GridSearchCV
grid=GridSearchCV(AdaBoostClassifier(DecisionTreeClassifier(),algorithm="SAMME"),
param_grid={"n_estimators":[10,100,200,500,1000],"learning_rate":[0.1,0.2,0.4,0.8,1]},cv=4)
grid.fit(X,y)
print("The best parameters are %s with a score of %0.2f"
% (grid.best_params_, grid.best_score_))boosting之GBDT
梯度提升树的全称是Gradient Boosting Decison Tree, 简称GBDT。Gradient Boosting和Decision Tree是两个独立的概念,因此应该分类来理解。
Gradient Boosting
首先是boosting,很好理解,前面也介绍过,意思是用一些弱学习器的组合来构造一个强学习器,而且各个弱学习器是串联的关系。因此,boosting不是一个具体的算法,而是一种概念。和这个概念相对应的是一次性构造一个强学习器,如SVM,logisticRegressor等。通常,通过线性组合来构造强学习器,即 f(x)=G0(x)+α1G1(x)+...+αTGT(x)
接下来是Gradient Boosting Modeling(GBM),梯度提升模型。已知boosting中需要构造弱学习器,那么如何构造弱学习器呢?GBM就是构造弱学习器的一种方法。同样,它不是一种具体的算法,而是一种概念。在理解GBM之前,先看一个经典的数值优化问题。
针对这个优化问题,有一个经典的算法是梯度下降,过程大致如下
- 给定一个初始点 x0
- 对 i=1,2,...,maxIter 有 xi=xi−1+αi−1∗gi−1 ,其中 gi−1=−∂f(x)∂x|x=xi−1
- 直到 |gi−1| 足够小,或者 |xi−xi−1| 足够小,或者达到迭代次数
以上梯度下降可以理解为:整个寻优的过程就是小步快跑的过程,都向函数下降最快的方向走一步。最优点可以表示为 x∗=x0+α1g1+...+αmaxItergmaxIter ,这和boosting中寻找强学习器的形式一致(而且这个形式和感知机优化问题中的对偶形式一样)。Gradient Boosting正是由此启发而来。构造强学习器 f(x) 也是一个寻优的过程,只不过我们寻找的不再是一个最优点,而是一个最优的函数。寻找最优的函数通常是通过一个损失函数来定义的,即:
其中 Loss(f(xi),yi) 是损失函数,是 f(xi) 的函数,表示泛函。形式(2)和形式(1)一致,可以通过梯度下降的方法优化构造弱分类器 Gi(x) 。每次迭代时, gi=−∂Loss∂G|G=Gi−1
这里有个小问题,一个函数对函数的求导不好解决,而且通常都无法通过上述公式直接求解。所以,需要采用一个近似的方法,把函数 Gi−1(x) 理解成在所有样本上的离散函数值,即:
这是一个n维向量,然后计算
表示损失函数对第i-1个弱学习器的第t个分量的偏导数,是一个函数对向量的求导,得到的是一个n维的梯度向量。
严格来说。 gi(xt) 只是表示 gi(x) 在有限个点上的值,不足以代表 gi(x) ,但是我们可以通过函数拟合的方法从 gi(xt),t=1,2,...n 中构造 gi(x) ,这样我们就通过近似的方法得到了函数对函数的导数。
因此根据经典优化问题的梯度下降算法,可以得到GBM的过程如下:
问题: minf(x)∑ni=1Loss(f(xi),yi)
- 选择一个起始函数 G0(x)
- 对i=1,2,…,T分别做如下迭代
- 计算离散梯度 Gi(xt)=−∂Loss(G(xt),yt)∂G(xt)|G(xt)=Gi−1(xt),t=1,2,...,n
- 对离散梯度 Gi(xt),t=1,2,...n 做函数拟合得到 Gi(x)
- 根据 minαiLoss(fi−1(x)+αiGi(x)) 得到最优的 α∗i
- 令 fi(x)=fi(x)+αiGi(x)
- 直到 |Gi(x)| 足够小或者达到迭代次数,算法结束
以上便是GBM的过程,其中还有一个问题没有解决,就是第2步第2条,如何对离散梯度 Gi(xt),t=1,2,...n 做函数拟合得到 Gi(x) 。拟合的方法有很多种,最常用的是决策树Decision Tree,用Decision Tree拟合的话,就得到了GBDT。当然也可以采用其他的拟合方法XYZ,那么得到的就是GBXYZ了。
Decision Tree
决策树的主要算法有ID3,C4.5和CART,分为分类树和回归树,其中只有CART回归树可以解决回归的问题。在GBDT中需要用决策树拟合数据,所以需要的是回归树,而不是分类树,即使在分类问题中。所以下面着重回忆CART回归树。
CART回归树只要有两个方面,建立树和预测。
建立回归树:对数据集,寻找最优的特征A和特征上的最优划分值s
minA,s[minc1∑xi∈D1(A,s)(yi−c1)2+minc2∑xi∈D2(A,s)(yi−c2)2]其中C1是D1的目标均值,C2是D2的目标均值。遍历特征和划分值,根据上式,计算均方误差,选择最好的特征A和划分值s,划分数据为D1和D2。回归树是一颗二叉树。
预测目标值:对数据 x ,利用建立好的回归树得到的预测值是 f(x)=∑Ji=1ciI{x∈Di} 。即x的预测值是其所属区域的目标均值C。
那么如何用回归树拟合 Gi(xt),t=1,2,...,n 呢?数据集和每个数据对应的 Gi(xt) 已知,相当给定了一个回归问题,然后选定最佳的特征和划分值构造回归树,回归树中的叶子节点分别为 D1,D2,...,DJ ,对应区域的均方值是 c1,c2,...,cJ ,所以拟合函数为 Gi(x)=∑Jt=1ct{x∈Dt} 。
这里有一个问题需要注意, Gi(x) 相当于boosting中的弱学习器,如果过拟合,必定会造成强学习器的过拟合,所以这里的回归树不能过拟合。
GBDT的一些理解
GBDT可以分为GB和DT两个独立的部分,下面给出GBDT的流程,对于分类和回归的算法框架是一样的,只是目标函数和回归树构造的细节不同。
问题: minf(x)∑ni=1Loss(f(xi),yi)
- 初始化弱学习器 G0(x)=argmin∑ni=1Loss(yi,c)
- 对i=1,2,…,T分别做如下迭代
- 计算离散梯度 Gi(xt)=−∂Loss(G(xt),yt)∂G(xt)|G(xt)=Gi−1(xt),t=1,2,...,n
- 利用回归树对 (xt,Gi(xt)) 拟合得到 Gi(x)=∑Jj=1cij{x∈Dij}
- 根据 minαiLoss(fi−1(x)+αiGi(x)) 得到最优的 αi
- 令 fi(x)=fi(x)+αiGi(x)
- 直到 |Gi(x)| 足够小或者达到迭代次数,算法结束,得到的强学习器为 f(x)=∑Ti=1αi∑Jj=1cijI{x∈Dij}
上面的算法中有一个地方没有明确,就是第2步第1条中的损失函数。常用的损失函数有:
回归:
平方差损失 Loss(f(x),y)=12(y−f(x))2 ,对应的负梯度为 y−f(x)
绝对损失 Loss(f(x),y)=|y−f(x)| ,对应的负梯度为 sign(y−f(x))
Huber损失,是平方差损失和绝对损失的折中,对于原理中心的异常点,采用绝对损失,而中心店附近的点采用平方差损失。这个界限一般用分位数点度量。
Loss(f(x),y)={12(y−f(x))2δ(|y−f(x)|−δ2)|y−f(x)|≤δ|y−f(x)|>δ对应的负梯度为:
{y−f(x)δsign(y−f(x))|y−f(x)|≤δ|y−f(x)|>δ分位数损失,表达式为
Loss(f(x),y)=∑y≥f(x)θ|y−f(x)|+∑y<f(x)(1−θ)|y−f(x)|对应的负梯度为:
{θθ−1y≥f(x)y<f(x)Huber损失和分位数损失主要是为了健壮回归,也就是减少异常点对损失函数的影响。
分类
指数损失函数: Loss(f(x),y)=exp(−yf(x)) ,对应的负梯度为 y∗exp(−yf(x))
对数损失函数,分为二元分类和多元分类
二元分类: Loss(f(x),y)=log(1+exp(−yf(x))) ,对应的负梯度为 y1+exp(yf(x))
多元分类: Loss(f(x),y)=−∑Kk=1yklogpk(x) ,其中如果 f(x) 属于第k类,则 yk=1,pk(x)=exp(fk(x))/∑Kl=1exp(fl(x)) 。对应的负梯度为 yil−pl(xi) ,表示样本i对应类别l的负梯度,公有K个负梯度向量,每个向量是n维的。
对于回归和分类,分别拿出一个损失函数讨论,而且这两个损失函数是最特别的两个。
平方差损失函数:按照GBDT算法中的第二步,首先计算每个样本关于损失函数的负梯度,得到 git=yt−fi(xt) ,这个形式刚好是目标值和前i次迭代得到的强分类器的差值。然后用回归树拟合 g