Python 爬取爱奇艺腾讯视频二十五万条数据分析为什么李诞不值得了?

作者 | 罗昭成
责编 | 唐小引
本文首发于 CSDN 微信(ID:CSDNnews)
在《Python 爬取爱奇艺 52432 条数据分析谁才是《奇葩说》的焦点人物?)》这篇文章中,我们从爱奇艺爬取了 5 万多条评论数据,并对一些关键数据进行了分析,由此总结出了一些明面上看不到的数据,并将其直观地展现了出来,数据分析的妙处即在于此。
最终,我们从《奇葩说》的词云图中得出了李诞是为焦点人物的结论。但有小伙伴留言说道:“李诞是焦点人物,但那都是在骂他的”,看到这个笔者突然意识到,说着“人间不值得”的李诞《吐槽大会》开始声名鹊起,一方面是入了娱乐圈已成明星,却也饱受非议,作为《吐槽大会》第三季和《奇葩说》第五季的关键人物,我们是不是可以进行情感分析,从数万条的用户评论里找出广大观众眼中的李诞,以及主打辩论的奇葩说和以“吐槽文化”为切入点的《吐槽大会》的异同之处?
一、如何进行情感分析?
文本情感分析,又称为意见挖掘、倾向性分析等。简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
奇葩说的评论信息表达了人们的各种情感色彩和情感倾向性,通过对他们进行分析来了解大从舆论的看法。
在这里,我们使用 “SnowNLP” 进行分词和情感分析。
二、奇葩说的情感分析数据
注:本文中使用的奇葩说数据是上篇文章爬取的数据,数据文件地址:https://github.com/Pinned/ICanIBBData/blob/master/deal_data.db
先来看一下《奇葩说》的整体情感分析得分数据:
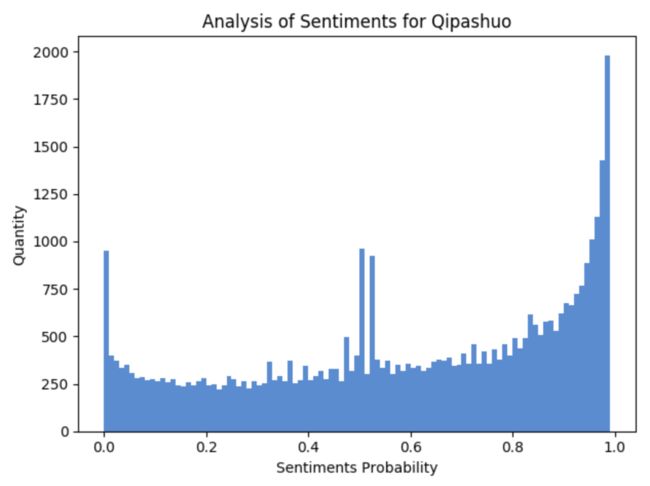
从上图可以看出来,正向情感的评论数要多于负向评论的数据,可见观众朋友还是喜欢奇葩说的。
好多人都说李诞是在被人骂,所以笔者在此对评论中包含李诞的数据进行了过滤(作者注:这样来看不一定准确,但也能从一个角度来看大体的数据情况),做了一下情感分析,先看图:
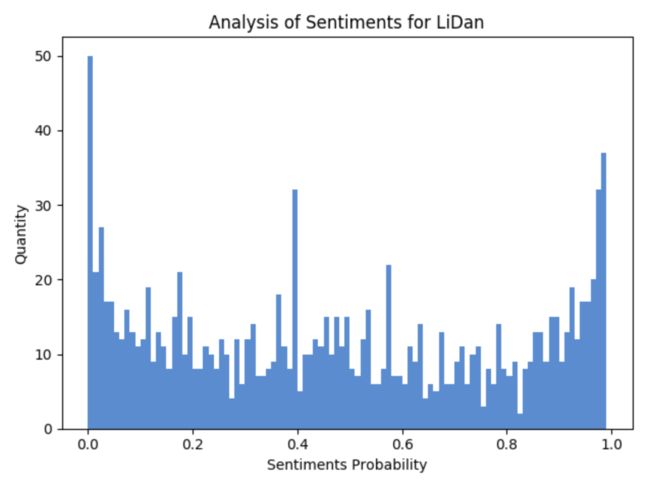
从这张图可以看出来,得分 0.5 以下的评论要比 0.5 分的多得多。其实单看李诞的这张图,对于负向情感评论是多是少没有直观的感受。于是,笔者又把剩下出现频率比较高的薛教授与詹青云的情感评分画了两张图,对比感受了一下:


通过这三张图的对比,感受到不一样的情感了吗?薛教授和詹青云的正向情感要远高于负向情感,而李诞的正向和负向两类情感则处于趋同状态。
详细代码为:
def emotionParser(title, *names):
conn = conn = sqlite3.connect("deal_data.db")
conn.text_factory = str
cursor = conn.cursor()
likeStr = ""
for i in range(0, len(names)):
likeStr = likeStr + " or content like \"%" + names[i] + "%\" "
if likeStr == "":
sql = "select content from realData where content != \"\" "
else:
sql = "select content from realData where content != \"\" " + likeStr
print sql
cursor.execute(sql)
values = cursor.fetchall()
sentimentslist = []
for item in values:
content = item[0]
senValue = SnowNLP(content.decode("utf-8")).sentiments
sentimentslist.append(senValue)
print content
plt.hist(sentimentslist, bins=np.arange(0, 1, 0.01), facecolor="#4F8CD6")
plt.xlabel("Sentiments Probability")
plt.ylabel("Quantity")
plt.title("Analysis of Sentiments for " + title)
plt.show()
cursor.close()
conn.close()
观众朋友对李诞的负面情感有些高,那对他的评论具体究竟呈现着什么样的态势?接下来我们按如下步骤进行具体分析:
- 将评论数据中包含李诞、李蛋、蛋蛋的数据单独查出来;
- 使用 Jieba 对评论数据分词;
- 使用 WordCloud 生成词云分析数据生成词云图见下图,有关代码请参考《Python 爬取爱奇艺 52432 条数据分析谁才是《奇葩说》的焦点人物?》 。
从上面的关键词中可以看出,观众对于李诞的情感词云偏于负面,譬如“讨厌”、“教养”、“礼貌”、“打断”等。
三、吐槽大会的情感分析
1. 爬取腾讯评论数据
用 Chrome 打开腾讯视频,打开 《吐槽大会》视频播放,然后打开 Chrome 查看源代码模式,在网络请求里面搜索并过滤 comment。通过过滤拿到的请求地址中,你能拿到一个 video_comment_id 的请求,里面有该期评论的 id。
本次笔者爬取了奇葩说的三季数据,每一期的评论数据的id都是手动去获取的?
2. 数据分析
从所获取的 18w+ 的评论数据中,包含李诞的数据条数有多少呢?直接使用 SQL 在数据库中查找:
select count(*) from dealInfoDatabase where content like "%李诞%" or content like "%李蛋%" or content like "%蛋蛋%" or content like "%诞总%";
![]()
没有想到的是,在这 18w 的数据中,居然只有 8000 多条数据。毕竟同样是每一期人员都非常多的综艺节目,在《奇葩说》5w 多条数据中就有 1w 多条与李诞相关,但结果到李诞成名的《吐槽大会》上却远远不足,值得我们思考。
回归正题,我们再来看一下,在每一期的评论数量:

在第一季第十期,也就是收官之作里关注度特别大,应该是有一次不错的表现。
3. 情感分析
首先来看一下,全部评论数据的整体情感分析,可以看到,整体的正向情感要多于负向情感。

再来看看所有评论中,评论词云是怎么分布的。如下图,可以看出,很多人都非常喜欢他。
再来看一下每一季的数据, 第一季的数据可以看出,正向情感要多于负向情感,更多的观众是喜欢他的。
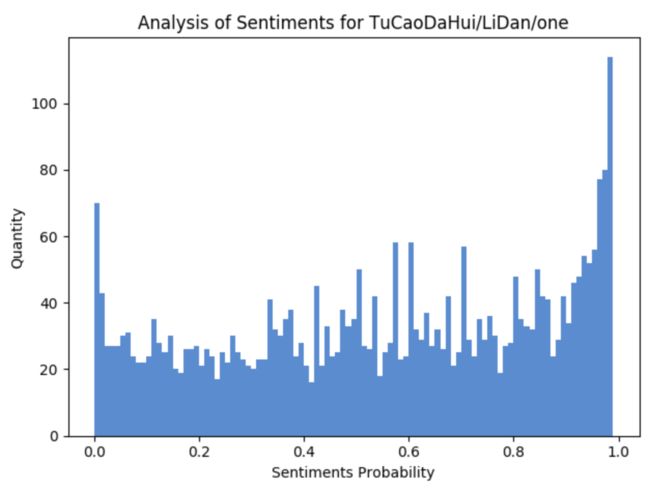
笔者也把第二季的数据跑出来,可以看出,正向情感与负向情感趋于持平,是不是表示,讨厌他的观众数量在增多呢?

最后,再来看一下,第三期的评论数据,从图中可以看出,负向情感要多于正向情感的数据。
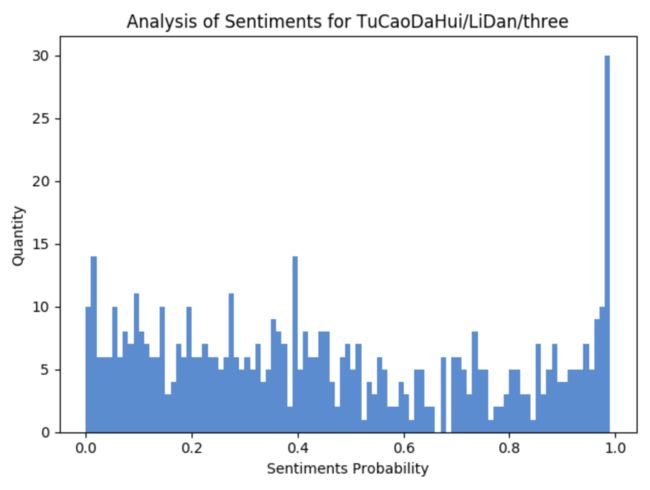
从上面的情感数据可以看出,《吐槽大会》从第一季到现在的第三季,不喜欢李诞的观众数量变得越来越多。
四、结语
在《吐槽大会》中,李诞要表现得更让观众喜欢,在《奇葩说》中,更多的观众是在骂它。虽然是一种不同的表现形式,至少说,他依旧是一个焦点人物,不论是好是坏,总归是留在了用户心中 —— 人间不值得。
五、传送门
欢迎关注我的公众号,一起交流技术事。
