在 IBM Lotus Notes 和 Domino 中编写快速查找代码
阅读在 IBM Lotus Notes 和 Domino 中编写快速查找代码的 11 个技巧。作者考察了 Lotus Notes 和 Domino 中的 @DbLookup @Formula 并描述了一些新技巧,供开发人员在编写新应用程序或对现有应用程序进行性能问题的故障检修时使用。
本文将考察 @DbLookup,它可能是 IBM Lotus Notes 和 Domino 中最流行的 @Formula。现在的 Lotus Notes/Domino 应用程序开发人员可能无法想像在不使用此公式的情况下创建应用程序,而超过 15 年的性能测试和客户故障检修已经表明:在应用程序的一个表单中,常常会以多种形式使用此公式数十次。
但是同样的经验表明:性能问题往往也与这些 @DbLookup 公式有关。我们已经看到,复杂的企业应用程序由于使用了这些公式,从而导致了无法接受的低性能而陷入实际的停顿。
本文将描述 11 个技巧,使用这些技巧能保证加快几乎任何应用程序的运行速度。这些技巧的范围广泛,包括从简单的一行代码到 @DbLookup 公式处理方法的根本性改变,但是所有这些技巧都已久经考验。
本文假设您具有 Lotus Notes/Domino 开发的一些知识,因此诸如 @DbLookup 公式的一些基本参数等内容,将不再赘述。
本文将使用各种示例说明每个技巧的价值。为简单起见,我们使用一个 Help Desk 应用程序,它包含一个 Contact 表单和一个 Ticket 表单。此应用程序的基本工作流程是:客户调用,创建 Ticket 文档,接下来,获得客户的公司和名称信息后从下拉列表中选择适当的公司名称和联系人名称。还要选择适当的调用类别(例如 Product Help、Sales 等等)。下面给出一些例子,在这几种情况下使用 @DbLookup 公式会将非常有用:
- 从一个包含所有公司的列表中选择公司名称
- 从一个包含该公司所有联系人的列表中选择客户名称
- 从一个预先确定的或动态的问题类别列表中选择问题类别
捕获错误
我们都不希望进行错误捕获,但是事与愿违。在 @DbLookup 公式中(本文中 @DbLookup 既指 @DbLookup 又指 @DbColumn 公式),错误往往更加难以处理,因为公式常常不仅取决于用户输入的键,还取决于其返回的数据。就是说公式可能在某一天能够工作,而在另一天就不能用了 —— 对开发人员来说这一直是个难题。
例如,假设公司名称在不同的 Contact 文档中有三四种不同的写法(比如 LSDevelopment Corporation 和 LS Development Corporation)。如果接下来要查找该公司的所有联系人名称,但是键入了 “LSDevelopment Company”(比方说),则找不到任何匹配的名称。
有多种方法可用于更精确的输入键(比如下拉列表),但是为了便于讨论,假设即使使用严格的开发技术,@DbLookup 也返回了一个错误。
错误检查的基本方法是编写如清单 1 所示的代码:
清单 1. 错误检查
v := @DbLookup(“Notes”; “”; “(Lookup-ContactsByCompany)”; CompanyName; “ContactName”); @If(@IsError(v); “The program cannot find any contacts for this company”; v) |
这段代码用于执行查找并检查错误条件。如果存在错误,则返回一个文本字符串,告诉用户存在一个问题;否则,则返回查找得到的值。
这虽然与性能无关,但却是很多应用程序都存在的一个基本问题,因此不能忽略。可将其看作一个附加的技巧。
  |
|
使查找频率最小化
考虑下面的查找公式代码:
@If(@IsError(@DbColumn(“Notes”; “”; “(Lookup-Companies)”; 1); “There are no
company names”; @DbColumn(“Notes”; “”; “(Lookup-Companies)”; 1))
这是一个很常见的错误,因为查找执行了两次,从性能角度来说这就是个问题。您可能认为第一个查找很好地缓存了查找结果,因此第二个查找就不会执行,但事实并非如此。第二个查找比第一个执行得快,因为后者(确实)缓存了查找结果,而前者原样执行。因为没有功能上的原因要求像那样编写公式代码,所以您应编写如下代码作为替代:
v := @DbColumn(“Notes”; “”; “(Lookup-Companies)”; 1);
@If(@IsError(v); “There are no company names”; v)
另一种导致执行不必要的查找的错误是:比如,一个 computed 字段在以下情形时计算查找公式:
- 第一次创建文档
- 按下各种按钮以编辑模式刷新文档
- 保存文档
- 在稍后的日期以读模式打开文档
- 在稍后的日期以编辑模式打开文档
- 在稍后的日期保存文档
最常见的是:希望只在第一次创建查找时执行查找。在这种情况下,将字段设置为 Computed When Composed 以防止再次计算。
在其他情况下,您可能希望每次以编辑模式打开文档时都执行查找。此时,按如下内容重写公式:
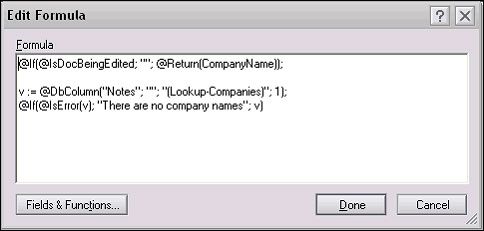
@If(@IsDocBeingEdited; “”; @Return(FieldName));
v := @DbColumn(“Notes”; “”; “(Lookup-Companies)”; 1);
@If(@IsError(v); “There are no company names”; v)
在这种情况下,FieldName 是此公式所在字段的名称。如果不是以编辑模式加载文档,则公式将只是保持该值并停止执行(参见图 1)。否则,将像以前一样执行 @DbColumn。
图 1. 关键字公式
|
|
正确地使用缓存
另一个常见错误是误解了 NoCache 参数的用法。通常,错误的推理是:认为数据越重要就越应该使用 NoCache。事实上,正确的思路应该是:执行查找的频率与数据变化的频率有关。
例如,如果要查找的数据的变化频率很低,比如,一个月变化一次,则很难想象查找公式中需要使用 NoCache。在示例中我们假设创建了一些供 Ticket 文档引用的类别。该列表可能由应用程序的所有者维护,每隔数月(也许是发布新产品或输入新公司时)才执行一次更新。
另一方面,假设 Ticket 文档查找发出调用的客户名称。如果此客户一小时内发出两次调用,则我们会因为在第二个 ticket 上的查找中得不到客户名称而非常不方便,这是由于名称列表被缓存在了前一个查找中。在此类应用程序中,我们常常会看见 Help Desk 职员整天开着数据库,因此当天将缓存的查找长时间缓存起来比较方便。
|
|
避开下拉列表陷阱
多年以来,表单中出现的所有严重的性能问题中,下拉列表显得尤为突出,有以下两个方面的原因:下拉列表通常查找大列表,下拉列表在读模式下也进行计算。
您可在自己的应用程序上执行一个简单的测试。以读模式打开一个其中的表单执行速度较慢的文档。打开文档时,仔细观察屏幕,找出其停顿的地方并做上标记。这执行起来可能不太容易处理,因为您只有一秒钟的操作时间,然后屏幕就跳转了,但是如果能找人帮忙的话,则可由其中一人调用字段标签,同时由另一个人记下这些标签。然后在 IBM Lotus Domino Designer 中打开表单并查看那些标记下的内容。最可能的情况是,您将发现标记所在之处是使用了 @DbLookup 公式的下拉列表。这是怎么回事?
以读模式打开文档时,将检验所有的 @DbLookup 公式。因为文档处于读模式下,所以并不会返回实际的检验值,但它们仍然会执行完该过程,而该过程很耗时。对于下拉列表,情况将更加糟糕,因为关键字字段由用户选择的值填充,以防该用户切换到编辑模式。您可能认为可以等到用户切换至编辑模式,然后让用户做出选择,但 Lotus Notes 中并不是这样运作的。有趣的是,Web 浏览器中下拉列表却正是像那样运作,即使在相同的表单上运行也是如此。
一个很好用的清理下拉列表的技巧是:将三种不同的特性结合使用以防止执行不必要的查找。这些特性操作起来都很容易,但您必须将三者结合使用。
首先,在下拉列表字段的公式中,使用以下公式:
@If(@IsDocBeingEdited; “”; @Return(FieldName));
v := @DbColumn(“Notes”; “”; “(Lookup-Companies)”; 1);
@If(@IsError(v); “There are no company names”; v)
这与 “使查找频率最小化” 中描述的内容相似,并且在文档处于读模式时它可防止关键字下拉列表执行查找。如果用户以编辑模式打开文档,则下拉列表当然会正常地计算。现在我们必须确保用户从读模式转换到编辑模式时将会计算查找。为此,将继续执行下面两个步骤。
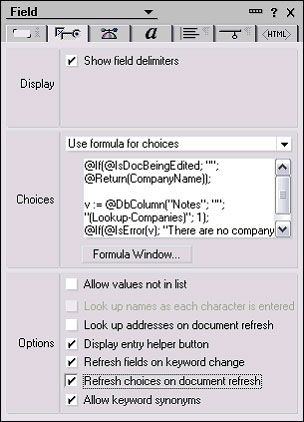
在下拉字段的属性中,启用 “Refresh choices on document refresh” 属性(参见图 2)。如果用户从读模式转换到编辑模式,则此属性可让关键字下拉公式在强制刷新文档时重新计算。
图 2. 下拉字段的属性
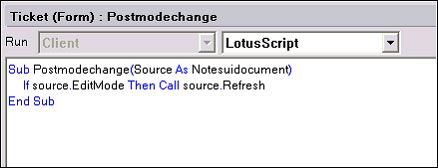
最后,在表单的 Postmodechange 事件中(参见图 3),包含以下代码,以便在用户从读模式转换到编辑模式时强制执行刷新:
If source.EditMode Then Call source.Refresh
图 3. Postmodechange 事件
|
|
使用按钮和选择列表代替下拉列表
在某些情况下,有很多很大且使用非常频繁的下拉列表,此时惟一合理的解决方案是:在主表单上停止使用这些下拉列表。正确的思路应该是思考以下问题:
- 文档在使用期限内会被读取多少次?
- 文档会被编辑多少次?
- 在文档的编辑次数中,需执行多少次这样的查找?
答案常常类似于:“文档通常被读取 10 次,但只被编辑一、两次。在这些编辑次数中,这些下拉列表只被使用一次。”当然,答案总是随所使用文档的不同而变化,但这些却是些值得思考的好问题。如果需要频繁地编辑文档,但很少需要执行查找,则前一部分将不能满足,因为每次用户处于编辑模式时下拉列表都将重新计算,即使这些列表实际只需使用不超过一次时也是如此。在这种情况下,可考虑使用按钮,可能需要与选择列表结合使用。
使用按钮的优点在于:可让您从字段中删除查找公式。字段将不再是一个下拉列表,而是成为了一个常规的文本字段,可能是 Computed when Composed 字段,带有 FieldName 公式(下面的例子中使用的是 ProblemCategory 公式)。为避免混淆将在读模式下隐藏按钮,但是在编辑模式下单击按钮时,它将使用清单 2 所示的公式:
清单 2. 按钮的公式
tlist := @DbColumn("Notes"; ""; "(Lookup-Categories)"; 1);
list := @Unique(@Explode(tlist; "~"));
@If(@IsError(list); @Return(@Prompt([Ok]; "Error"; "The program was unable to lookup the
Problem Categories.")); "");
dv := @If(ProblemCategory = ""; @Subset(list; 1); ProblemCategory);
v := @Prompt([OkCancelListMult]; "Problem Category"; "Choose one or more problem
categories for this ticket."; dv; list);
FIELD ProblemCategory := v;
|
通过使用 @Picklist 而不是 @Prompt 和 @DbLookup,可进一步使性能流线化。其缺点在于会减少对弹出窗口布局和底层数据的控制。例如,查看清单 3 所示的代码。
清单 3. 使用 @Picklist
v := @PickList( [CUSTOM] ; “” ; “(Lookup-Categories)” ; “Problem Category” ; “Choose one or more categories from the list.” ; 1 ) result := @If(@IsError(v); “The program was unable to lookup the Problem Categories”; v); FIELD ProblemCategory := result; |
|
|
使用布局区域(或弹出窗口)代替下拉列表
由于前一部分对查找的大小和频率进行了探讨,因此似乎已经找到了应用程序的正确处理方法,但是如果得不到所需的控制又该如何,答案是考虑使用对话框。可使用 @Formula 语言或 LotusScript 弹出一个对话框,并且可在一个对话框中使用多个查找。当表单拥有多个相关的查找时,这常常是一个很好的解决方案。例如,当用户选择公司后,该用户接下来应得到一张该公司联系人的列表,也许还有一个下拉列表,包含了该联系人的开放 tickets 的主题行。在此情况下,您可能希望拥有一个按钮(如前一部分中那样),但是要和清单 4 所示的代码结合使用。
清单 4. 使用对话框
Dim w as NotesUIWorkspace flag = w.DialogBox ( "(Dialog-CompanyLookup)", True, True, False, True, False, False, "Company Name", doc, False, False, False ) |
这里不会对每个参数做详细介绍,但清单 5 显示了开发者帮助参考。
清单 5. 帮助参考
flag = notesUIWorkspace.DialogBox( form$ , [autoHorzFit] , [autoVertFit] , [noCancel] , [noNewFields] , [noFieldUpdate] , [readOnly] , [title$] , [notesDocument] , [sizeToTable] , [noOkCancel] , [okCancelAtBottom] ) |
在 Dialog-CompanyLookup 表单中,现在可插入布局区域并放入所有的下拉字段,而不用考虑 @IsDocBeingEdited。用户单击按钮,弹出对话框时需要等待执行这些查找。
使用对话框的另外几点想法:
- 有时候创建一个临时的 Notes 文档会很有帮助,您不用保存该文档,但它可作为先前代码示例中的 [notesdocument] 参数。这让您能使用 LotusScript 执行更精细的查找,从而创建对话框中的列表。例如,也许您希望只引用最后三个月中联系过的公司。
- 在对话框表单中执行验证检查,因此直到验证完用户数据,用户才能回到主文档,这样处理可能比较方便。这可以减少用户必须返回到对话框的烦恼。
- 可添加图形、帮助文本和更多其他东西,使对话框比一个简单的下拉列表或 @Prompt 框更具吸引力且具有更多功能。
- 如果将应用程序移植到 Web 上,则可以很轻松地使用 JavaScript 弹出窗口替换对话框。布局区域本身不能在浏览器上显示,但是您可以使用 标记或表来模拟布局(标记是一种 HTML 代码,用于在页面上任何位置放置一段内容)。
- 最后,还可以使用嵌套的表和 [sizeToTable] 参数使其在 Notes 客户机中更具吸引力。此表单将更加易于移植到 Web 上。

回页首
使用 @Eval 清理代码
我们有时会看见大段的 @Formula 代码,里面充满了使用 @DbLookup 公式的 @If 语句。这些代码维护起来会很麻烦,而为避免不必要的查找以及执行适当的错误检查就更加困难(参见 “捕获错误” 部分)。使用 @Eval 可让您避免这类问题,如清单 6 所示。
清单 6. 使用 @Eval
companyLookup := {@DbColumn(“Notes”; “”; “(Lookup-Companies)”; 1);}; contactLookup := {@DbLookup(“Notes”; “”; “(Lookup-ContactsByCompany)”; CompanyName; “ContactName”);}; @If(someCondition = 1; @Eval(companyLookup); @Eval(contactLookup))
这段代码可防止在 @If 语句之前执行查找。换句话说,您可以提前设置所有的查找,给它们提供适当的变量名称,然后在需要时使用 @Eval 调用这些查找。
回页首
使用一个查找获取多个字段
如果您发现为获取不同的数据点要多次查找同一文档,则可考虑将该数据与查找视图中的一列连接起来。例如,假设我们需要从一个文档中获取下列数据点:
- ContactName
- ContactPhone
- ContactAddress1
- ContactAddress2
- ContactCity
- ContactState
- ContactZip
为此,我们可通过使用七个字段(每个字段都执行查找)来实现。ContactName 字段公式将类似于清单 7 所示的代码。
清单 7. ContactName 字段公式
v := @DbLookup(“Notes”; “”; “(Lookup-ContactsByCompany)”; CompanyName; “ContactName”); @If(@IsError(v); @Return(“The program could not locate that document.”); v);
而 ContactPhone 字段公式将类似于清单 8 所示的代码。
清单 8. ContactPhone 字段公式
v := @DbLookup(“Notes”; “”; “(Lookup-ContactsByCompany)”; CompanyName; “ ContactPhone”); @If(@IsError(v); @Return(“The program could not locate that document.”); v);
七个字段中的每一个都以此类推。
但是如果可以执行一个而不是七个查找的话,您就可获得更好的性能,即使假定在同一视图中对同一文档执行七个查找时也是如此。有一种方法可达到此目的:设置查找视图,使其包含具有清单 9 所示公式的另外一列。
清单 9. 设置查找视图使其包含另外一列
@If(ContactName = “”; “NA”; ContactName) + “~” + @If(ContactPhone = “”; “NA”; ContactPhone) + “~” + @If(ContactAddress1 = “”; “NA”; ContactAddress1) + “~” + @If(ContactAddress2 = “”; “NA”; ContactAddress2) + “~” + @If(ContactCity = “”; “NA”; ContactCity) + “~” + @If(ContactState = “”; “NA”; ContactState) + “~” + @If(ContactZip = “”; “NA”; ContactZip);
现在在表单中设置一个隐藏字段 —— 不妨称之为 BigLookup —— 并将清单 10 所示的公式放入 BigLookup 中:
清单 10. 查找 ContactsByCompany
v := @DbLookup(“Notes”; “”; “(Lookup-ContactsByCompany)”; CompanyName; 2); @If(@IsError(v); @Return(“The program could not locate that document.”); v);
现在对于 ContactName 字段,其公式可能如清单 11 所示。
清单 11. 查找 ContactName
tv := @Explode(BigLookup; “~”);
v := tv[1];
@If(@IsError(v); @Return(“The program could not locate that document.”); v = “NA”; “”; v);
而对于 ContactPhone,查看清单 12 所示的代码。
清单 12. 查找 ContactPhone
tv := @Explode(BigLookup; “~”);
v := tv[2];
@If(@IsError(v); @Return(“The program could not locate that document.”); v = “NA”; “”; v);
七个字段中的每一个都以此类推。
关于此技术的两点注意:
- 在视图列公式中我们将 “NA” 替代为 “”,如果不这样做的话,@Explode 会破坏所有的空白值并生成一个少于七个值的列表,这将会出现问题。
- 在每个字段公式中将 “” 替代为 “NA”,但错误消息的处理完全取决于您的判断。
回页首
制作更快的查找视图
任意种类查找视图的性能,不论使用的是 @Formula 语言还是 LotusScript,都取决于该视图的大小和运行速度。我们已经汇编了一些可用于优化查找视图性能的技巧。
制作专用的查找视图
在生产环境中索引(刷新)一个很典型的视图大约会花费 100 ms。也就是说,每 15 分钟服务器将花费不到十分之一秒的时间来更新每个查找视图。当然,这些时间是近似值,而且每个应用程序和服务器之间差别很大,但是对此数据的多年研究让我们相信:即使添加几个查找视图对性能的影响也不大。添加专用的查找视图可让您在用户等待查找完成时使视图性能流线化。
使视图设计流线化
如果视图只用于从某些文档查找数据,则可将以下内容从视图设计中消除:
- 所有有趣的字体和颜色。
- 所有的动作栏按钮。
- 视图事件中的任何 LotusScript 代码。
- 对 Profile 文档的任何引用。
- 无关的列。如果要从这些列返回数据,则保留该列;反之则消除该列。
- 视图列的多个排序选项。例如,如果用户从不访问视图,则无需对其按升序或降序排序;它所做的只是增加了视图的大小。
- 用于限制 @DbLookup 返回的选择列表的读者名称字段。这些字段对性能有很大的影响。
还可将类别转换成排序列,后者提供了相同的查找功能但可使视图更快地进行索引。
使数据流线化
除使设计最小化外,还可以考虑如何使视图中的数据最小化。下面有一些建议:
- 如果可以的话,尽可能地将数据归档。用于企业的设计考虑通常要胜过本文介绍的这些,但常常可将数据归档到另一个 Notes 数据库中,用户可在只读基础上访问该数据库(比如)。这样做可加快主数据库中的很多函数的运行速度,当然也限制了视图中的数据,使其运行得更快。
- 仔细地优化视图选择公式以便只显示实际需要的数据。
- 确保没有选择某些不显示但仍需包含到视图索引中的响应文档。选择公式 SELECT Form = “Main” | @IsResponseDoc 可能不经意地做到了这一点。反过来,使用 @DocDescendants 确保只包含显示的响应文档。
- 作为删除不必要数据的示例,我们看到了一些客户应用程序,其中的查找视图只需使用过去 30 天的数据,但数据库却必须将数据保存很长的时间,如两年。在该视图中使用时间敏感或日期敏感的公式显然不合适(太慢),但是使用周代理在文档中设置标记也许可行,使用该代理只标记那些已创建超过 30 天的文档。现在选择公式可以只引用该标记即可排除大量的文档,而不排除这些文档就会降低视图的运行速度。
- 消除任何没有用于查找的数据显示。
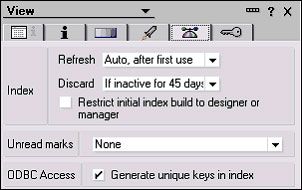
使用 “Generate unique keys in index” 消除重复条目
这是一个很好的技巧,可以极大地减小某些视图的大小。如果查找得到了大量的重复值,而这些值后来又被使用 @Unique(或等效的 LotusScript)消除,则可使用此特性。在这种情况下,启用 “Generate unique keys in index” 选项可使视图索引只显示找到的文本字符串的第一个实例(参见图 4)。
但是如果排序列引用了多值字段,则使用此选项时要格外小心。在这种情况下,如果 Domino 服务器是 6.x 版本,则可能要使用 @Implode(MultiValueField; “~”),然后让查找公式使用 @Unique(@Explode(@DbColumn(); “~”)) 以获取真实的惟一值集。如果使用的是 Lotus Domino 7,则没什么关系,因为服务器能智能地显示所有的惟一值。请注意:视图使用此特性时索引速度会稍慢一些,因为刷新视图时服务器可能要做比平时更多的工作。除非该特性能极大地减少视图中显示的文档数量,否则不要使用它。在很多应用程序中,使用此特性可使视图的大小减小到原来的 1/100,在这种情况下该特性可谓居功至伟。
图 4. View Properties 对话框
回页首
使用 Profile 文档
如果您拥有一些不是由多个用户更新且更新不频繁的列表,则检索这些值的一个快速方法是将其存储在 Profile 文档中。不管您是在 Profile 文档中手动更新列表,还是在常规文档中手动更新列表然后将其移植到 Profile 文档中,与缓存视图相比,用户都可更有效地缓存 Profile 文档,因此可以更快速地执行重复查找。
但是,如果用户正在更新列表,则使用 Profile 文档可能就不适当了,因为多个更新之间可能相互重写,然后导致复制/保存冲突。
回页首
使用查找数据库
大型应用程序常常可使用单独的查找数据库,可能是依据以下理论:要查找的数据非常多,因此从主数据库中获取数据和所需的视图比较方便。虽然这种说法具有一定的概念逻辑,但在现实中这样做往往会得不偿失。下面是一些技巧,可用于确定什么时候将查找数据存放在单独的数据库中,以及什么时候将数据存放在主数据库中更合适:
- 如果多个应用程序访问相同的列表,则使用单独的数据库存放这些列表比较合适。
- 如果要查找大量的数据并且这些数据需要使用多个表单,则从主用户数据库中获取数据比较合适。
- 另一方面,如果查找数据使用单个表单,并且只有几百个文档,则对主数据库的影响几乎可以忽略不计。基于维护和性能上的优点,因此在这种情况下我们鼓励您将查找保存在主数据库中。
所有这些情况中有一个例外就是,可能某些时候性能非常重要并且多个数据库访问几个简短的列表。在这种情况下,可能需要将这些列表保存在单独的查找数据库中,但是又通过 LotusScript 代理(或 Lotus Enterprise Integrator)将其移植到每个主数据库中。这样维护起来可能有些麻烦,但是可得到最好的性能。
回页首
结束语
我们希望这些技巧能在您编写下一个应用程序或对现有应用程序中的性能问题进行故障检修时为您提供一些可用的新工具。动态查找是大多数应用程序中的一个重要部分,因此,使用它们以使其性能影响最小化是确保拥有可顺利运行多年的高质量程序的最佳方法。