Flink1.10实战:两种分流器Spilt-Select和Side-Outputs
微信公众号:大数据开发运维架构
关注可了解更多大数据相关的资讯。问题或建议,请公众号留言;
如果您觉得“大数据开发运维架构”对你有帮助,欢迎转发朋友圈
从微信公众号拷贝过来,格式有些错乱,建议直接去公众号阅读
一、概述
Flink两种分流器Split和Side-Outputs,新版本中Split分流接口已经被置为“deprecated”,Split只可以进行一级分流,不能进行二级分流,Flink新版本推荐使用Side-Outputs分流器,它支持多级分流。
二、分流器使用
我这里有一份演示数据,里面是人的一些籍贯信息,每条数据有5个字段,分别代表:姓名、所在省份、所在城市、年龄、身份证号码,这里一级分流主要是将不同省份的人进行分流、二级分流在一级分流的基础上对各个省份的人进行城市分流,这里先给大家画一个分流流程图:
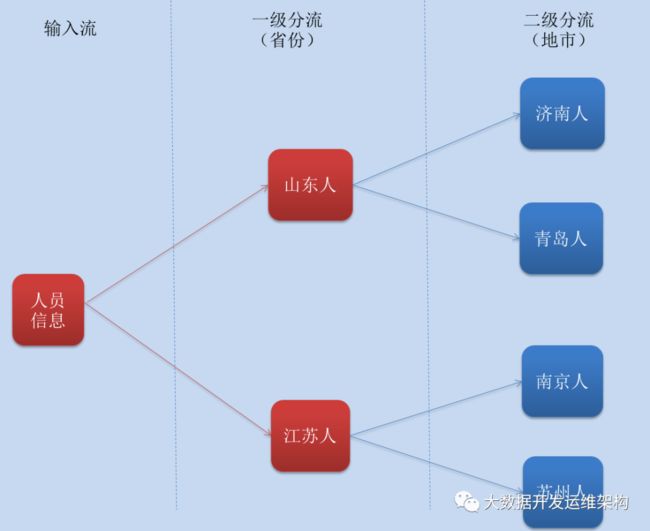
1.数据准备,人员信息
lujisen1,shandong,jinan,18,370102198606431256lujisen2,jiangsu,nanjing,19,330102198606431256lujisen3,shandong,qingdao,20,370103198606431256lujisen4,jiangsu,suzhou,21,330104198606431256
2.定义一个人员信息类PersonInfo,代码如下:
package com.hadoop.ljs.flink110.split;
/**
* @author: Created By lujisen
* @company ChinaUnicom Software JiNan
* @date: 2020-04-05 09:20
* @version: v1.0
* @description: com.hadoop.ljs.flink110.split
*/
public class PersonInfo {
String name;
String province;
String city;
int age;
String idCard;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getIdCard() {
return idCard;
}
public void setIdCard(String idCard) {
this.idCard = idCard;
}
public String toString(){
return "name:"+name +" province:"+province+" city:"+city+" age:"+age+" idCard"+idCard;
}
}3.先用Split进行一级分流,代码如下:
package com.hadoop.ljs.flink110.split;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.List;
/**
* @author: Created By lujisen
* @company ChinaUnicom Software JiNan
* @date: 2020-04-05 09:14
* @version: v1.0
* @description: com.hadoop.ljs.flink110
*/
public class SplitSelectTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
/*为方便测试 这里把并行度设置为1*/
senv.setParallelism(1);
DataStream sourceData = senv.readTextFile("D:\\projectData\\sideOutputTest.txt");
DataStream personStream = sourceData.map(new MapFunction() {
@Override
public PersonInfo map(String s) throws Exception {
String[] lines = s.split(",");
PersonInfo personInfo = new PersonInfo();
personInfo.setName(lines[0]);
personInfo.setProvince(lines[1]);
personInfo.setCity(lines[2]);
personInfo.setAge(Integer.valueOf(lines[3]));
personInfo.setIdCard(lines[4]);
return personInfo;
}
});
//这里是用spilt-slect进行一级分流
SplitStream splitProvinceStream = personStream.split(new OutputSelector() {
@Override
public Iterable select(PersonInfo personInfo) {
List split = new ArrayList<>();
if ("shandong".equals(personInfo.getProvince())) {
split.add("shandong");
} else if ("jiangsu".equals(personInfo.getProvince())) {
split.add("jiangsu");
}
return split;
}
});
DataStream shandong = splitProvinceStream.select("shandong");
DataStream jiangsu = splitProvinceStream.select("jiangsu");
/*一级分流结果*/
shandong.map(new MapFunction() {
@Override
public String map(PersonInfo personInfo) throws Exception {
return personInfo.toString();
}
}).print("山东分流结果:");
/*一级分流结果*/
jiangsu.map(new MapFunction() {
@Override
public String map(PersonInfo personInfo) throws Exception {
return personInfo.toString();
}
}).print("江苏分流结果: ");
senv.execute();
}
}
分流结果输出:

4.这里如果我们用Split对分流后的山东人进行二级分流,代码如下:
package com.hadoop.ljs.flink110.split;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.List;
/**
* @author: Created By lujisen
* @company ChinaUnicom Software JiNan
* @date: 2020-04-05 09:14
* @version: v1.0
* @description: com.hadoop.ljs.flink110
*/
public class SplitSelectTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
/*为方便测试 这里把并行度设置为1*/
senv.setParallelism(1);
DataStream sourceData = senv.readTextFile("D:\\projectData\\sideOutputTest.txt");
DataStream personStream = sourceData.map(new MapFunction() {
@Override
public PersonInfo map(String s) throws Exception {
String[] lines = s.split(",");
PersonInfo personInfo = new PersonInfo();
personInfo.setName(lines[0]);
personInfo.setProvince(lines[1]);
personInfo.setCity(lines[2]);
personInfo.setAge(Integer.valueOf(lines[3]));
personInfo.setIdCard(lines[4]);
return personInfo;
}
});
SplitStream splitProvinceStream = personStream.split(new OutputSelector() {
@Override
public Iterable select(PersonInfo personInfo) {
List split = new ArrayList<>();
if ("shandong".equals(personInfo.getProvince())) {
split.add("shandong");
} else if ("jiangsu".equals(personInfo.getProvince())) {
split.add("jiangsu");
}
return split;
}
});
//到这里一级分流没有问题
DataStream shandong = splitProvinceStream.select("shandong");
DataStream jiangsu = splitProvinceStream.select("jiangsu");
//下面就是二级分流,由于split不支持二级分流,这里会报错
SplitStream splitSDCityStream = shandong.split(new OutputSelector() {
@Override
public Iterable select(PersonInfo personInfo) {
List split = new ArrayList<>();
if ("jinan".equals(personInfo.getProvince())) {
split.add("jinan");
} else if ("qingdao".equals(personInfo.getProvince())) {
split.add("qingdao");
}
return split;
}
});
DataStream jinan = splitSDCityStream.select("jinan");
DataStream qingdao = splitSDCityStream.select("qingdao");
jinan.map(new MapFunction() {
@Override
public String map(PersonInfo personInfo) throws Exception {
return personInfo.toString();
}
}).print("山东-济南二级分流结果:");
qingdao.map(new MapFunction() {
@Override
public String map(PersonInfo personInfo) throws Exception {
return personInfo.toString();
}
}).print("山东-青岛二级分流结果:");
senv.execute();
}
}
这里用Split进行二级分流会报错,报错信息如下,建议用side-outputs进行分流:
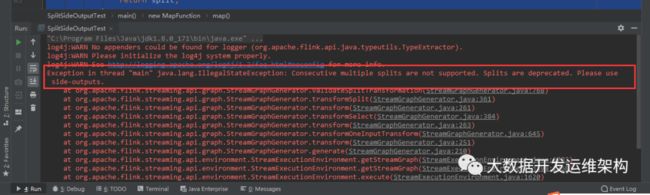
5.鉴于Spilt不能进行二级分流,我们用Side-Outputs进行二级分流,代码如下:
package com.hadoop.ljs.flink110.split;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.ArrayList;
import java.util.List;
/**
* @author: Created By lujisen
* @company ChinaUnicom Software JiNan
* @date: 2020-04-05 09:14
* @version: v1.0
* @description: com.hadoop.ljs.flink110
*/
public class SideOutputTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
/*为方便测试 这里把并行度设置为1*/
senv.setParallelism(1);
DataStream sourceData = senv.readTextFile("D:\\projectData\\sideOutputTest.txt");
DataStream personStream = sourceData.map(new MapFunction() {
@Override
public PersonInfo map(String s) throws Exception {
String[] lines = s.split(",");
PersonInfo personInfo = new PersonInfo();
personInfo.setName(lines[0]);
personInfo.setProvince(lines[1]);
personInfo.setCity(lines[2]);
personInfo.setAge(Integer.valueOf(lines[3]));
personInfo.setIdCard(lines[4]);
return personInfo;
}
});
//定义流分类标识 进行一级分流
OutputTag shandongTag = new OutputTag("shandong") {};
OutputTag jiangsuTag = new OutputTag("jiangsu") {};
SingleOutputStreamOperator splitProvinceStream = personStream.process(new ProcessFunction() {
@Override
public void processElement(PersonInfo person, Context context, Collector collector)
throws Exception {
if ("shandong".equals(person.getProvince())) {
context.output(shandongTag, person);
} else if ("jiangsu".equals(person.getProvince())) {
context.output(jiangsuTag, person);
}
}
});
DataStream shandongStream = splitProvinceStream.getSideOutput(shandongTag);
DataStream jiangsuStream = splitProvinceStream.getSideOutput(jiangsuTag);
/*下面对数据进行二级分流,我这里只对山东的这个数据流进行二级分流,江苏流程也一样*/
OutputTag jinanTag = new OutputTag("jinan") {};
OutputTag qingdaoTag = new OutputTag("qingdao") {};
SingleOutputStreamOperator cityStream = shandongStream.process(new ProcessFunction() {
@Override
public void processElement(PersonInfo person, Context context, Collector collector)
throws Exception {
if ("jinan".equals(person.getCity())) {
context.output(jinanTag, person);
} else if ("qingdao".equals(person.getCity())) {
context.output(qingdaoTag, person);
}
}
});
DataStream jinan = cityStream.getSideOutput(jinanTag);
DataStream qingdao = cityStream.getSideOutput(qingdaoTag);
jinan.map(new MapFunction() {
@Override
public String map(PersonInfo personInfo) throws Exception {
return personInfo.toString();
}
}).print("山东-济南二级分流结果:");
qingdao.map(new MapFunction() {
@Override
public String map(PersonInfo personInfo) throws Exception {
return personInfo.toString();
}
}).print("山东-青岛二级分流结果:");
senv.execute();
}
}
分流结果如下图所示:
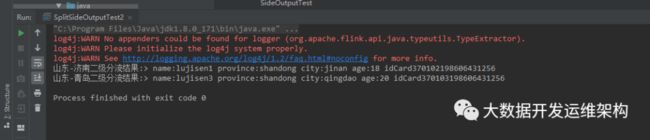
至此,分流演示完毕,我们知道Split-Select只能进行一级分流,二Side-Ouputs可以进行二级及以上分流,这里多级分流我就不再演示,道理是一样的,平时我们也经常用Fliter进行分流,那个比较简单,有空自己实操下就行,感谢关注!!!
如果觉得我的文章能帮到您,请关注微信公众号“大数据开发运维架构”,并转发朋友圈,谢谢支持!!!
