爬取分析—去哪儿景点热度
本文主要采用selenium(PhantomJS)模拟浏览器分析爬取去哪儿的国内所有省份10000多个景点信息,并保存在MongoDB中提取分析景点热度、省份旅游热度、景点描述词云等。
代码已托管GitHub,luozhengszj/spider
确定爬取目标
去哪儿景点,目标站点为:http://piao.qunar.com/ticket/list.htm?keyword=广西®ion=&from=mps_search_suggest
。其中的月销量从一定程度上反映了该景点该月份的热度,并且由省份选取景点,也能一定程度上反映了该省份的旅游热度。
工具使用
本次爬取采用selenium(PhantomJS)模拟浏览器、MongoDB进行存储、数据可视化wordcloud和pyecharts。
爬取流程
- 分析URL
keyword=省份,点击第二页可发现url:http://piao.qunar.com/ticket/list.htm?keyword=广西®ion=&from=mps_search_suggest&page=2,可发现page=2为第二页,因此可构造url。
def search(KEY_WORD,page):
print('正在爬取'+KEY_WORD)
try:
data = {
'keyword': KEY_WORD,
'region':'',
'from': 'mps_search_suggest',
'page': page
}
queries = urlencode(data)
url = base_url+queries
brower.get(url)
get_tourist()
except TimeoutException:
return search(KEY_WORD,page)
- 解析网站元素
先上代码:
def get_tourist():
# 等待加载函数 http://phantomjs.org/api/
hot = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#order-by-popularity"))
)
hot.click()
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#search-list .sight_item"))
)
# 获取源网页
html = brower.page_source
doc = pq(html)
items = doc('#search-list .sight_item').items()
for item in items:
tourist = {
'name':item.find('.sight_item_caption .name').text(),
'level': item.find('.level').text().strip(),
'more_url':'http://piao.qunar.com'+item.find('.sight_item_about .sight_item_caption .name').attr('href').strip(),
'province':item.find('.area').text()[1:-1].strip().split('·')[0],
'city':item.find('.area').text()[1:-1].strip().split('·')[1],
'image':item.find('.loading a .img_opacity').attr('data-original'),
'describe': item.find('.intro').attr('title'),
'hot_num': item.find('.hot_num').text(),
'price': item.find('.sight_item_price').text()[1:-1].strip(),
}
print(tourist)
可以自行选择保存什么元素,例如获取描述元素的过程:
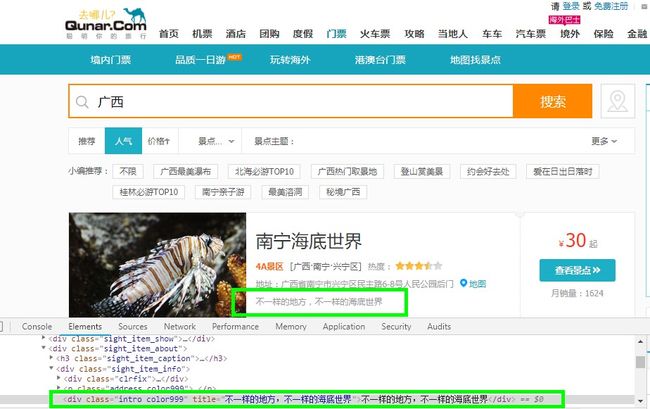
通过图片我们可以看到景点描述就在各自景点为:class=“sight_item sight_itempos” 下面的:class=“intro color999” 这个DIV下面的title属性,因此采用PyQuery也就是写为:
doc('#search-list .sight_item').items()[0]item.find('.intro').attr('title') # 第一个景点的描述信息
-
保存到MongDB
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
db[MONGO_TABLE].insert(result)
数据可视化
描述的词云代码(不清楚可直接留言):
def draw_word_cloud():
import re
import jieba
import numpy as np
from wordcloud import WordCloud, STOPWORDS
new_data = data.dropna(subset=['describe'])
json_data = new_data['describe'].tolist()
test_data = ''.join(json_data)
# 去掉非中文
pattern = '[^\u4e00-\u9fa5]*'
final_text = re.sub(pattern, '', test_data)
default_mode = jieba.cut(final_text)
text = ' '.join(default_mode)
# 设置背景图
alice_mask = np.array(Image.open(r'.\static\qq.jpg'))
stop_words = set(STOPWORDS)
# 设置字体
font_name = path.join(r'D:\develop\python\spider\SimHei.ttf')
# 过滤词
stop_words.add('delete_word')
wc = WordCloud(
# 设置字体,不指定就会出现乱码,这个字体文件需要下载
font_path=font_name,
background_color='white',
max_words=2000,
mask=alice_mask,
stopwords=stop_words)
# generate word cloud
wc.generate(text)
# store to file
wc.to_file('.\static\词云.jpg')
词云效果如图:

代码见gihub
去哪儿Github
个人博客:Loak 正 - 关注人工智能及互联网的个人博客
文章地址:爬取分析—去哪儿景点热度)