【傻瓜攻略】深度学习之从入门到放弃
从研究生进来之后,一直到现在已经进行了一年关于DP的学习,写篇文章总结一下我蹒跚的学习过程。总结来说是一个从入门学习到几乎想要放弃的过程。顺带列举下面几个坑,希望能帮助一下同样在这条路上行走的旅人们。
1、overfitting这个东西
很多刚刚进门的新人,包括刚刚做完一个项目的我,都会认为自己的神经网络效果不好可能是过拟合了。但是实际上过拟合这种事情听说的人多,看到的人很少。当你的激活函数是ReLu,你的优化器是Adam的时候,那就更少概率能碰到overfitting,如果你还有dropout层,那你的碰到的概率更少了。(ps,最近补课李宏毅老师的课得到的知识。)
碰到效果不好的时候,首先应该看看自己training set的效果怎么样,如果正确率很低,那就是没有train起来。这是该考虑的是你的神经网络架构的问题,以及你的优化器,还有学习速率这些。当然还有epoch 以及batch size的大小。
一般来说batch size越大,你的训练时间越少,但是你的神经网络误差会越大。所以batch size大小选择需谨慎。另外,初始的学习速率也不能过大。
但是,也有人会考虑到epoch过大,以及batch size过小,导致训练速度过慢怎么办?这个问题我也遇到过,我的建议是把你的GPU跑起来。
2、关于GPU
在断更的这段时间,我在做项目,跟深度学习有关。那个时候特别傻,一直用CPU在跑,还不敢问老师要个服务器(ps:当然也有不会用服务器的原因),这一跑就是三四天,甚至是一个星期。问题是,CPU跑这个东西,很容易电脑死机,特别是我这种老年机。可想而知,这结果就很悲惨了。特别是由于我这么个愚笨的人,对于神经网络学习了一年,还是不太精进,所以结果很悲惨。虽然,最终结果还是出来了,结果还不错。但是过程真的是悲惨。
等结束项目之后,我好好地看了一下我的电脑,以及我的配置架构。发现我并没有使用GPU!!!所以开始配置GPU了。
网上有很多博客说,python3.6,应该安装CUDAxx版本,CUDnnxx版本,不然就跑不了了。作为一个死倔强的人,其实是个很懒的人,我真的不想卸了我的CUDA和CUDnn重装。大家都懂的,NVIDIA这个坑爹的官网卡就算了,CUDA这类东西又大又有n个补丁,下的慢也就算了,还有各种环境变量要设置,设置完了还要重启,真的是去了半条命。python版本重装也是要人命。后来,在我的不懈努力下,我终于找到了一个博客,他提供了一个GitHub的连接。
这个连接中有对应各个环境的tensorflow,https://github.com/fo40225/tensorflow-windows-wheel,就是这个网站。
找到对应的版本下下来,然后放在你的python文件夹-->Lib->site-packpages 文件夹下,别的文件夹下我也试过,但是我安装后好像还是用不了,不知道是不是环境变量的原因。皮实的小朋友可以试试。
打开Anaconda prompt ,cd到这个文件夹,然后pip install tensoflowXXXXX,这个tensorflowXXX就是下载的那个文件。
找不到Anaconda prompt,可以在开始->Anaconda文件夹下找到。
安装好了之后,可以试试import tensorflow……,就是常用的那个代码。
安装tensorflow-gpu的孩子,可以试试,tf.test.is_built_with_cuda(),是否为Ture,
如果不是,则检查你的python文件夹-->Lib->site-packpages->tensorflow->python->platform->build_info.py 文件
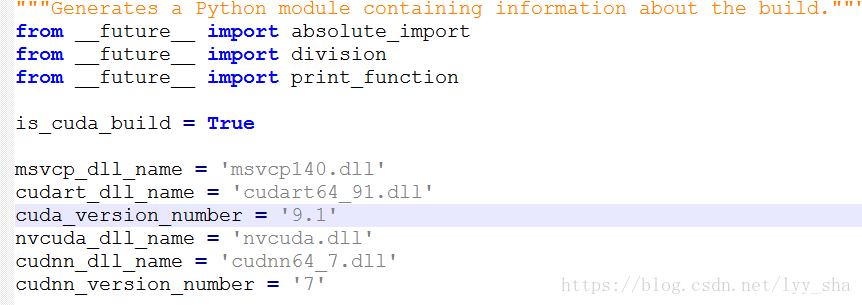
如图,这个文件写了你的tensorflow需要的CUDA 和CUDnn需要的版本。如果它跟你已经安装的版本不符,那说明你下错了。对了,GitHub中的AVX在i3之后的版本都有。
还有CUDA的版本查看是 nvcc -V,直接在cmd 命令敲进去就行
CUDnn版本,是在你的CUDA安装文件夹->include->cudnn.h
 如图就是,7.0.5版本。因为你当初安装cudnn的时候就是把文件放进cuda安装目录下安装的。
如图就是,7.0.5版本。因为你当初安装cudnn的时候就是把文件放进cuda安装目录下安装的。
一般正常的安装话,这个文件应该在
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\include
CUDnn版本的信息还是很难找到的。
最后,关于你是否使用了GPU,你可以写个代码,然后下载个GPU-Z软件进行查看。

这个GPU load就是你GPU的使用率。
最后强调一下我的环境配置,(叉腰,超牛逼)WIN7+CUDA9.1.85+Python3.6+CUDnn7.0.5+tensorflow-gpu 1.5
我也想用1.10版本,但是可惜我的cuda和python和cudnn版本决定了我只能用1.5,╮(╯▽╰)╭
3、关于学习的方法。
我一开始是看书的,但是,你们懂得,现在关于机器学习的书里面一堆的公式,一堆的概念,一堆概率论什么的,然后我就从入门到放弃了。
然后我开始通过网络搜索各种架构,一点一点搭建起来了DP的一些基本概念。要是形容来说的话,就类似于,我看到了一个绝世大帅哥的轮廓的感觉。你们可以通过看我以前的博客内容,这样就不需要走我以前的老路,一点一点搜集资料了。个人感觉,对于一个以前一点都没有接触过bp内容的人来说,这个基础内容的普及是相当重要的,这相当于让我看到了DP的门槛。
接着,我也尝试着写一写代码,却发觉无从下手。因为我根本不知道该怎么搭建网络。于是,我从网上开始下载各种例程,由于项目需要,我对于YOLO的框架看的格外仔细,虽然仍旧一知半解,只能说会移植知道怎么用,但是用的磕磕绊绊(从我一直用CPU跑完整个项目就能看出,我真的用的磕磕绊绊)但是这个还是有好处的。
YOLO这个东西坑就坑在这货在Ubuntu上面的资料一应俱全,各种帖子特多。但是在windows上就很少很少,只有一个github的工程YAD2K,这个工程关于文件的描述少之又少。所以导致了我在YOLO上研究了很长时间。当然也包括对于VOC的研究以及在Ubuntu上搭建环境什么的。Ubuntu上正版的YOLO我也跑了,叉腰,超牛逼。
总之磕磕绊绊,研究了两三个月。这段时间对于YOLO代码的研究,使得我大概了解了tensorflow以及keras的大概轮廓,以及神经网络的大体架构。
这个时候我回过头去听李宏毅老师的课,真的是受益匪浅。以前听的时候没什么感觉,但是现在去听,却能发觉当初走了很多弯路,而且当初对于YOLO代码的分析有很多的错误。
这个老师讲课真的很精辟,而且讲课风格很幽默,墙裂推荐去听听!!!!
但是我一点也不后悔当初走过的弯路,以及CPU训练代码训练了半天效果还是不好的那段即将放弃的艰苦日子。不走过这些弯路,对于李宏毅老师的课我不可能抓住重点而且没法理解的这么深。我的意思不是说走弯路,而且提倡跟我一样在学习dp的孩子们,在听老师讲实训课之前,最好拿个代码研究一下,这样对于课程的理解会有极大的好处。另外,推荐keras!!!
写的太多了,那么这里就结束了。